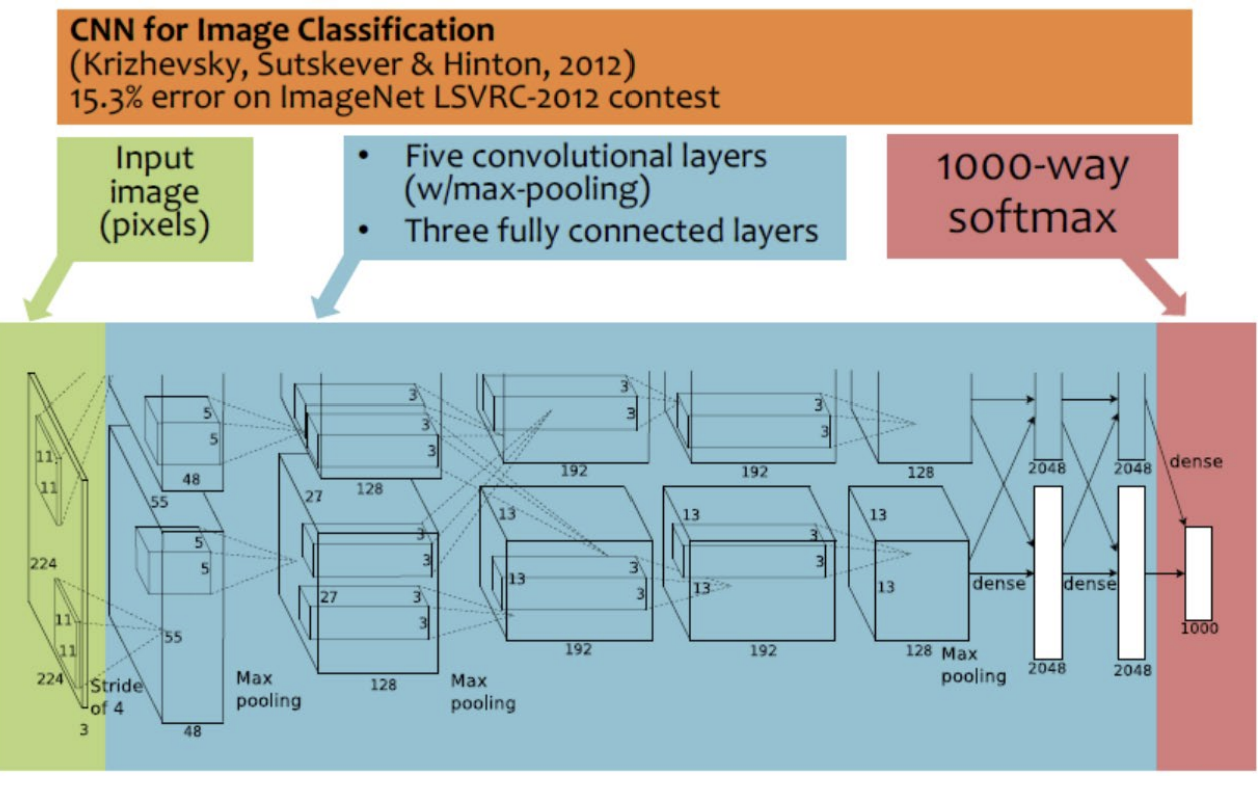
MNIST dataset

- MNIST dataset == Mixed National Institute of Standards and Technology의 dataset
- MNIST의 숫자 분류는 머신러닝의 기초!
