YOLO v3
이번 포스팅에서는 yolo의 세 번째 버전인 yolov3에 대해서 소개하겠습니다.
YOLOv3
- anchor box 사용
- 각 bbox의 objectness score를 logistic regression을 이용하여 예측
- Darknet54 ( mAP 향상, FPS 하락 )
- classification에 binary cross-entropy loss를 사용 ( softmax 사용 x )
Regression 문제 + classification 결합하여 활용했네요.
yolov3에서는 mAP를 올리는 것에 집중하여 성능 개선하려는 노력이 있습니다.
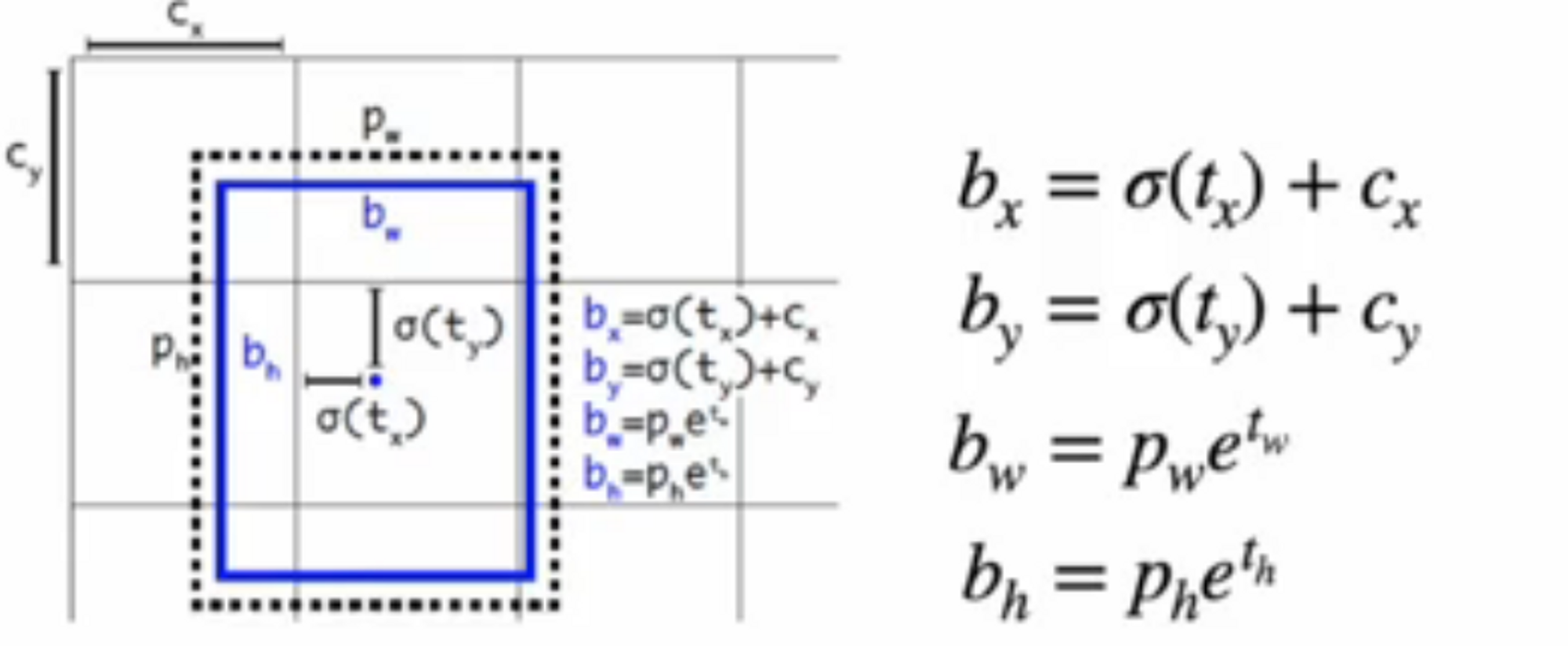
Anchor box with multiple scales
-
3가지 scale로 나눠 box를 예측
-
각 scale당 각 cell이 3개의 abox 사용
-
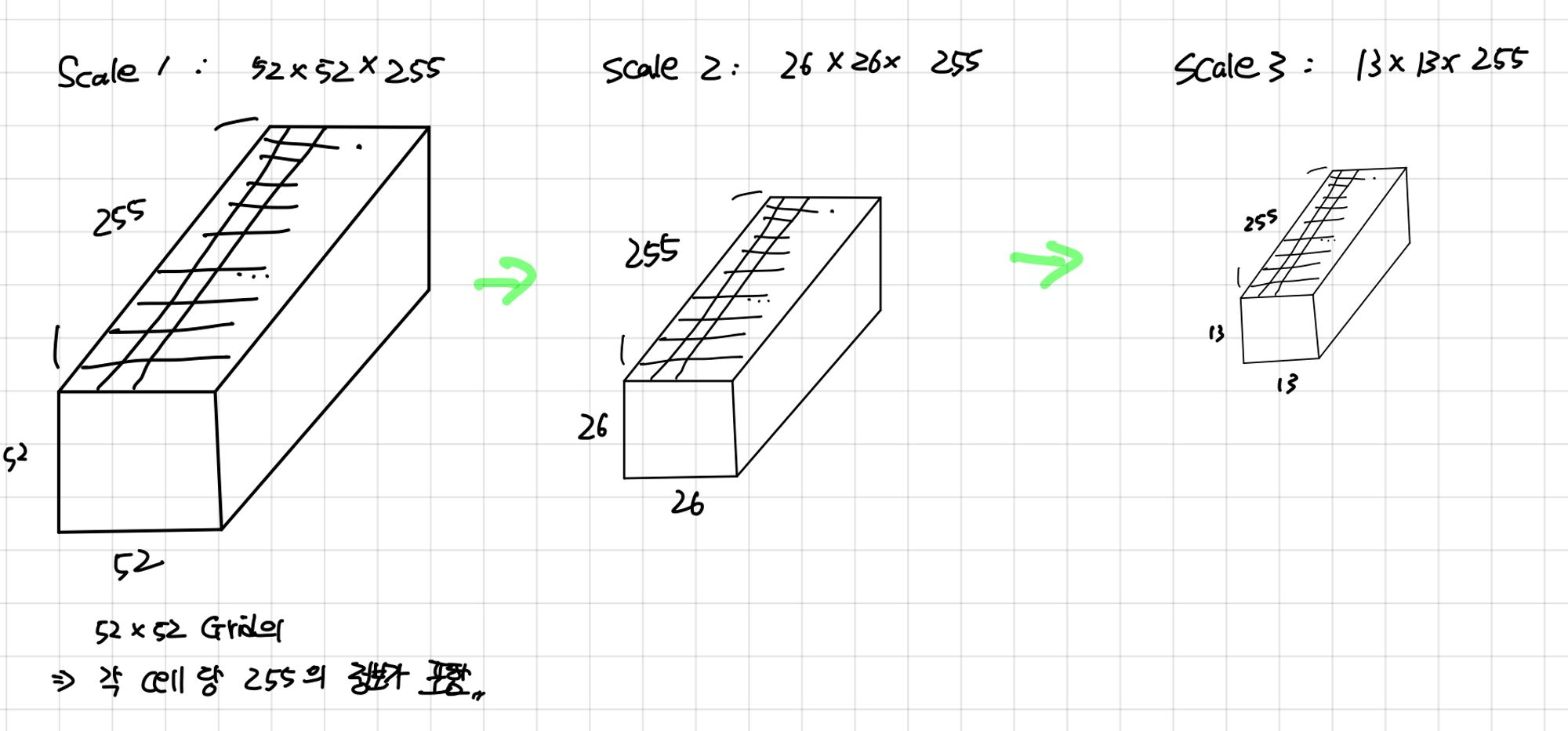
