👽ML
1.[ML] Linear Regression with One Variable
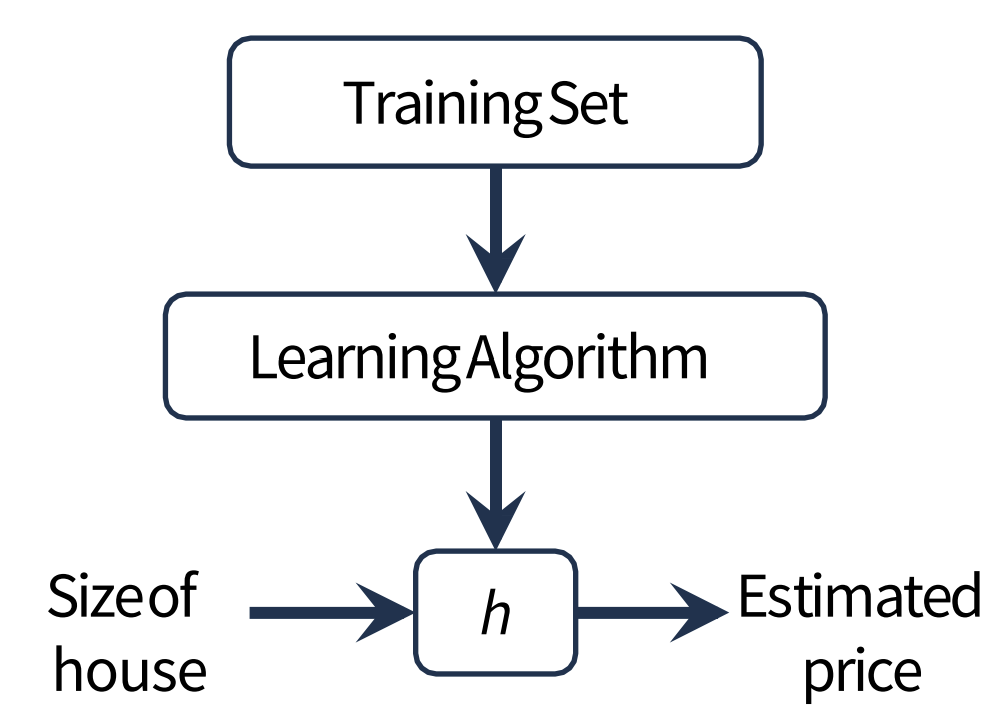
입출력 쌍을 기반으로 input을 output에 매핑시키는 기계학습label된 training data에서 함수를 추론함regression : numerical value를 예측 (real number, continuous number)classification :
2.[ML] Linear Regression with Multiple Variables
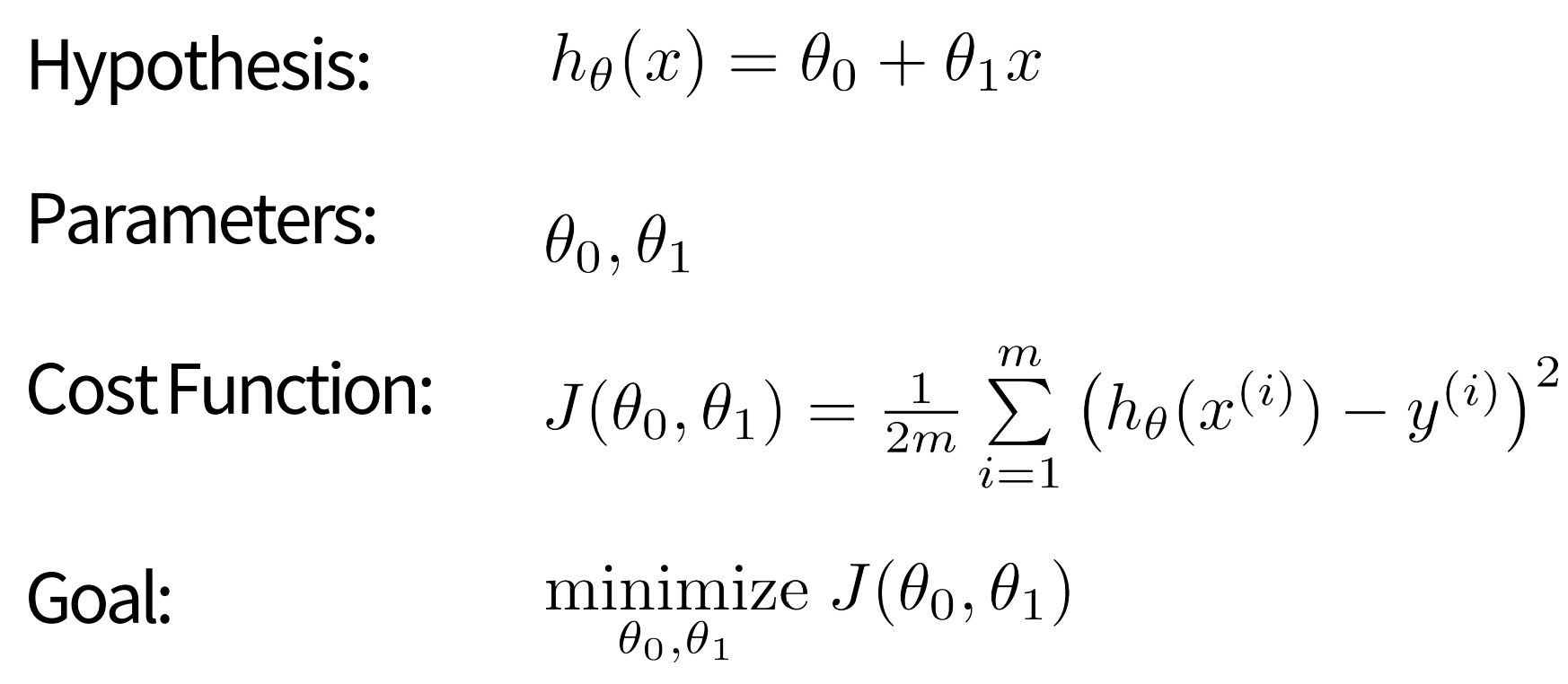