- Yann LeCun이 관리함
MNIST number classification(숫자 분류)
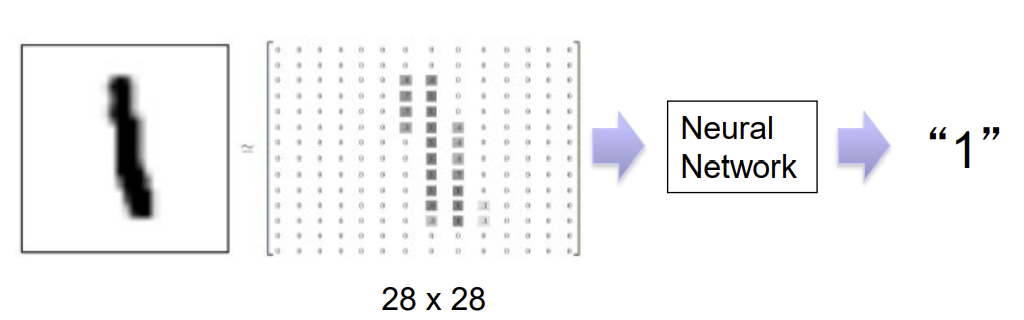
- 0-9의 손글씨 숫자(handwritten digit) 인식
- 총 70,000 이미지로 구성
- 60,000: train set
- 10,000: validation(test) set
- 속성(properties)
- 60,000개의 손글씨 숫자
- 28x28 pixels
- 0~255의 grayscale
- 0~9의 label
- 목표: 손글씨 숫자를 ㅇ니식할 수 있는 classifier를 훈련시켜라!
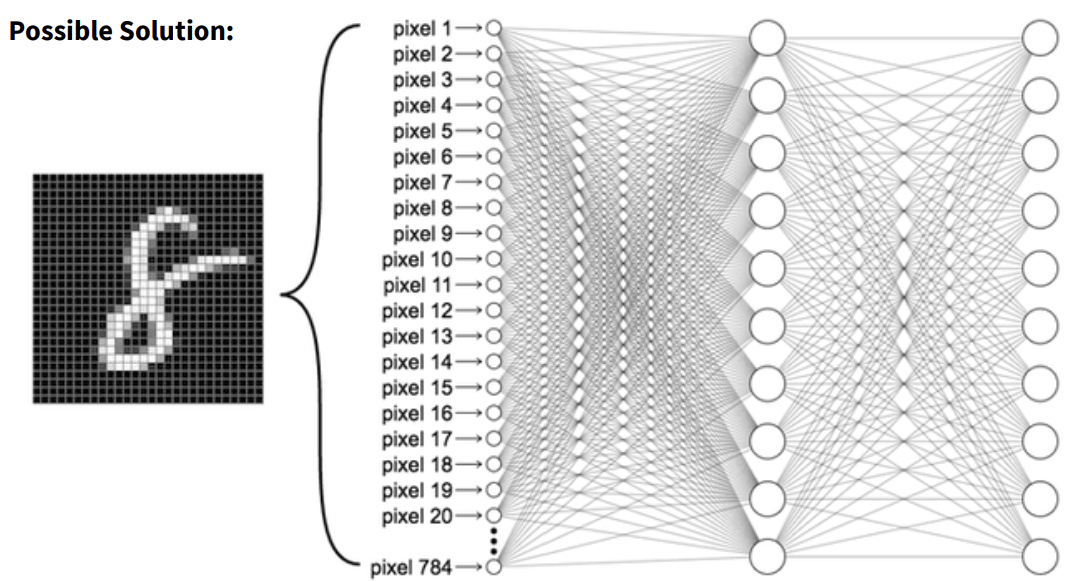
- 28x28 = 784 -> 총 784 pixel을 CNN에 넣어 학습시킴
- 마지막 output은 총 10개(0~9)에 대한 확률(0~1)로 나옴 (가장 높은 확률이면 -> 그 숫자로 예측!)