클래스의 개수가 80개인 coco 데이터를 고려하면 각 scale의 산출 feature map의 크기는 N x N x ( 3 x ( 4 + 1 + 80 ))
- 각 cell마다 중심(x,y) 높이,너비(w,h) = 4개
- confidence score = 1
- class 80개
- abox 3개 → 각 abox당 N x N의 크기를 갖고있음.
-
YOLOv1 : 98 boxes
-
YOLOv2 : 845 boxes
-
YOLOv3 : 10,657 boxes
-
필요한 9개의 abox를 k-means clustering을 통해 구한 후 스케일 별로 3개씩 나눔
-
Anchor box의 크기 → scale 별로 abox의 크기를 다르게 설정. 각 scale마다 3개의 abox
- scale1: 10x13, 16x30, 33x23
- scale2: 30x61, 62x45, 59x119
- scale3: 116x90 , 156x198, 373x326
→ yolov1부터 문제점은 작은 객체를 잘 캐치하지 못한다는 점이었죠? 큰 객체를 잘 잡는 것을 유지하면서(scale3) 중간 객체와 작은 개체를 모두 다 잘 잡으려는 노력(scale1,2)이 있었다고 보시면 될 것 같습니다.
ResNet
이번 yolov3에서는 ResNet에서 사용된 skip connetion을 사용했습니다.
기존의 전 layer나 전전 layer의 feature map을 그대로 더해서 학습 수렴성을 개선하고 성능이 향상되는 모습을 볼 수 있었습니다.
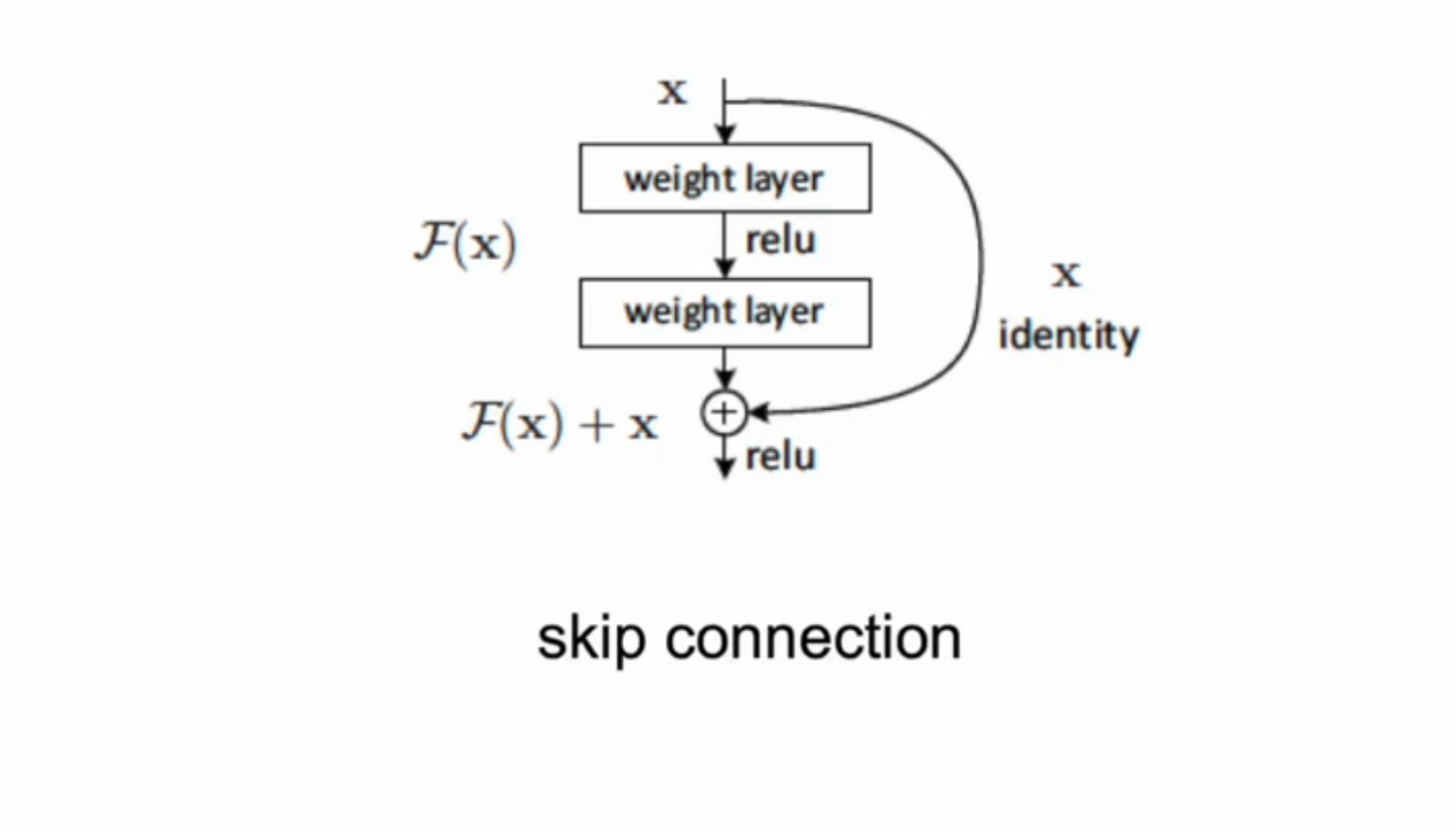
DarkNet53
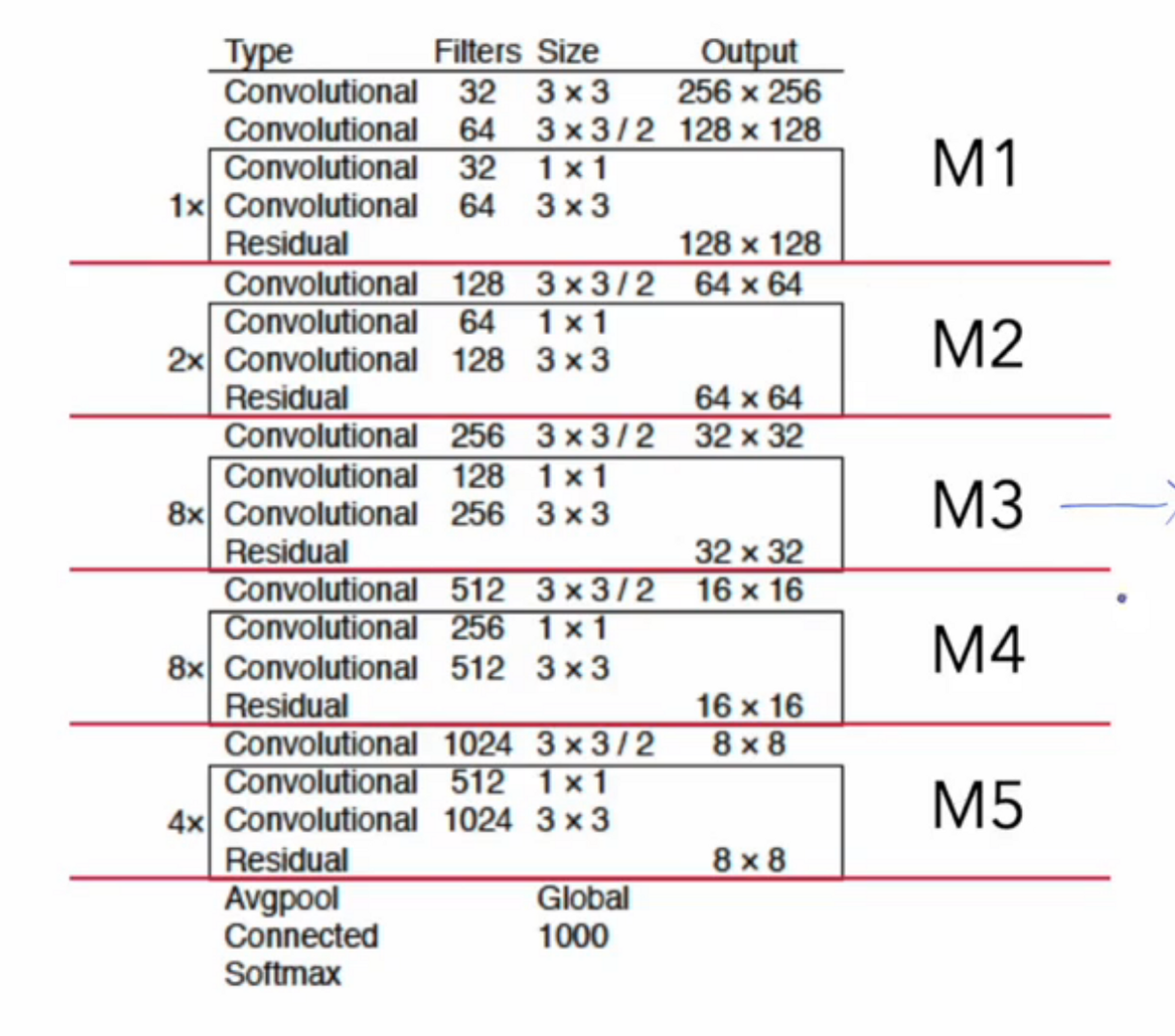
빨간 선을 기준으로 Residual Block을 이용해서 1회 반복 , 2회 반복, 8회 반복, 8회 반복, 4회 반복 순서로 연산을 진행했습니다. ( M1 ~ M5 )
이후에 M3 ,M4, M5에서 각각의 scale을 계산을 할 것입니다. (scale1 , scale2, scale3)
M3에서는 Feature map이 32 x 32
M2에서는 Feature map이 16 x 16
M1에서는 Feature map이 8 x 8
이를 이용하여 예측을 할 것입니다.
