ResNet(Residual Network) 모델
- 2015년 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)에서 우승한 모델
(tmi - 2등이 VGG16)
- 개요
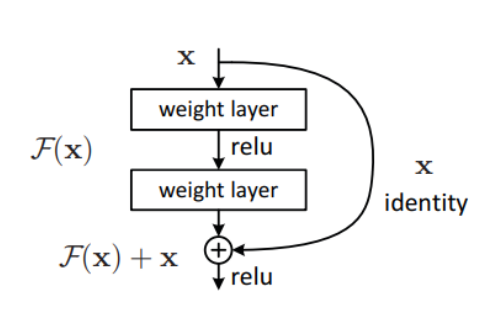
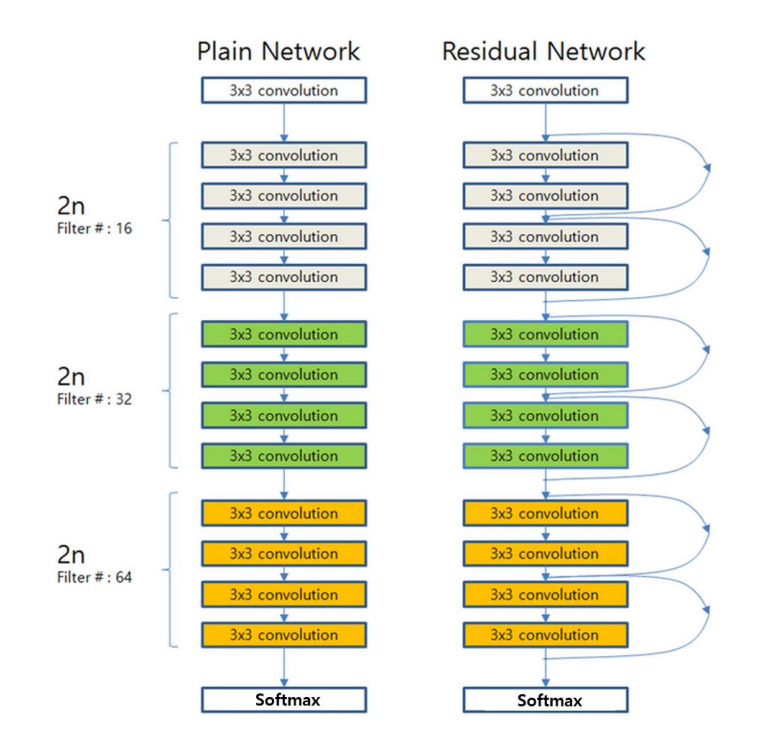
- ResNet의 핵심 : shortcut connection
- 네트워크를 깊게 쌓을 경우 발생하는 정보 소실 문제를 해결 → CNN 모델의 성능 향상에 큰 기여
- 구조
(이 시리즈의 모든 코드는 코랩환경에서 Python으로 작성하였습니다)
ResNet 모델 (증식X, 사전학습X) Code 1 (모델 생성)
# 필요한 라이브러리 임폴트
import tensorflow as tf
import os
import numpy as np# 기본 모델 가져오기
base_model = tf.keras.applications.ResNet152V2(
include_top=False,
weights=None,
input_shape=(224,224,3)
)
# 기본 모델 구조 확인하기
base_model.summary()# 재구성 모델 정의하기
# 최종 출력 units 설정
units=2
# 재구성 모델 생성
model = tf.keras.Sequential()
model.add(base_model)
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(units=256, activation='relu'))
model.add(tf.keras.layers.Dense(units=units, activation='softmax'))
# 추가 사항
model.build(input_shape=(None,224,224,3))
# 모델 구조 확인
model.summary()ResNet 모델 (증식X, 사전학습X) Code 2 (이미지 데이터 전처리)
# zip 파일 압축 해제
#!unzip '/content/drive/MyDrive/CV/cats_and_dogs.zip' -d '/content/drive/MyDrive/CV'- 압축 해제가 필요한 경우만 사용 (처음 한번)
# 이미지 폴더 경로 설정
train_path = '/content/drive/MyDrive/CV/cats_and_dogs/train'
val_path = '/content/drive/MyDrive/CV/cats_and_dogs/val'
test_path = '/content/drive/MyDrive/CV/cats_and_dogs/test'# ImageDataGenerator() 함수 실행
train_datagen1 = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1/255)
val_datagen1 = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1/255)
test_datagen1 = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1/255)# ImageDataGenerator() 함수와 flow_from_directory() 함수를 사용, 입력 데이터 생성
# 학습용 데이터 생성
train_generator1 = train_datagen1.flow_from_directory(directory=train_path,
batch_size=60,
target_size=(224,224),
class_mode='categorical')
# 검증용 데이터 생성
val_generator1 = val_datagen1.flow_from_directory(directory=val_path,
batch_size=60,
target_size=(224,224),
class_mode='categorical')
# 평가용 데이터 생성
test_generator1 = test_datagen1.flow_from_directory(directory=test_path,
batch_size=10,
target_size=(224,224),
class_mode='categorical')ResNet 모델 (증식X, 사전학습X) Code 3 (모델 학습 및 평가델 학습 및 평가)
# optimizer 재설정
optimizer = tf.keras.optimizers.Adam(learning_rate=0.0001)
# 컴파일
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])# 조기 종료 설정
early_stop = tf.keras.callbacks.EarlyStopping(
monitor='val_loss',
patience=3
)
# 학습 진행
model.fit(
train_generator1,
validation_data=(val_generator1),
epochs=100,
callbacks=[early_stop]
)# model.evaluate() 함수 사용
score = model.evaluate(test_generator1)
# 결과 확인하기
print(f'평가용 데이터에 대한 손실 : {score[0]}')
print('-'*80)
print(f'평가용 데이터에 대한 정확도 : {score[1]}')ResNet 모델 (증식O, 사전학습X) Code 1 (모델 생성)