MNIST dataset으로 MLI network(다층 퍼셉트론:Multilayer Perceptron Neural Network) 연습하기
hidden layer의 activation function: relu
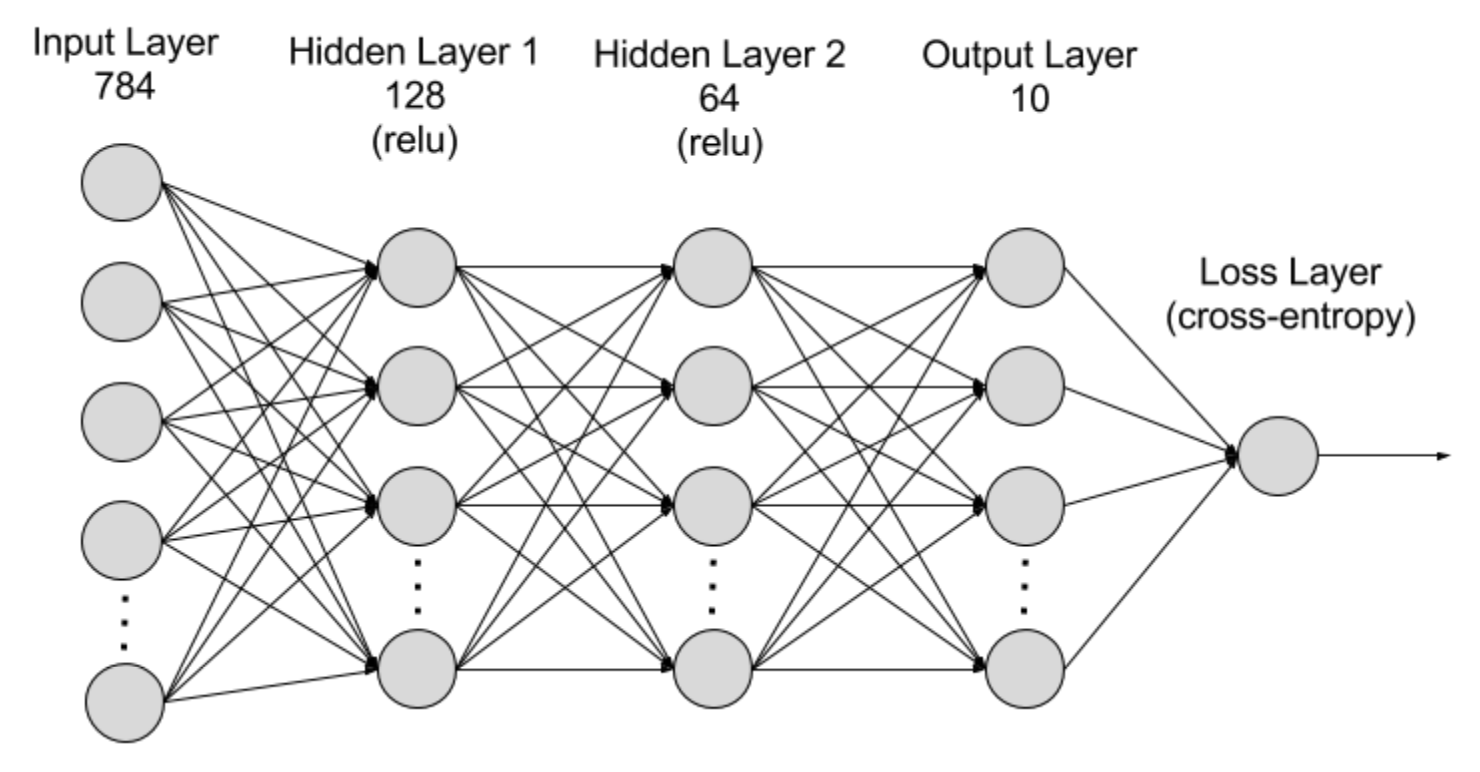
- MLP: 다층 퍼셉트론 인공신경망으로, 여러 층의 노드(뉴런)로 구성된 네트워크
- 입력층(input layer): 28x28 이미지가 1차원 벡터(784)로 입력됨
- 은닉층(hidden layer): 뉴런들이 비선형 변환을 수행하여 복잡한 패턴을 학습함
- MLP는 최소 하나 이상의 hidden layer 가짐
- 출력층(output layer): 분류 결과를 출력하는 층
- MLP는 Fully Connected layer로, 각 층의 모든 뉴런이 이전 층의 모든 뉴런과 연결되어 있음!