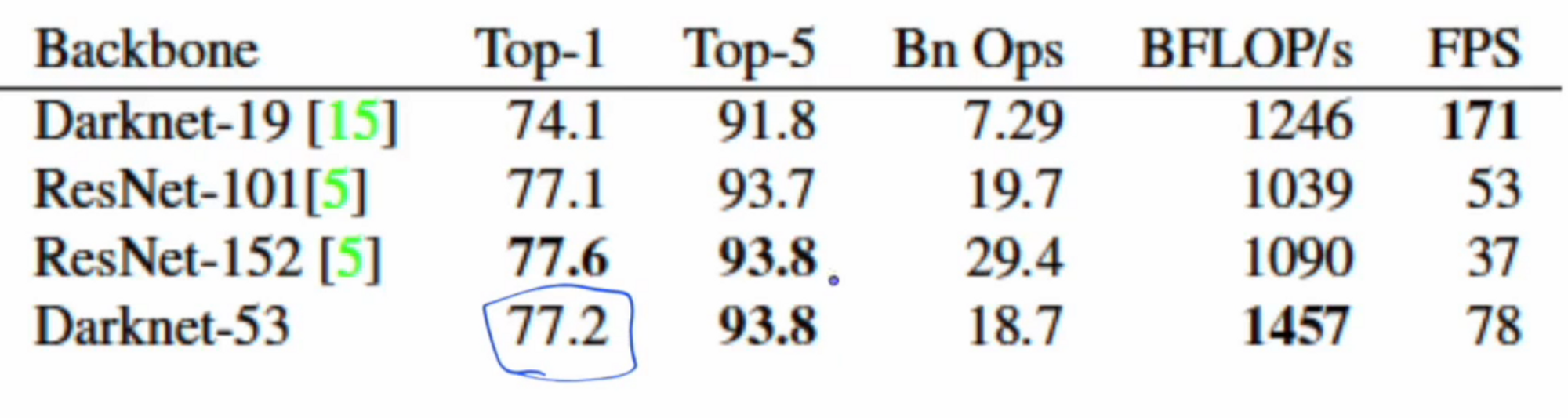
ImnageNet Classification 정확도
Darknet53으로 학습을 한 결과 77.2%의 정확도를 달성했구요 ( Top-1 )
Top-5는 1000개의 클래스 중에 상위 5개의 클래스 안에 Top-1이 들어있는지 나타내는 지표입니다.
Ops는 연산 수를 나타내구요
BFLOP/s는 초당 연산량을 나타냅니다.
→ 결과를 보면 ResNet-153보다 초당 연산량이 향상되었고 , FPS 역시 크게 올라갔네요.
YOLOv3 - 성능 개선 + FPNs, Neartest neighbor
Multi scaler를 효율적으로 적용하기 위해서 어떤 기술을 사용하는지 알아볼까요 ?
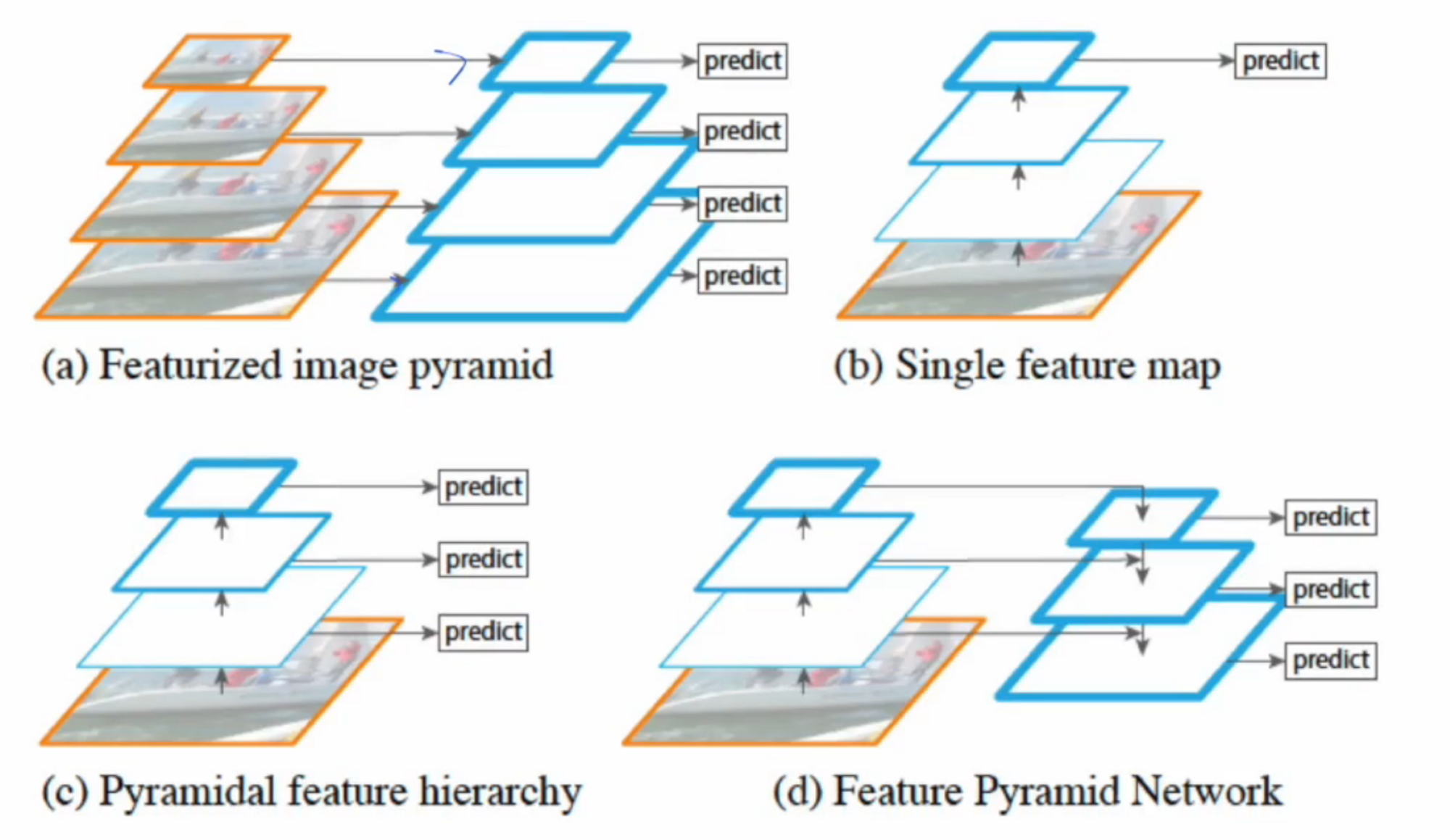
Feature Pyramid Networks ( FPNs )
모델옆에 Feature Pyramid Networks를 붙여서 활용하는데요, 예측을 하는 방법은 여러가지가 있습니다.