최소값(minimum)에 닿을 때까지 J(세타) (== 비용함수)가 작아지는 방향으로 파라미터를 계속해서 바꿔나가는 것🚨 주의: 반드시 global minimum point로 가는 것이 아니라 local min으로 빠질 수도 있음 => strating point 설정
3.[ML] 선형 회귀에서의 Overfitting 문제

선형 회귀 2개 이상의(multivariate) 독립변수를 경사하강법의 최소 제곱 방법을 활용해 최적화하는 것 > - 최적화를 위해 cost function을 각 individual weight(parameter)로 미분함 > - Learning algor
4.[ML] Logistic Regression for Classification
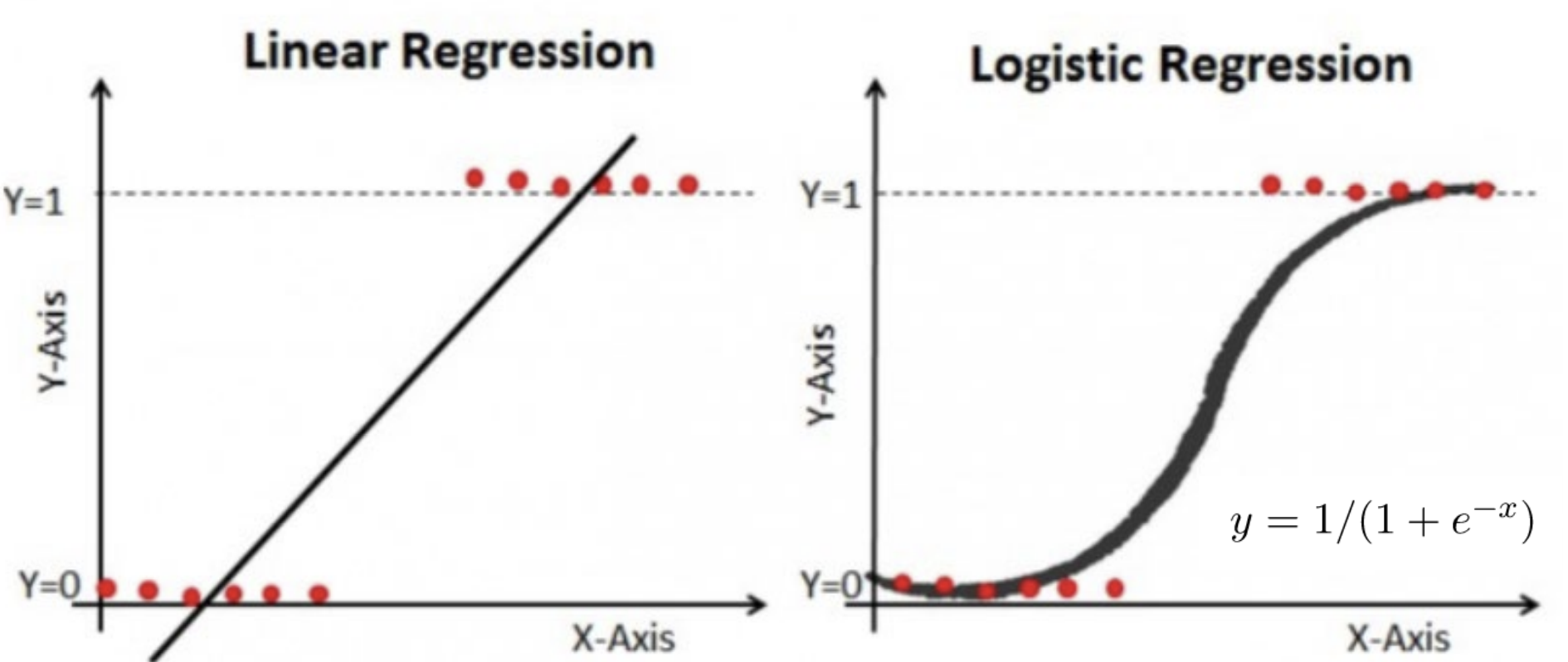
traget 변수가 category(범주형) 일때 사용되는 classification(분류) 알고리즘binary output일 때 사용 => 0 or 1만약 threshold가 0.5보다 내려가면? -> class 1로 예측되는 경우 多=> Conservative de
5.[ML] Neural Networks
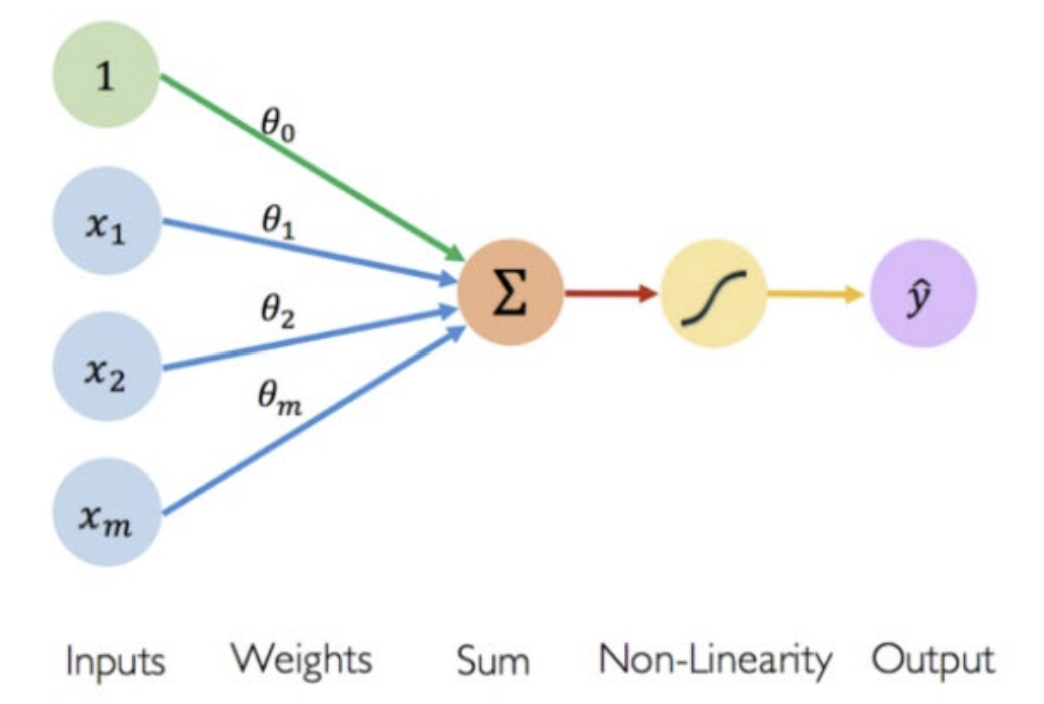
bias : 각 뉴런에 추가되는 값 (ex. 사진에서는 1)neural network가 학습하는 동안 weight와 함께 학습되며, activation