Data Preprocessing(전처리)
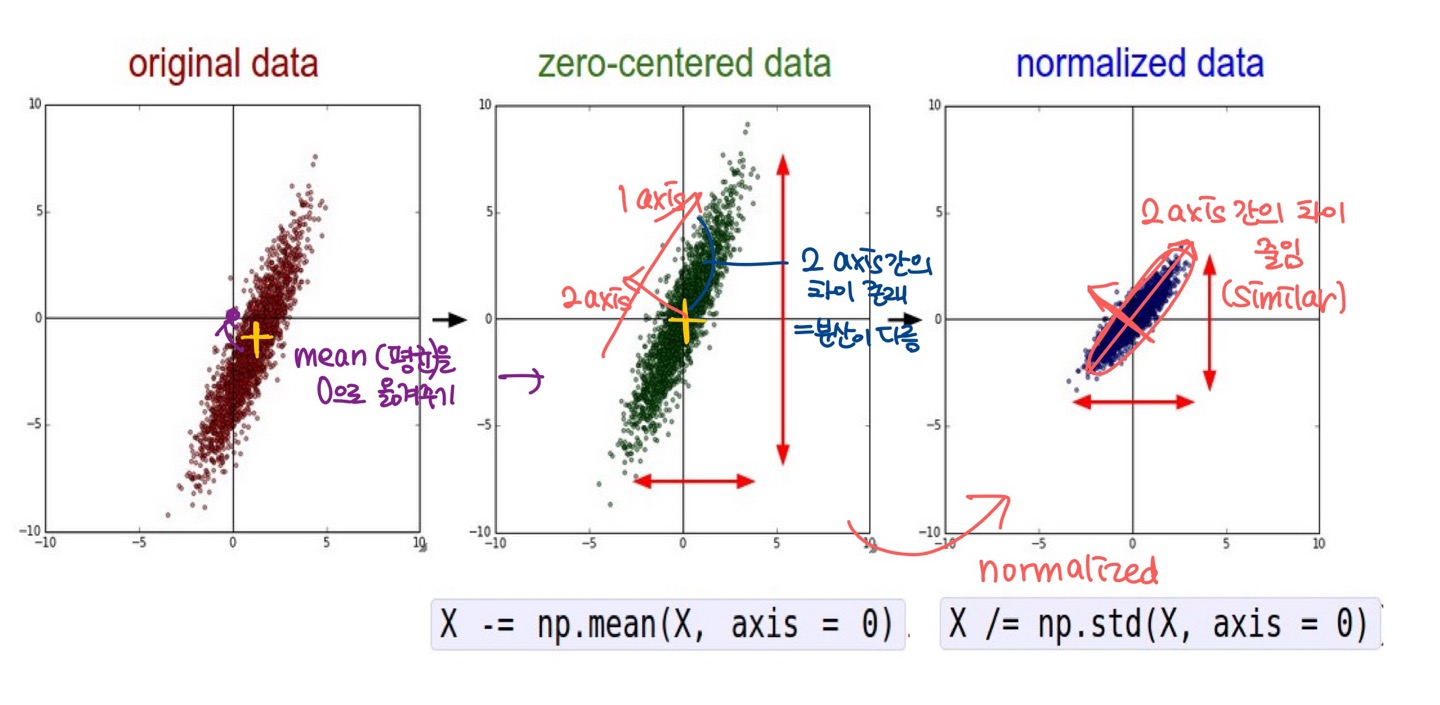
- zero-centered data: mean(평균)을 0으로 옮겨주기
but 여전히 2 axis간의 차이가 존재 (== 분산이 다를 경우) - normalized data: 2 axis간의 차이를 줄임
- normalization(정규화) 이전
- classification loss이 weight 변화에 매우 민감함 -> 최적화 어려움
- y= ax+b에서 a와 b가 바뀌면 loss가 많이 바뀐다는 뜻
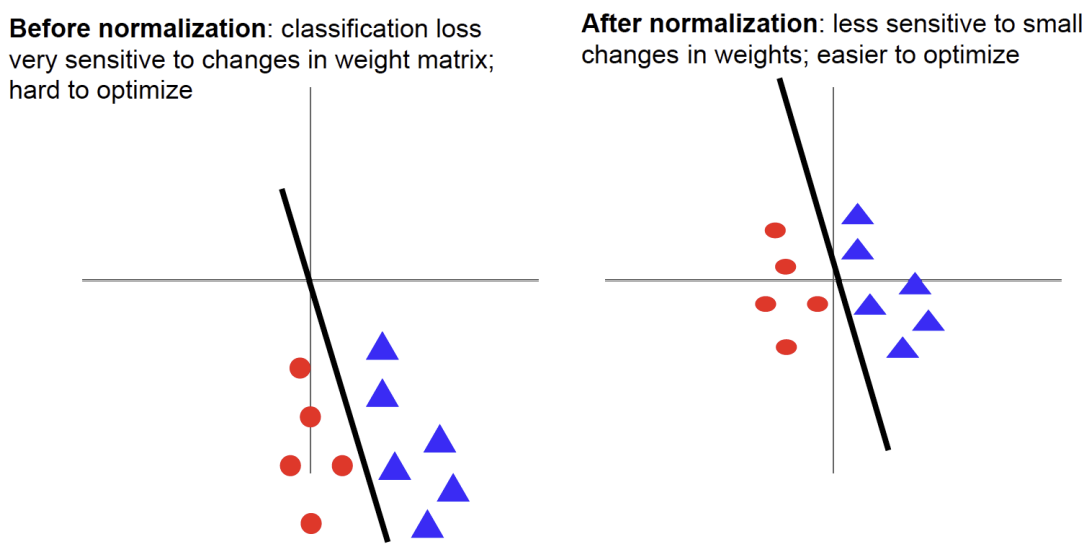
- 정규화 이후
- 가중치의 작은 변화에 덜 민감함 -> 최적화 쉬움
Mini-batch SGD
-
배치 경사 하강법(BGD) 또는 확률적 경사 하강법(SGD)이 아님
-
고정된 크기의 mini-batch를 만든 후, 하나의 epoch에서 다음 단계를 수행함
- mini-batch를 선택(ex. 100개)
- NN(신경망)에 입력(feed)