(a)과 같이 Featurized image Pyramid의 경우 각 이미지 크기에 대해서 예측을 하는 방법이있고,
(b)처럼 하나의 이미지에서 마지막 단계로 가서 예측하는 방법이 있습니다. 가장 기본적인 방법이죠.
(c)는 하나의 이미지를 모델에 넣어서 다수의 층에서 feature를 뽑은 후에 예측을 하는 방법이구요.
(d)는 우리가 사용한 Feature Pyramid Networks입니다. 이는 한 장의 이미지가 들어와서 연산이 쭉 되는데 특정 layer에 대해서 정보를 뽑구요 뽑은 상태에서 더 높은 성능을 위해 각각의 정보를 공유시킵니다. 그래서 다시 내려오는 작업을 해주면서 그 정보를 가지고 예측을 하게 되는거죠 !
Darknet53 for detection
M3에서 Feature map의 결과가 52 x 52 x 256 이고
M4는 26 x 26 x 512
M5는 13 x 13 x 1024 가 나옵니다.
여기에서 다시 M5 → M4 → M3 처럼 아래의 방향으로 정보를 흘려주는 작업을 합니다.
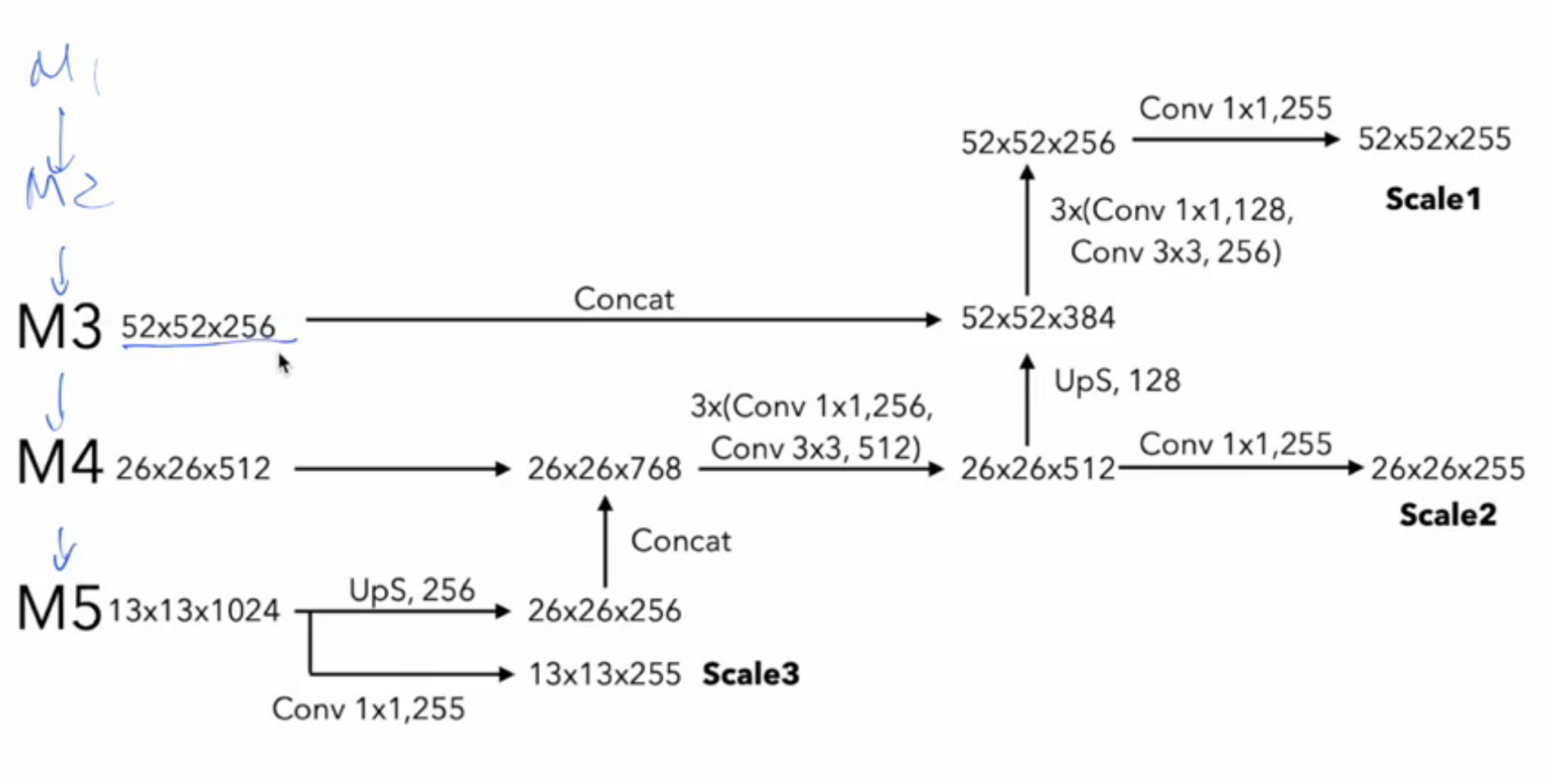
M5 → Conv 1x1을 한 번 해주면 13 x 13 x 255가 나오는데 이 값으로 예측을 하게 되구요
