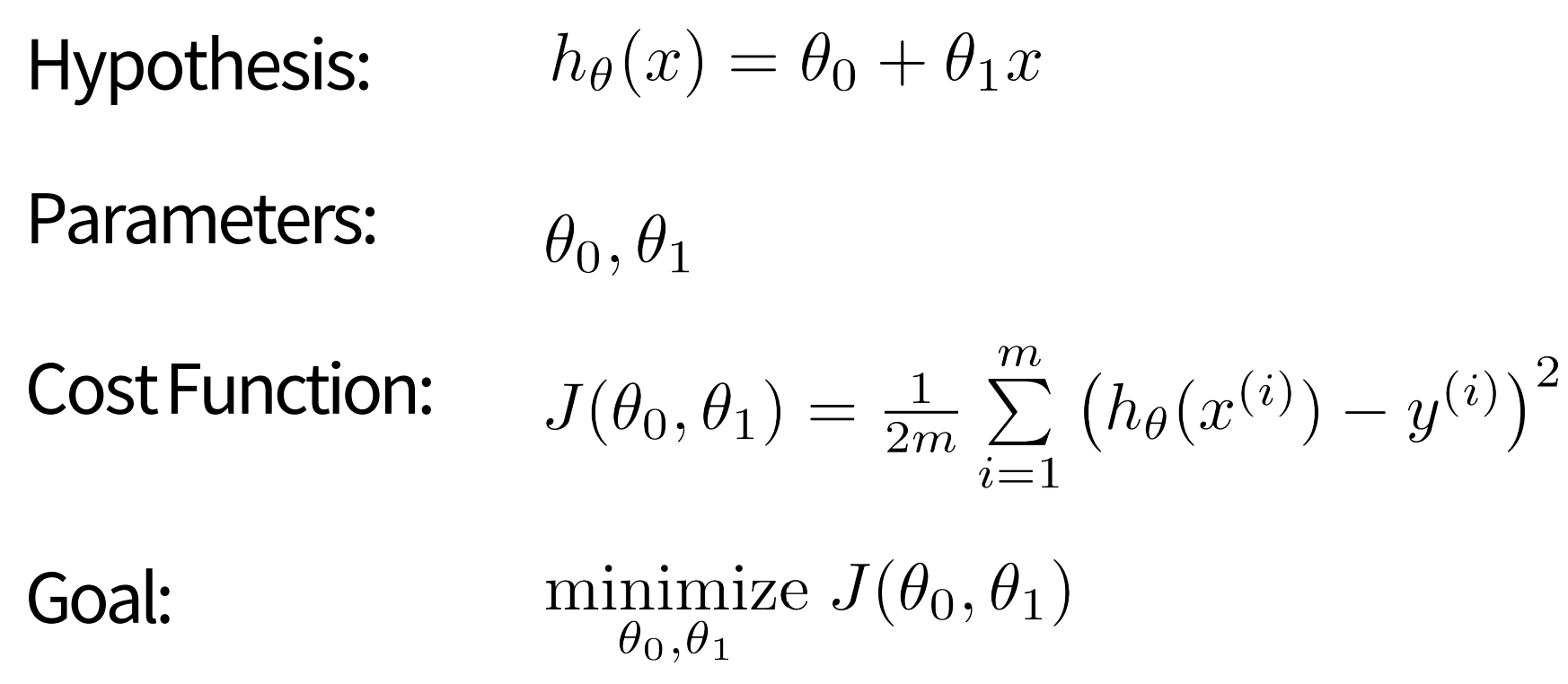Supervised Learning
- 입출력 쌍을 기반으로 input을 output에 매핑시키는 기계학습
- label된 training data에서 함수를 추론함
- regression : numerical value를 예측 (real number, continuous number)
- classification : discreate, categorical value를 예측
Unsupervised Learning
- label이 없는 data에서 추론(inference)를 끌어내는 기계학습
Linear regression with one variable
- 단순(simple) 선형 회귀 == 단일 설명 변수(simple explanatory variable)를 가진 경우
- model representation
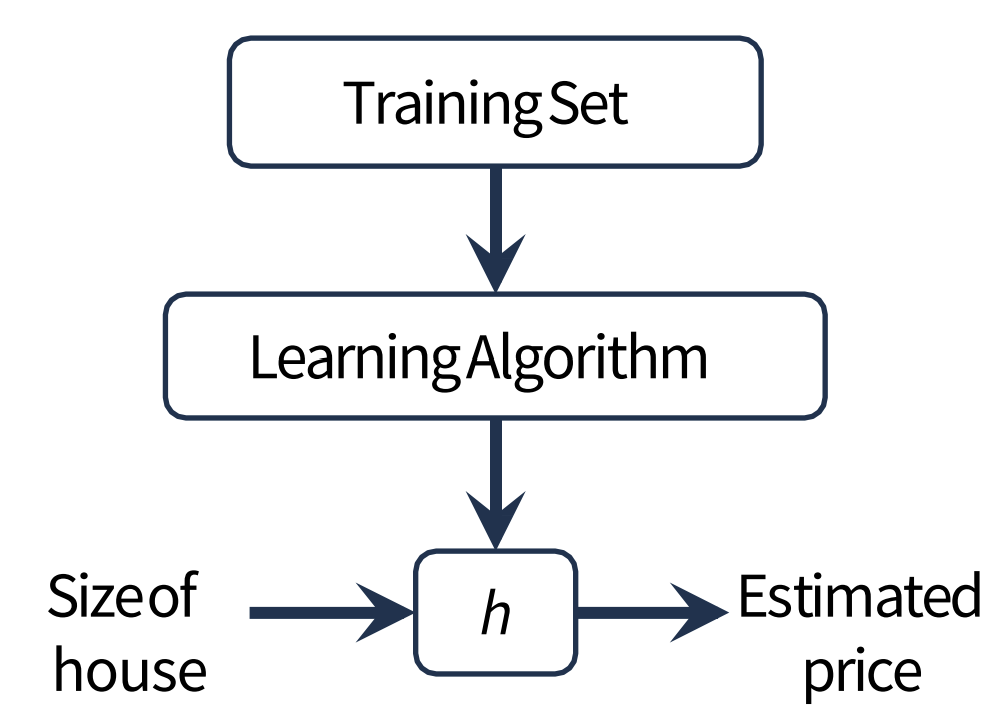
Numerical approach
- 목표: <x,y> training data 쌍들로 파라미터 w를 추정하는 것
