On-the-Fly OVD Adaptation with FLAME: Few-shot Localization via Active Marginal-Samples Exploration

https://www.aitimes.com/news/articleView.html?idxno=203477
https://arxiv.org/pdf/2510.17670v1
1. Overview
OVD(Open-Vocabulary Object Detection) : VLM에서 파생된 개념으로, 사전에 정의된 고정 클래스에 의존하지 않고 자연어 텍스트를 입력으로 임의의 객체를 탐지할 수 있는 기법이다.
즉, 사용자가 “ship”, “wind turbine”, “solar panel” 등 새로운 단어를 제시하더라도,
모델은 텍스트 임베딩을 통해 해당 개념과 시각적 특징을 연관지어 탐지할 수 있다.
하지만 VLM이 학습하는 자연어 임베딩은 서로 의미적으로 유사한 단어들을 인접하게 배치하기 때문에, semantic ambiguity(=의미적 모호성)이라는 근본적인 한계가 있다.
예를 들어, ‘fishing boat’과 ‘yacht’, 'ship', 'boat' 등등은 embedding 공간에서 매우 근접하게 분포하기 때문에 모델이 이를 구분하지 못한다.
특히 RS 같은 도메인에서는 수많은 클래스(선박, 항만 구조물, 여러가지 건물 유형 등등,,)가 있는데, 모든 클래스를 명시적으로 정의하기 어려우므로,
OVD 모델의 zero-shot 탐지로는 이런 복잡한 도메인에서 성능 확보가 어렵다.
이를 극복하기 위해 Google Research는 FLAME(Few-shot Lightweight Active Model Enhancement) 이라는 경량 학습 프레임워크를 공개했다.
기존의 Fine-tuning이나 Few-Shot Object Detection(FSOD), 또는 Parameter-Efficient Fine-Tuning (PEFT) 계열 기법(ex. LoRA,,)은 여전히 모델 내부 파라미터를 수정해야 GPU 환경에서 또 수많은 에폭을 거쳐야 함.
반면 FLAME은 One-step Active Learning 구조를 통해 이 fine-tuning 과정을 완전히 제거했다.
즉, OVD가 생성한 zero-shot proposals 중에서 결정경계 근처의 불확실한 후보만 탐색하고,
이들 중 가장 애매한 후보를 density estimation 과 clustering으로 선별하여 유저가 라벨링함. (여기서 이 애매한(=유익한) 후보를 선별하는 알고리즘이 관건!!)
이후 이 소수 샘플만으로 lightweight classifier를 실시간 학습시킴. (대형 OVD 백본은 freeze)
즉, 출력 feature 공간 위에 작은 분류기(여기선 SVM 또는 2-layer MLP) 하나를 얹는 구조
그래서 GPU가 아닌 CPU 환경에서 1분 이내에 수행되며, 기존 fine-tuning 방식보다 수백 배 빠르고, 대용량 위성영상 같은 도메인에도 수월하게 적용 가능함.
2. Method
3가지 부분으로 구성됨.
(1) Feature Representation & Candidate Generation
(2) Marginal Sample Exploration (Active Learning)
(3) Lightweight Classifier Training (Model Enhancement)
(1) Feature Representation & Candidate Generation
FLAME은 기존의 OVD 백본(여기선 OWL-ViT v2)을 사용한다.
이 백본은 이미지–텍스트 쌍을 입력받아, 각 후보에 대해
- Image feature (비전 인코더의 region-level embedding)
- Text feature (텍스트 쿼리의 언어 임베딩)
- Cosine similarity (ci)
를 생성함.
-> 이미지 feature와 언어적 유사도를 합친 augmented embedding으로 표현됨.
(2) Marginal Sample Exploration (Active Selection)
사용자가 라벨링해야 할 가장 애매한(=유익한) 샘플을 선별하는 단계
(a) Feature Space Construction
모든 후보를 수집한 후, PCA로 저차원 공간(2~3D)으로 투영한다.
(b) Density Estimation
Gaussian Kernel Density Estimation (KDE)를 사용하여 각 점의 주변 데이터 밀도 pi를 계산함.
- 밀도가 너무 높으면 확실한 샘플
- 너무 낮으면 outlier
- 중간값 정도면 결정경계 근처의 애매한 데이터
여기서 이 중간 밀도 구간에 속한 샘플을 marginal samples로 정의함.
(c) Diversity-Aware Clustering
- 하지만 중간 밀도 영역의 샘플들이 모두 비슷할 수 있으므로,
K-means clustering로 대표성을 고려한 다양성 확보. - 각 클러스터의 centroid 를 대표 샘플로 선택하여 사용자에게 표시함.
(d) User-in-the-Loop Labeling
유저는 20~30개의 대표 샘플에 대해 positive/negative 라벨만 제공한다.
이 데이터가 이후 classifier 학습의 support set이 됨.
(3) Lightweight Classifier Training
라벨링이 끝난 위의 데이터를 이용해 새로운 light weight classifier를 학습시키는 단계
-
입력 : Augment examples ([xi, ci])
-
classifier는 디폴트가 RBF SVM이고, CPU에서 1분내로 학습 가능함.
(학습된 classifier는 모델 출력의 후처리로 사용) -
기존 OVD의 예측 확률과 classifier의 출력을 결합하여 최종 confidence score를 계산함.
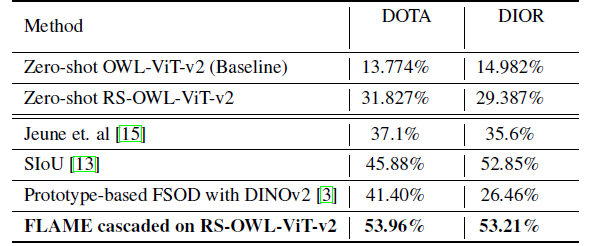
결론적으로, 기존 zero-shot 성능은 그대로 유지하면서,
semantic ambiguity 영역에서의 precision를 크게 향상시킴.
3. Experiments