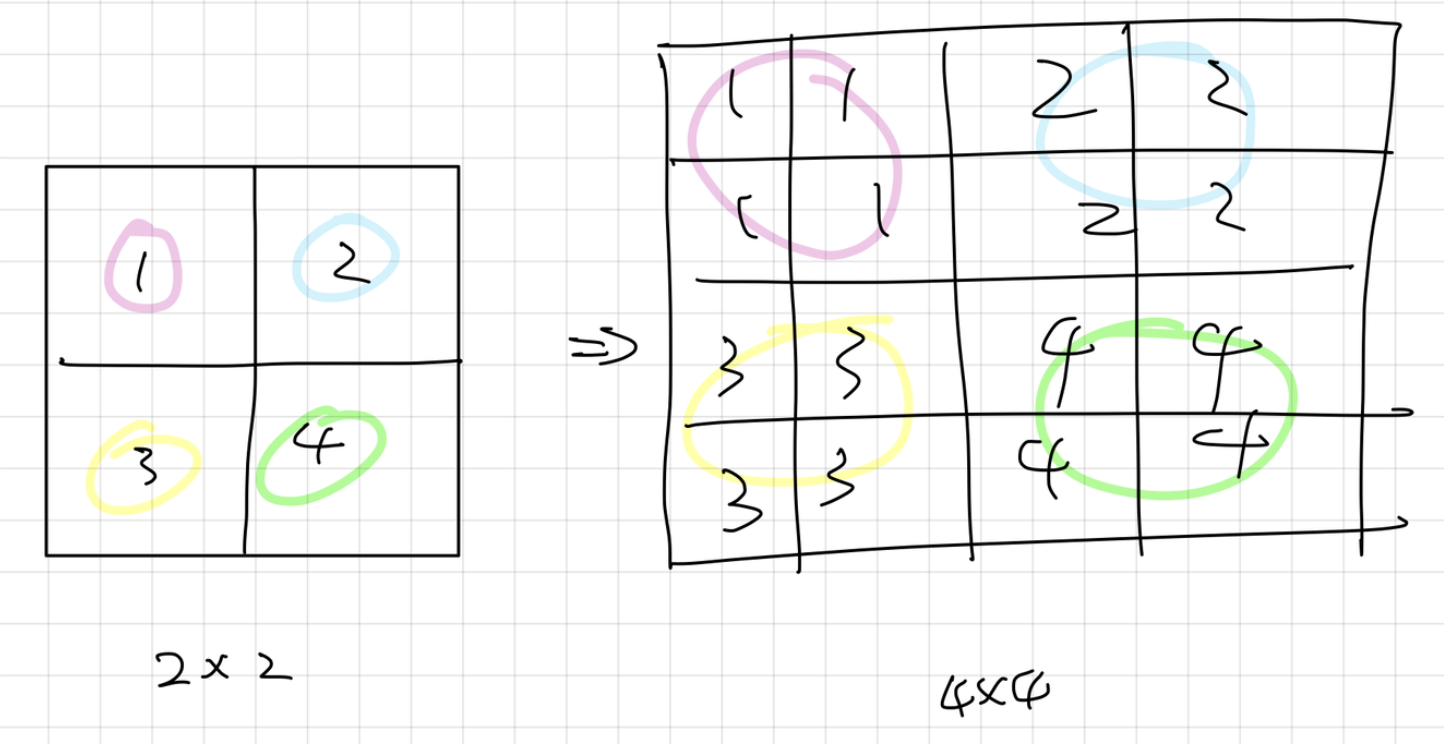
위로 올려줄 때는 Feature map의 크기가 다르기 때문에 ( 26 x 26이 되려면 2배를 해줘야함. ) Upsampling(UpS )을 해줘야합니다. 대신 채널 수는 줄여줍니다.
UpS은 여러가지 방법들이 있는데, 여기서는 nearset neighbor 방법을 사용합니다. 이 방법은 아래의 그림처럼 근처의 값을 그대로 옮기는 방법입니다.
26 x 26 x 256 값과 26 x 26 x 512를 Concatunate 시킵니다. ⇒ 26 x 26 x 768
26 x 26 x 768 얘는 Conv 3개를 거쳐서 26 x 26 x 512로 만들어주고,
이 값을 다시 UpS해서 52 x 52 x 128로 만들어 준 다음 52 x 52 x 256과 Concatunate 해주면
52 x 52 x 384 가 나오게 됩니다.
여기서 26 x 26 x 512 값은 Scale2의 예측으로 사용하기 위해서 Conv1x1를 통과시키면 ( conv 1x1 은 feature map의 크기는 유지된 채 채널 수만 조절 가능 )
마지막으로 52 x 52 x 384 역시 마찬가지로 UpS , concatunate 이후에 Conv1x1을 통과시켜 Scale1 예측값을 얻을 수 있습니다.