# 재구성 모델 정의하기
# 최종 출력 units 설정
units=2
# 재구성 모델 생성
model_aug = tf.keras.Sequential()
model_aug.add(base_model)
model_aug.add(tf.keras.layers.Flatten())
model_aug.add(tf.keras.layers.Dense(units=256, activation='relu'))
model_aug.add(tf.keras.layers.Dense(units=units, activation='softmax'))
# 추가 사항
model_aug.build(input_shape=(None,224,224,3))
# 모델 구조 확인
model_aug.summary()# optimizer 재설정
optimizer = tf.keras.optimizers.Adam(learning_rate=0.0001)
# 컴파일
model_aug.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])ResNet 모델 (증식O, 사전학습X) Code 2 (이미지 데이터 증식)
# 이미지 폴더 경로 설정
train_path = '/content/drive/MyDrive/CV/cats_and_dogs/train'
val_path = '/content/drive/MyDrive/CV/cats_and_dogs/val'
test_path = '/content/drive/MyDrive/CV/cats_and_dogs/test'# ImageDataGenerator() 함수 적용
# 학습용 데이터 증식 조건 설정
train_datagen2 = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255,
rotation_range=30,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
vertical_flip=True
)
# 검증용 데이터 생성 조건 설정 --> 증식(X) + scaling(O)
val_datagen2 = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1/255)
# 평가용 데이터 생성 조건 설정 --> 증식(X) + scaling(O)
test_datagen2 = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1/255)# ImageDataGenerator() 함수와 flow_from_directory() 함수를 사용, 입력 데이터 생성
# 학습용 데이터 생성
train_generator2 = train_datagen2.flow_from_directory(directory=train_path,
batch_size=60,
target_size=(224,224),
class_mode='categorical')
# 검증용 데이터 생성
val_generator2 = val_datagen2.flow_from_directory(directory=val_path,
batch_size=60,
target_size=(224,224),
class_mode='categorical')
# 평가용 데이터 생성
test_generator2 = test_datagen2.flow_from_directory(directory=test_path,
batch_size=10,
target_size=(224,224),
class_mode='categorical')ResNet 모델 (증식O, 사전학습X) Code 3 (모델 학습 및 평가)
# 조기 종료 설정
early_stop = tf.keras.callbacks.EarlyStopping(
monitor='val_loss',
patience=3
)
# 학습 진행
model_aug.fit(
train_generator2,
validation_data=(val_generator2),
epochs=100,
callbacks=[early_stop]
)# model.evaluate() 함수 사용
score = model_aug.evaluate(test_generator2)
# 결과 확인
print(f'평가용 데이터에 대한 손실 : {score[0]}')
print('-'*80)
print(f'평가용 데이터에 대한 정확도 : {score[1]}')정확도(accuracy)가 0.5(50%)인 이유
사전 학습(Pretraining)이 없기 때문
- ResNet은 Residual Connection을 통해 네트워크의 깊이를 깊게 만들면서도 학습이 가능하도록 설계됨
- 깊은 네트워크일수록 사전 학습 없이 처음부터 학습하기 어려움 (대형 데이터셋 필요)
- Pretraining이 되어있을 경우
- 저수준 특징(Edges)부터 고수준 특징(Object Structures)까지 이미 학습된 상태에서, 새로운 데이터에 맞춰 추가 학습(Fine-tuning)만 수행하면 됨
- 즉, 각 ResNet 블록의 합성곱 필터가 사전에 학습된 특징을 활용하여 훨씬 빠르게 학습 가능
- Pretraining이 되어있지 않는 경우
- 네트워크의 모든 가중치가 랜덤하게 초기화됨
- 모델이 의미 있는 특징을 학습하지 못하고, 학습 초기에 랜덤한 출력을 생성
- 결과적으로 랜덤한 예측과 비슷한 결과(50% 정확도) 발생
참고 자료

AI & Robotics