
https://arxiv.org/abs/2404.01945
Event-assisted Low-Light Video Object Segmentation (Li et al., CVPR 2024)
1학기 때 졸프 땜에 본 논문인데, 복습 차원에서 다시 한번 정리해 봄.
1. Intro
Video Object Segmentation (VOS) : 연속된 영상 프레임에서 관심 객체를 segmentation 하는 기술.
VOS는 두가지로 나눌 수 있는데,
- Semi-supervised VOS: 첫 프레임의 GT(ground truth mask)가 주어짐 → 이후 프레임을 예측
- Unsupervised VOS: GT 없이 학습
이 논문은 Semi-supervised VOS 를 따름.
문제점 : 저조도 환경에서의 성능 저하
- 일반적인 VOS는 밝고 선명한 RGB input을 전제로 설계되어 있음.
- 반면에 저조도 환경에서는 영상의 색 정확도 감소, texture/edge 정보 손실, 프레임 간 유사도 매칭 정확도 저하 등 -> Segmentation 성능 급격히 떨어짐
해결 방안 : Event Camera
Event Camera는 기존 RGB frame Camera와 달리, 밝기 변화가 감지될 때만 픽셀이 이벤트를 발생시키는 원리
장점 :
- High Dynamic Range (HDR) — 매우 밝거나 어두운 환경에서도 작동 가능
- High Temporal Resolution — 초당 수천 FPS급, 미세한 움직임 감지
- Low Latency / Low Power
따라서 저조도 환경에서도 edge, motion 등등을 잘 포착할 수 있음.
연구 필요성
(1) RGB + Event 가 각 프레임별로 매칭되고, 각 프레임별 annotation까지 포함된 paired dataset 필요
(2) 프레임과 이벤트의 Feature Fusion이 까다로움
-> 단순한 concat, sum 같은 방법으로는 오히려 노이즈/정보손실 발생
(3) 저조도에서의 Memory 매칭 (=현재 프레임과 과거 프레임의 similarity 계산)이 불안정
본 연구는 저조도 환경에서의 VOS 문제를 해결하기 위해,
Event Camera의 장점을 활용한 새로운 Multimodal Framework를 제안함.
저조도 환경에서 RGB 프레임의 시각 정보 손실을 Event data로 보완하고, Adaptive Cross-Modal Fusion(ACMF) 과 Event-Guided Memory Matching(EGMM) 을 통해 두 모달리티의 상호보완적 특징을 통합함으로써,
기존 방법 대비 높은 Segmentation 정확도를 달성함.
4. Method
1. Overview
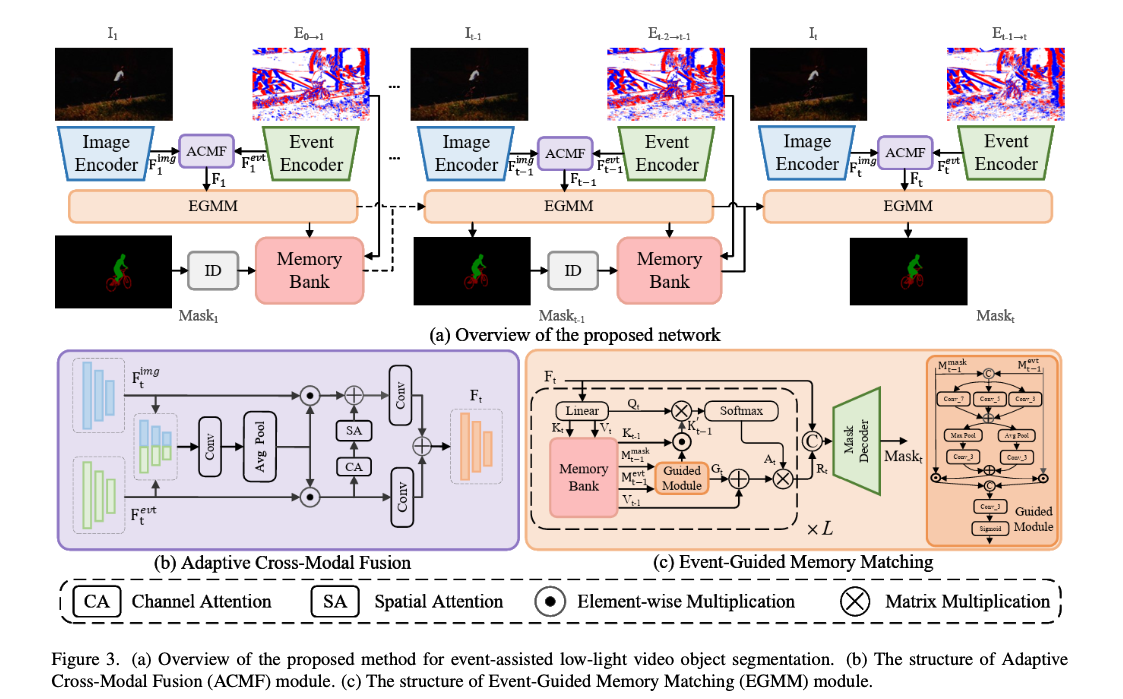
모델 구성요소
- Image Encoder
- Event Encoder
- ACMF(Adaptive Cross-Modal Fusion)