그림으로 정리하자면
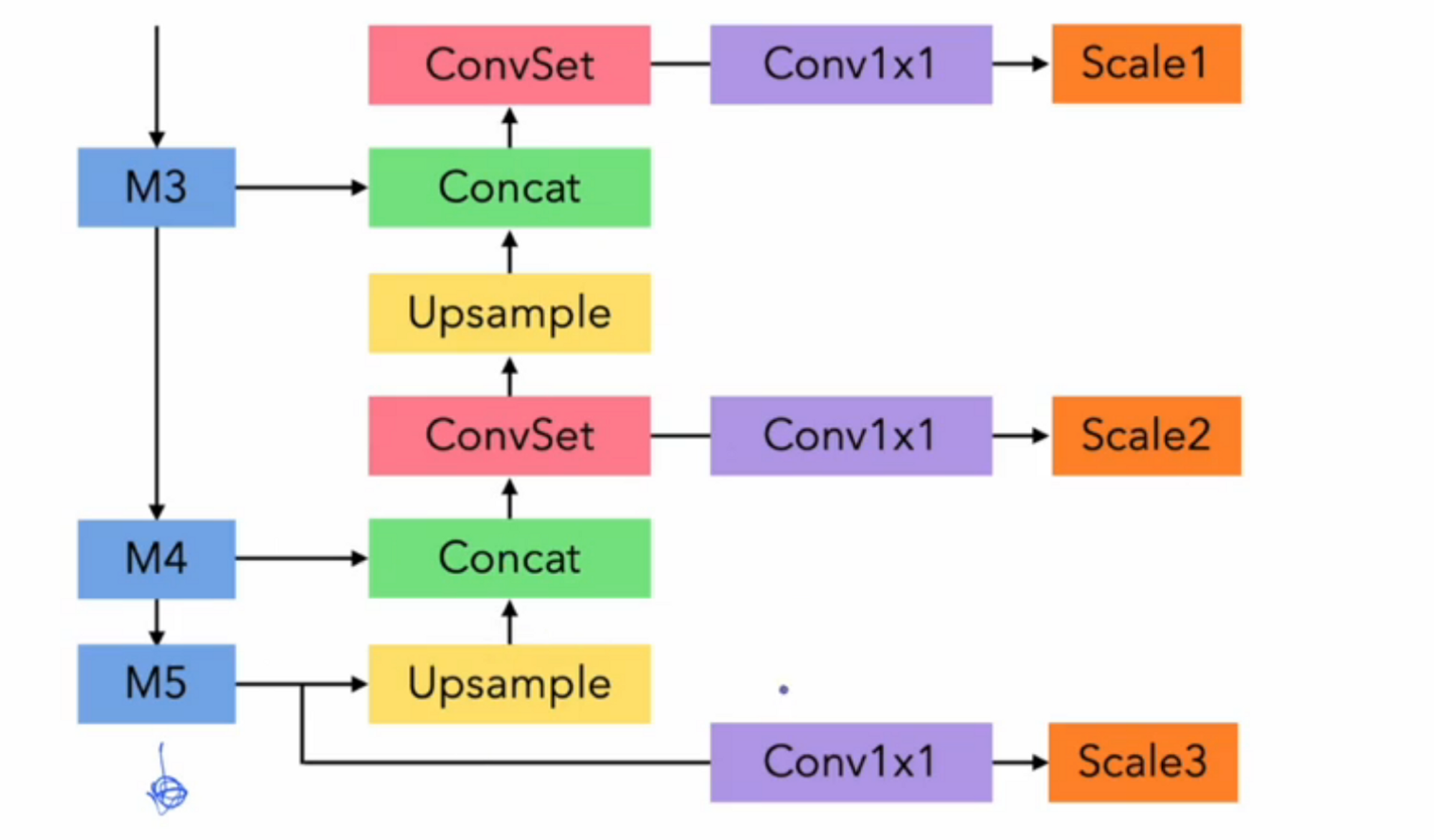
원래는 M5까지 가서 classification을 하는건데, 여기서는 M3 M4 M5의 정보를 각각 빼서 small medium large scale에 대한 object를 같이 고려하겠다는 것이죠.
각각의 Feature map의 크기가 2배씩 차이나기 때문에 Upsample을 통해 2배씩 만들어주는 역할을 하고 ,
Scale2는 Scale2와 Scale3의 결과물의 정보를 받아 연산이 되고 Scale1은 3,2의 가공된 정보를 받아 연산을 하게 됩니다.
Grid cell이 52 x 52 개, abox 각 cell당 3개 → 각 scale마다 abox의 수 계산
Scale 1 : 52x52x3
Scale 2 : 26x26x3
Scale 3 : 13x13x3
이를 모두 더하면 10647개가 나옵니다. Scale에서 나오는 abox를 예측에 활용하고 당연히 최종적으로 nms를 이용해서 best box를 찾습니다.
모델 학습
- multi-scale training 시행
- 다양한 data augmentation
- batch Norm
평가 결과
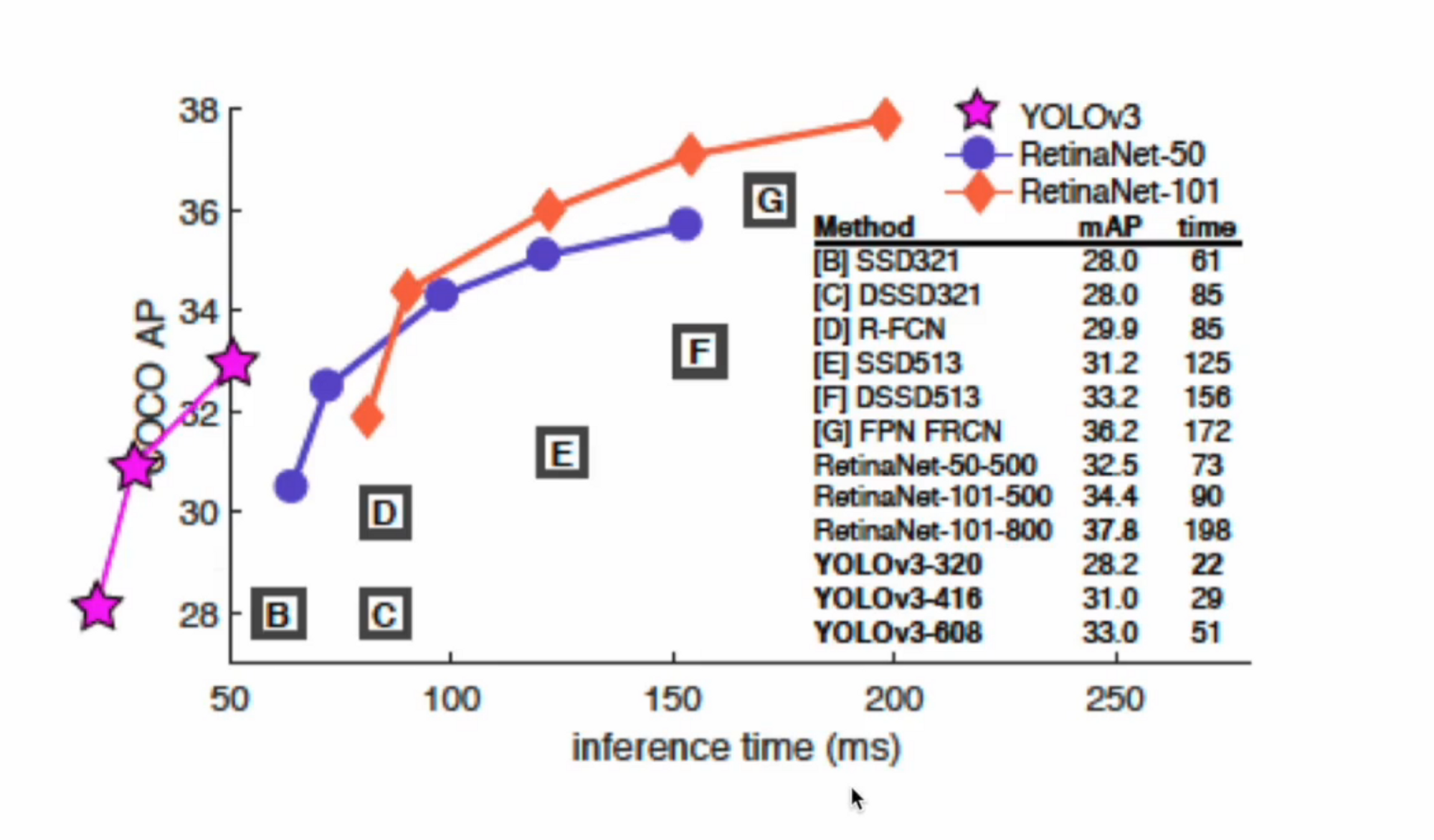
COCO 데이터를 이용한 성능 검증
inference time ( 추론 속도 )은 작을수록 좋은데 성능표를 보면 다른 모델에 비해 상당히 시간이 적게 소요되는 것을 확인할 수 있네요.
