Unsupervised-Learning란?
- 정답이 없는 데이터가 주어질때 데이터 내에서 숨겨진 구조를 파악하는 비지도 학습
Clustering
Clustering이란?
- 각 개체의 패거리 정보(정답)없이 유사한 feature을 가진 개체끼리 군집화 하는것
cf)
인터넷 쇼핑몰 마케터라고 할때 고객별 구매 상품 개수 데이터를 활용하여 유사한 고객 집단으로 세분화 하고자 한다면?
-> 데이터: 고객별 구매 상품 개수 데이터
-> 유사한 특성을 지닌 고객을 동일한 그룹으로 그룹화
종류
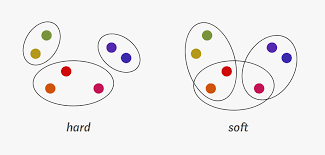
Hard Clustering
- 특정 개체가 집단에 포함되는지 여부 클러스터에 1과 0으로 표현(엄격!)
- K-means Clusetring 알고리즘
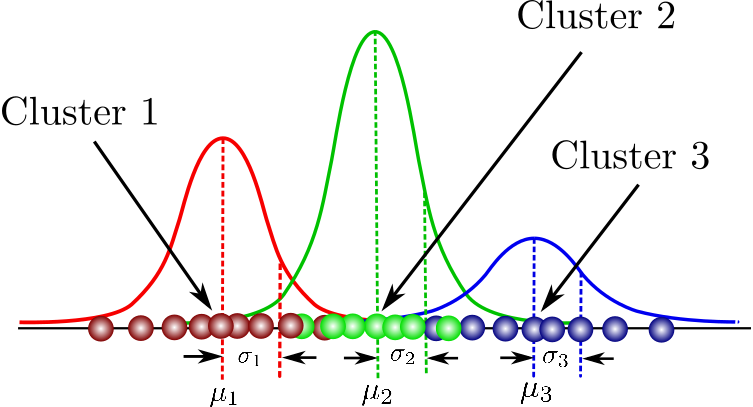
Soft Clustering
- 특정 개체 집단에 얼마나 포함되는지 정도 클러스터에 속하는 정도로 표현
- Gaussian Mixture Model 알고리즘이 이에 해당
목표
-
군집 간 유사성 최소화
-
군집 내 유사성 최대화
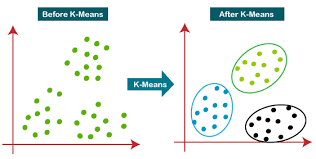
K-means Clustering
- 제공된 데이터를 k(hyper parameter)개로 군집화 하는 알고리즘
ex)
100만명 이상인 고객의 구매 상품 데이터를 활용하여 고객을 군집화 하고자 한다면?
(대용량 데이터) 군집화
원리
- 데이터셋 중 k개를 랜덤하게 뽑아 해당 데이터를 중심으로 함
- 모든 데이터에 대해서 각 클러스터의 중심과 자신(해당 데이터)을 비교하고, 가장 가까운 클러스터를 저장
- 모든 클러스터에 대해서 자신(해당 클러스터)에 할당된 데이터들의 중심을 계산하고, 계산된 중심을 새로운 중심으로 설정
-> 설정되는 중심의 변화가 없을때까지 2,3번 과정 반복
tip)
Elbow Method -> 최적 k구하기
- 다양한 k값을 시도해보면서 하이퍼파라미터 튜닝을 해보고 cost function의 그래프가 꺾이는 부분, 즉 클러스터 수를 증가시켜도 별 효과가 없는 지점의 k선택
특징 및 활용
- 랜덤 초기값 설정으로 인해 데이터의 분포가 독특한 경우 원하는 결과 나오지 않을 가능성
- 시간복잡도가 가벼워 많은 계산량이 필요한 대용량 데이터에 적합
- 실제 문제에 적용할 때는 여러번 클러스터링을 수행해 가장 빈번히 등장하는 군집에 할당
Dimensionality Reduction
- 대용량의 고차원 데이터를 저차원으로 줄이는 알고리즘
(엄청나게 많은 변수를 가지고 있는 고차원의 데이터에서는 차원의 저주가 발생할 가능성이 높아짐)
차원의 저주란?)
차원이 높을수록 학습에 요구되는 데이터의 개수도 증가함
-고차원일 때 적은 개수의 데이터로만 차원을 표현하는 경우 overfitting 발생가능
필요성
-차원의 저주 발생 방지와 모델 학습 속도 및 성능 향상을 위한 차원 축소 알고리즘
- 2차원 데이터를 1차원으로 차원 축소할 경우 여러갈래의 축을 확인해보며 각 점들과 축의 오차가 가장 작은 축을 중심으로 데이터를 모음
- t-SNE
출처
1. 내용참조: 2022 군장병 sw/ai 역량강화 프로젝트형 중급과정
2. hard clustering-soft clustering사진: https://towardsdatascience.com/a-friendly-introduction-to-text-clustering-fa996bcefd04?gi=50335bcd9439
3. k-means 사진:https://www.javatpoint.com/k-means-clustering-algorithm-in-machine-learning
4. gaussian mixture model 사진:https://towardsdatascience.com/gaussian-mixture-models-explained-6986aaf5a95