- mini-batch의 mean gradient 계산함 (<- ex. 100개의 batch 대해)
- mean gradient를 사용하여 weight 업데이트
- 1-4단계를 반복함
-
Mini-batch SGD는 SGD의 견고성(robustness)과 BGD의 효율성(efficiency) 사이에서 균형을 찾음 (딥러닝 분야에서 가장 일반적으로 사용되는 gradient descent(경사하강법) 구현 방식!)
속도
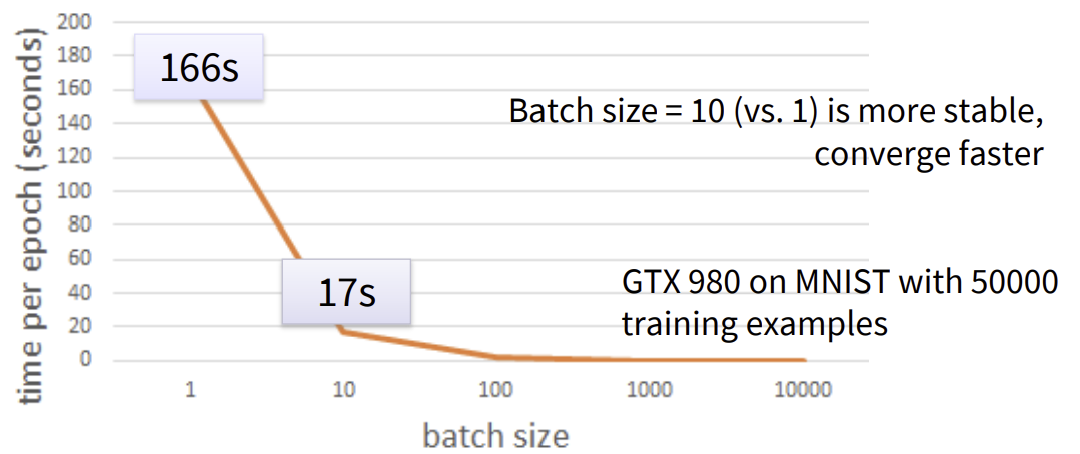
- batch의 크기가 작을 수록, 한 epoch에서 더 많은 update
- 50000개의 예제에서, batch의 크기가 10개이면 한 epoch에서 5000번 업데이트
- 50000개의 예제에서, batch의 크기가 1개이면 한 epoch에서 50000번 업데이트
- batch의 적정한 크기를 정하면 더 안정적이고 빠르게 수렴(converge)할 수 있음
- 하지만, 너무 큰 batch 크기는 성능이 훨씬 나쁠 수 있음(worse performance!!!)