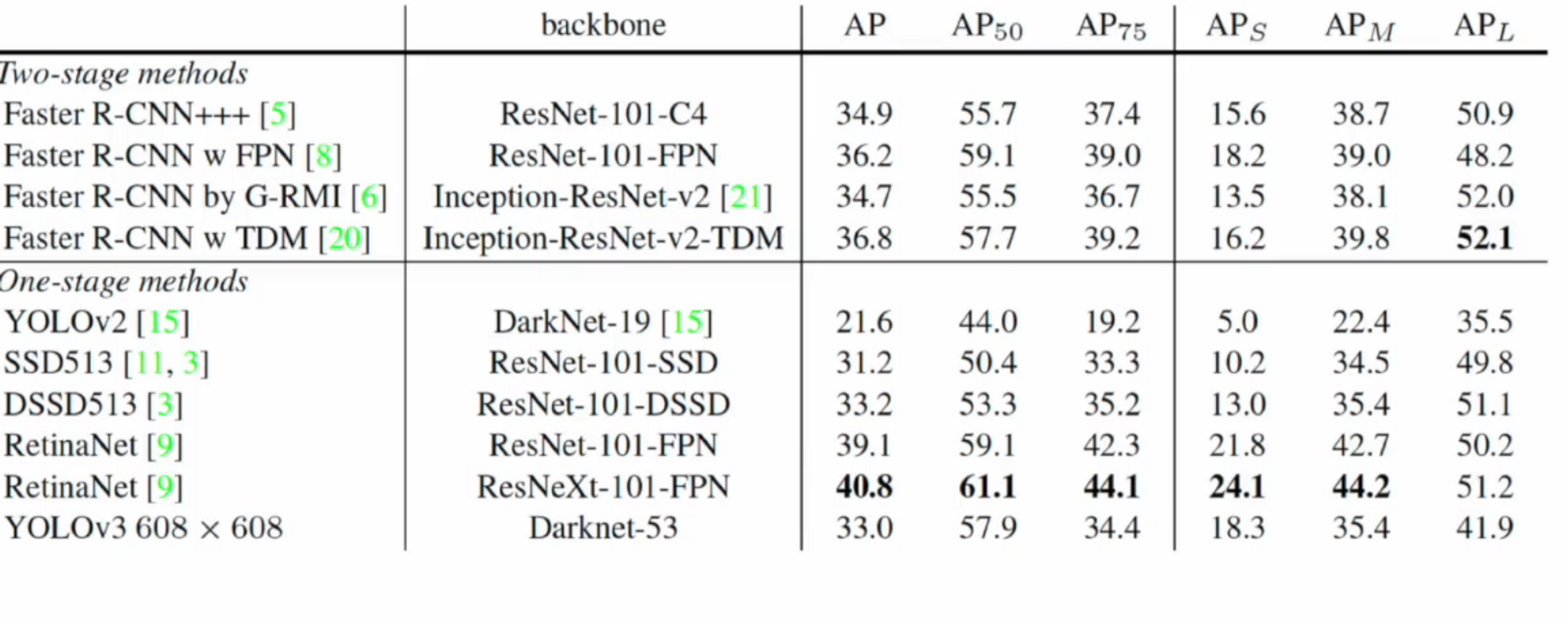
AP를 여러가지 종류로 나눠서 평가를 진행했습니다.
AP는 IoU가 50%~95%까지의 10개를 구한 뒤 평균을 낸 값.
AP50 과 AP75는 각각 IoU가 50, 75일 때 AP이고
S M L 은 객체의 사이즈입니다. Small Medium Large일 때 AP.
성능은 다른 모델에 비해서 낮은 것도 있지만, 이전 버전인 YOLOv2와 비교했을 때 성능이 개선되었네요.
결론
YOLOv3의 특징을 정리하자면
여러가지 Feature를 활용하기 위해서 Feature pyramid network를 갖다 붙혔구요
ResNet에서 사용한 Skip Connection을 이용해서 Darknet53을 만들었다는 것입니다.
마지막으로 abox를 굉장히 많이 늘렸고 성능이 조금 개선되었으나 속도는 느려졌다.
끝 !!
요약하면 YOLOv3는 속도와 일반화 기능으로 인해 컴퓨터 비전의 객체 감지 분야에 크게 기여했습니다.
자율 주행 차량, 비디오 감시 및 이미지 인식 시스템과 같은 다양한 분야에서 응용 프로그램을 찾았습니다.
그러나 특히 작거나 겹치는 물체를 감지하는 측면에서 여전히 개선의 여지가 있습니다