function이 적용되기 전에 입력을 조정하는 역할을 함Dendrite: 다른 뉴런으로부터 신호 수신 (input
6.[ML] Neural Networks 2
Activation functions 기본 특징 (must) Non-Linear -> 비선형성 (must) differentiable -> 미분 가능해야함 zero-centered bounded bounded x이면, positi
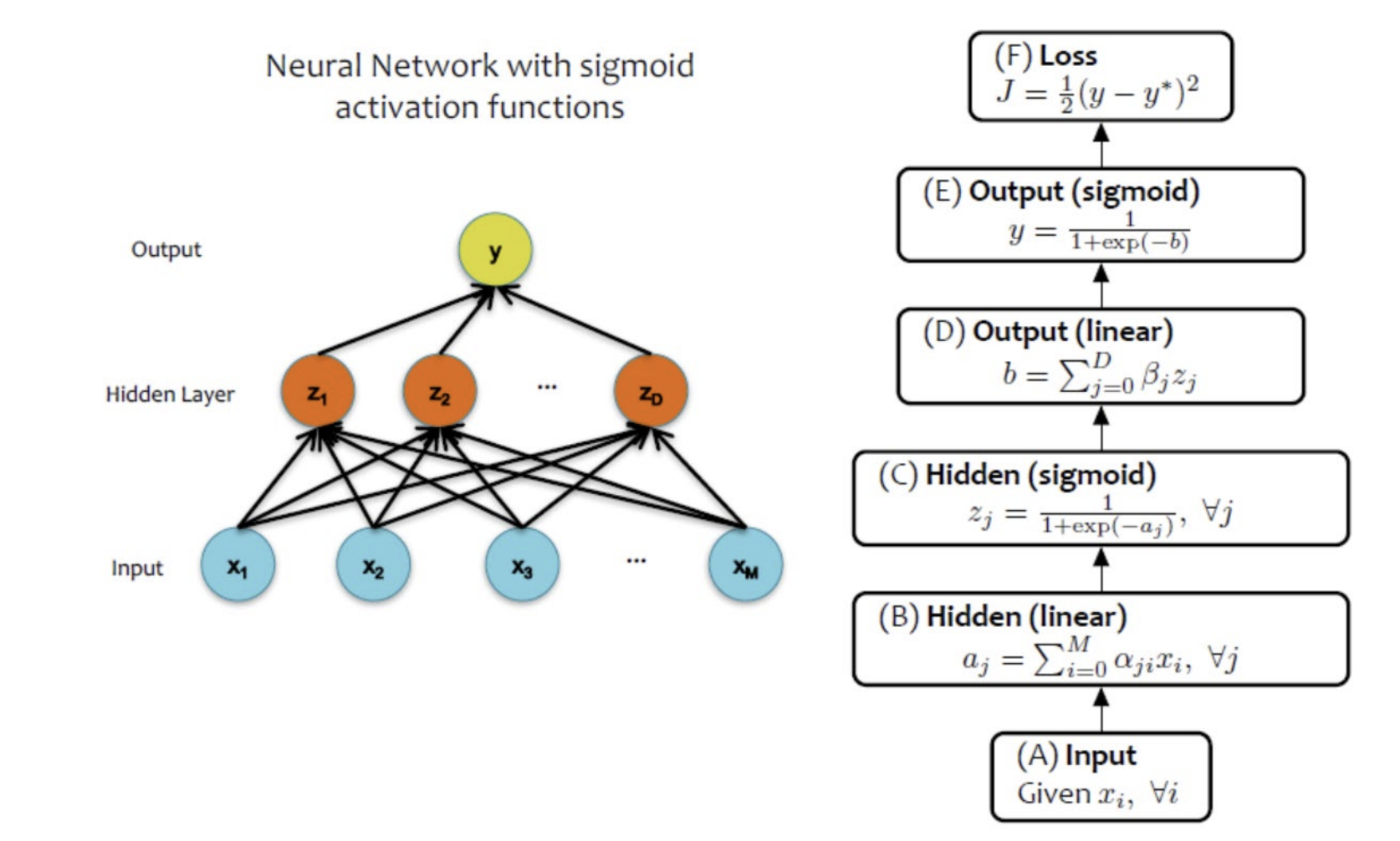
7.[ML] Neural Networks 3
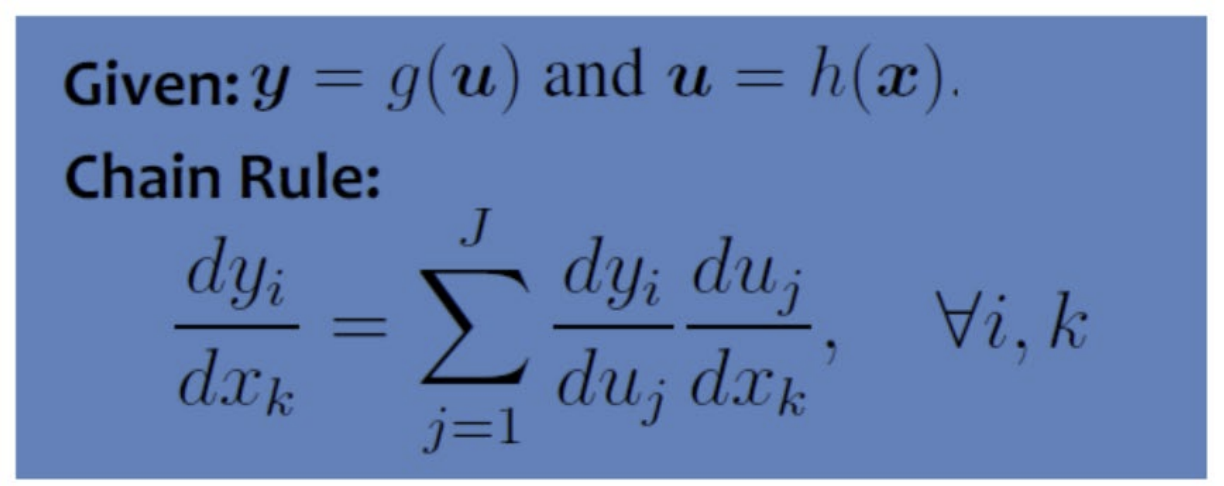
input x는 u(h(x))와 연결, u는 g(u)와 연결, g(u)는 output y와 연결되어 있음 Chain Rule: 합성함수의 미분 == 합성함수를 구성하는 각 함수의 미분(partial derivative==편미분)의 곱=> Backpropagation은
8.[ML] Neural Networks 4 (practice: Building Neural Networks w/ MNIST)

MNIST dataset == Mixed National Institute of Standards and Technology의 datasetMNIST의 숫자 분류는 머신러닝의 기초!Yann LeCun이 관리함0-9의 손글씨 숫자(handwritten digit) 인식총