GTX 980으로 MNIST에서 50000개의 훈련 예제 사용
Cross-entropy for classification
Binary cross-entropy(이진 크로스 엔트로피)
- yi: 예측 확률 값
- yi프라임: 해당 class대한 실제 확률

Cross-entropy for multi-class classification (i>=2)


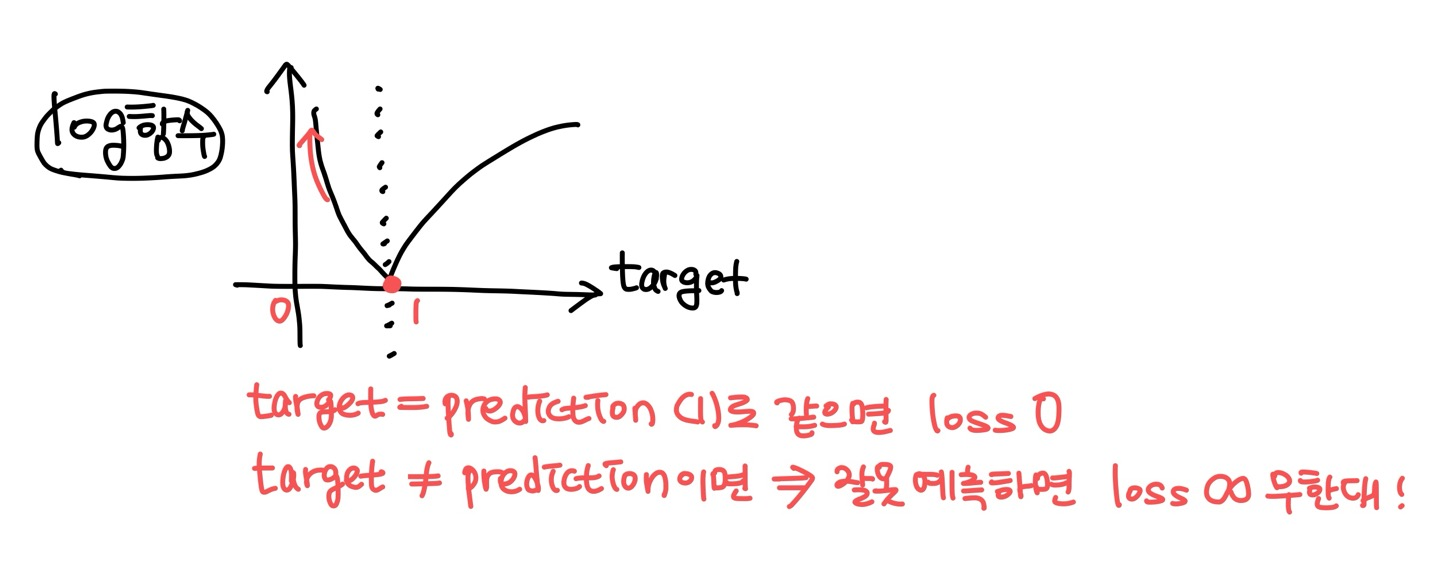
<로그 그래프로 확인 가능>
- 예측이 1일 때(목표값이 1인 경우), 손실은 0입니다.