- 최적화 목표: squared error == least square 최소화하는 것
=> squared error : (label의 값 - 예측한 값)의 제곱의 합
Why? : label의 값과 예측한 값을 최소화할 수 있음, 특정 outlier들이 많이 무시될 수 있음
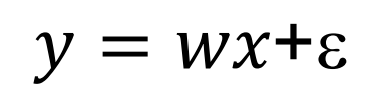
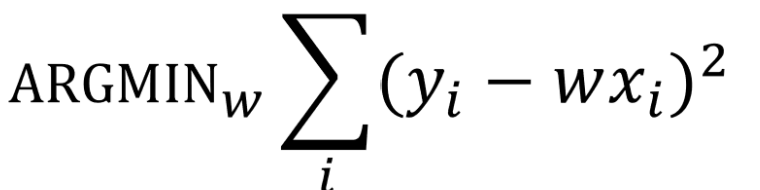
최적화를 위해, w대한 미분 필요
- 실제 w를 이용해서 line 만들기
- 생성된 w에 표준편차(STD) (==noise)를 줘서 line 만들기
- 이 두 line을 비교하면 모델이 얼마나 잘 학습되었는지 알 수 있음
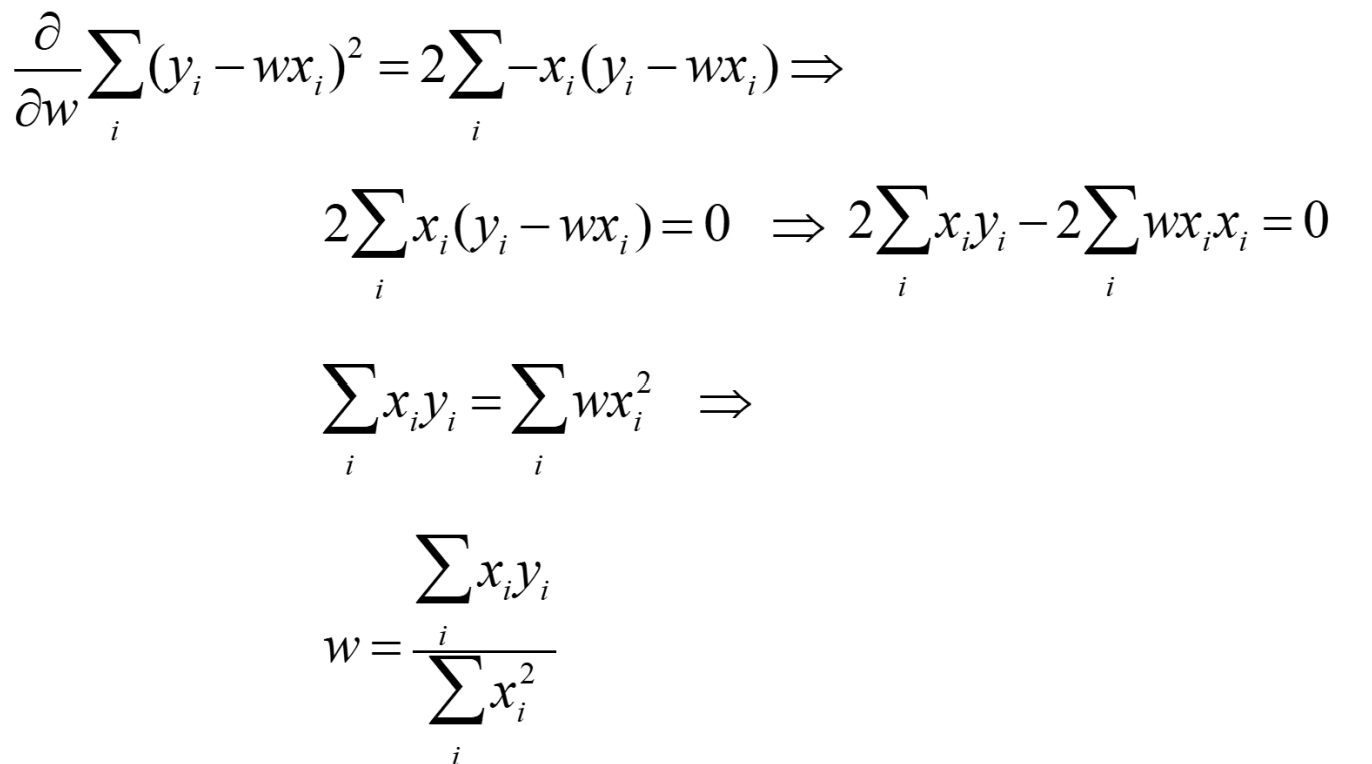
ML approach
- cost function(J(세타))를 정의 -> 평균 제곱 오차 (squared error)
- 목표: 비용함수를 최소화시키는 것
Q. 여기서 왜 2m?
1/m은 data의 평균 구하기 위해, 2는 계산을 간소화하기 위한 상수로 나중에 경사하강법에서 미분할때 계산이 깔끔하게 떨어지게 해줌