- EGMM(Event-Guided Memory Matching)
- ID(Identity Assignment)
- Memory Bank
- Mask Decoder
(1) 특징 추출
- RGB frame에서 이미지 특징 Ft(img), 이벤트 바인딩(=voxel)에서 이벤트 특징 Ft(evt) 추출
- 두 특징은 ACMF에 들어가 저조도에서 유용한 complementary information를 뽑아낸 fusion feature를 생성
(2) 초기 스텝 (t=1)
- EGMM이 (fusion feat으로부터 얻은) Q1, K1, V1를 만들고, ID 모듈은 초기 GT 마스크를 특징으로 변환
- 이때의 마스크 특징, 이벤트 특징, 그리고 K1, V1를 memory bank에 저장
(3) 이후 스텝 (t>=2)
- memory bank에서 이전 시점의 Key/Value, 이벤트 특징, 마스크 특징을 불러와 EGMM으로 매칭을 수행하고 현재 프레임의 마스크를 생성
- 예측된 마스크 특징도 다시 메모리에 누적
2. Event -> Voxel Grid
- 비동기 이벤트 스트림(t−1 → t 구간)을 시간 축으로 B개의 bin에 누적하여 크기 B×H×W의 voxel grid로 변환
3. Adaptive Cross-Modal Fusion (ACMF)
(1) Ft(img), Ft(evt)를 합쳐 combined feature set을 만들고, 여기에 합성곱을 통과시켜 coupled information를 추출
(2) Channel Attnetion(CA), Spatial Attention(SA)을 Event feature에 적용하여
edge information을 추출 (= 이벤트 특징에 attention하도록 가중하는 단계)
(3) 두 feature 각각 합성곱으로 정제하고 element-wise multiplication, sum으로 최종 fusion feature를 출력
-> 이벤트 feature로 edge/motion을 보강하고, RGB의 texture는 살리고, 저조도에서의 noise는 제거함.
4. Event Guided Memory Matching (EGMM)
EGMM은 아직 공부 안했음.
5. Loss Function
Loss : BCE + Soft-Jaccard (α = β = 0.5)
5. Experiments
(1) Dataset
- Synthetic LLE-DAVIS
- Real-world LLE-VOS
(2) Metric
- J score : segmentation accuracy(=mIoU)
- F score : contour accuracy
- J&F mean
(3) Result
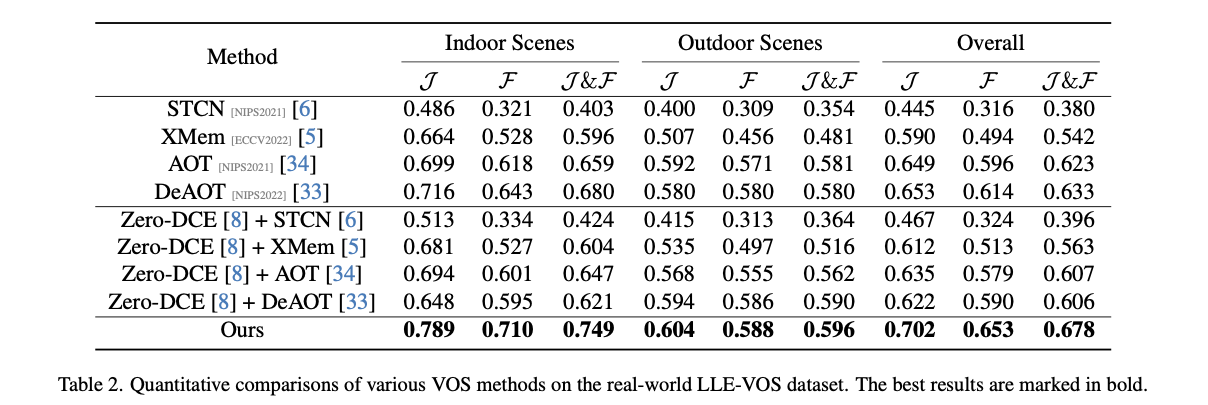

합성 데이터셋 (LLE-DAVIS) 과 실세계 데이터셋 (LLE-VOS) 모두에서
SOTA 대비 6–8 % 성능 향상 (J&F mean 기준)