- 예측이 0일 때(목표값과 완전히 반대인 경우), 손실은 무한대가 됨
PyTorch에서 쓰이는 Cross-entropy 함수: nn.CrossEntropyLoss

-
이 기준은 nn.LogSoftmax(), nn.NLLLoss()를 하나의 class에서 결합한 것!
-
- LogSoftmax()로 logits을 로그 확률(prob:0~1)로 변환
-로짓(Logit)(== score): 확률 값으로 변환되기 직전의 최종 결과 값
- LogSoftmax()로 logits을 로그 확률(prob:0~1)로 변환
-
- NLLLoss()를 적용하여 loss를 계산함
-
이 두 과정을 한번에 처리하는 것이 nn.CrossEntropyLoss!!
+) 코드에서 torch.Tensor([0.1,0.2, 0.9])에 들어가는 숫자들은 logit!
=> nn.CrossEntropyLoss()는 내부적으로 softmax와 log softmax를 처리하기 때문
Q1. y_pred1, y_pred2 어떤게 높은 loss를 가지고 있을까?
y_pred2는 torch.Tensor에 [0.5, 2.0, 0.3] logit을 넣음으로써 label 값인 0번째 값에 대해 가장 낮은 logit == 가장 낮은 확률을 넣었음, 따라서 높은 loss를 갖게 됨!
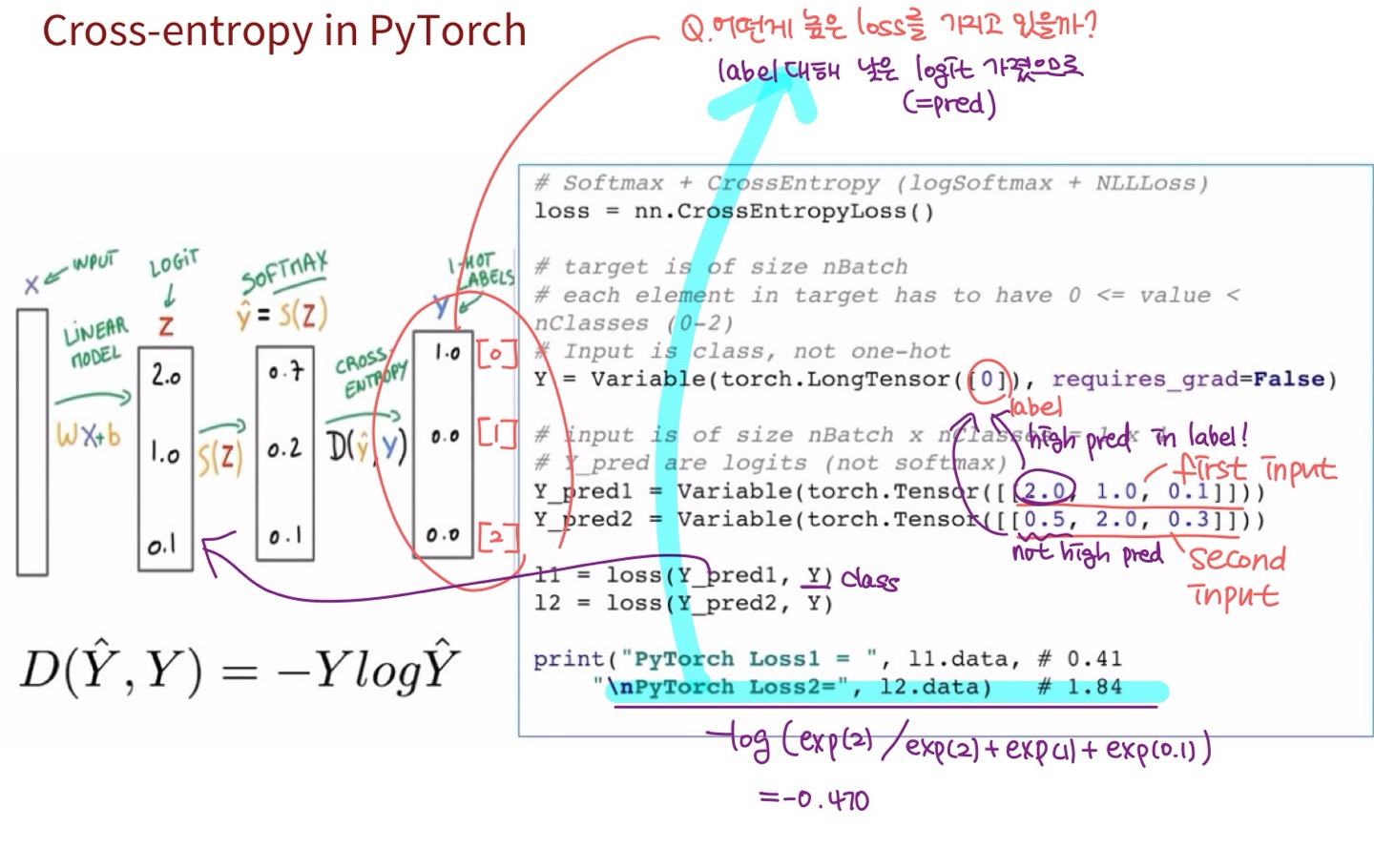
Q2. y_pred1, y_pred2 어떤게 높은 loss를 가지고 있을까?
y_pred2가 label 값을 잘 예측하지 못함 (== 낮은 logit), 따라서 높은 loss를 갖게 됨!

Training, Validation, Test Set
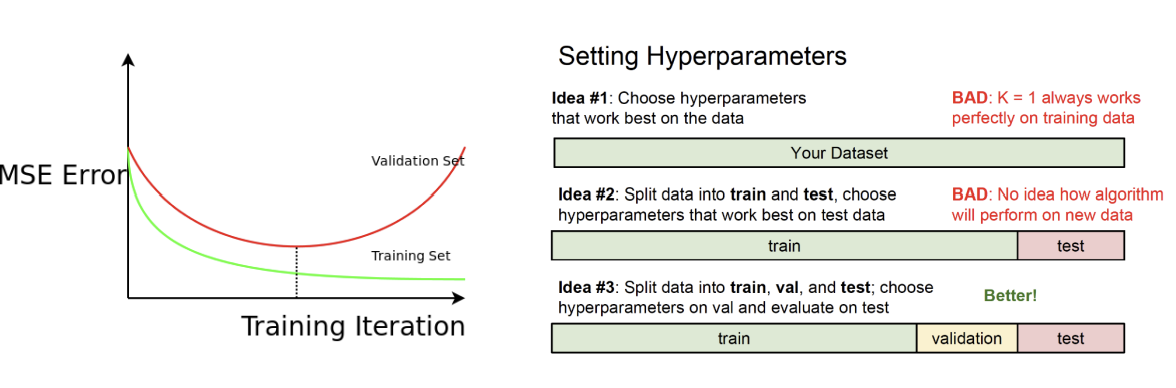
- Train data: 알고리즘 훈련에 사용되는 데이터
- Validation data: 검증에 사용되는 데이터 (training error와 validation error를 사용하여 overfitting 방지 위해 언제 멈출지 결정함)
- Test data: 머신러닝 알고리즘의 일반화 능력(generalization ability)를 측정하는 데 사용하는 데이터(훈련 과정에서 한번도 본 적 없는 데이터를 사용할 것!)
CNNs Background
- CNN(Convolutional Neural Network, 합성곱 신경망): 이미지 분석에 사용됨
- LeNet(초기cnn)과 동일한 구조이지만, 각 합성곱 레이어에서 사용하는 필터의 수를 늘려 모델의 성능을 향상시킴
- multi GPU 사용후 combine함
- 딥러닝 아키텍쳐 도입 이후 traditional methods보다 성능이 눈에띄게 향상함!