OpenAI Clip(Contrastive Language-Image Pre-Training)
- 2021년 1월 OpenAI 논문 발표
- 학습용 데이터 : 인터넷에서 수집한 대규모 dataset(4억 개의 이미지와 텍스트(캡션))을 이용
- (이미지 : 물체 분류 label) 데이터 대신 (이미지 : 텍스트) 데이터를 사용
- (이미지 : 텍스트)로 구성된 dataset은 정해진 class label이 없기 때문에 분류 문제로 학습할 수는 없음
- N개의 이미지들과 N개의 텍스트들 사이의 올바른 연결 관계를 찾는 문제로 학습
→ Contrastive Language-Image Pre-Training

Clip 구조
- Text Encoder : Transformer
- Image Encoder : Resnet or ViT
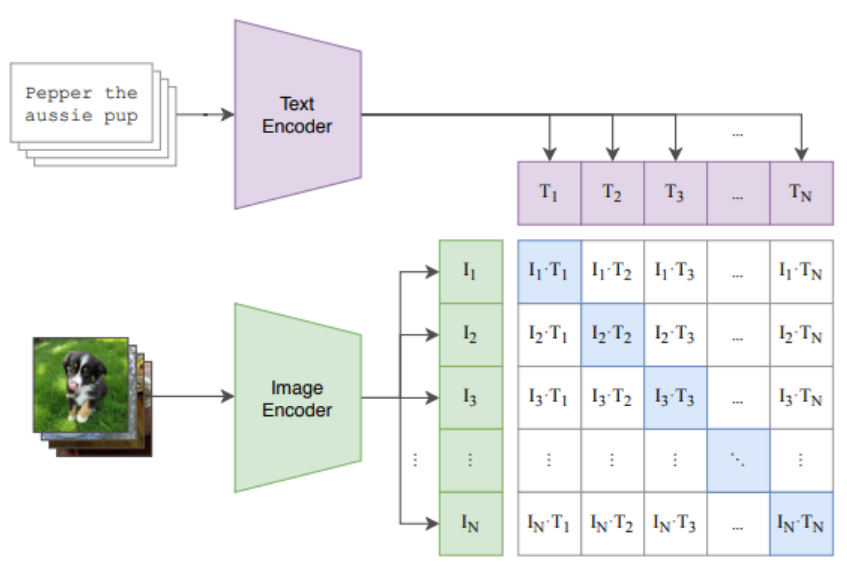
Contrastive Language-Image Pre-Training
- 이미지와 텍스트의 쌍을 생성 → 입력 data
- 입력 data : 이미지와 텍스트가 모두 유사한 경우와 이미지와 텍스트가 서로 다른 경우로 구성
- 텍스트 → Text Encoder → 임베딩 벡터 / 이미지 → Image Encoder → 임베딩 벡터
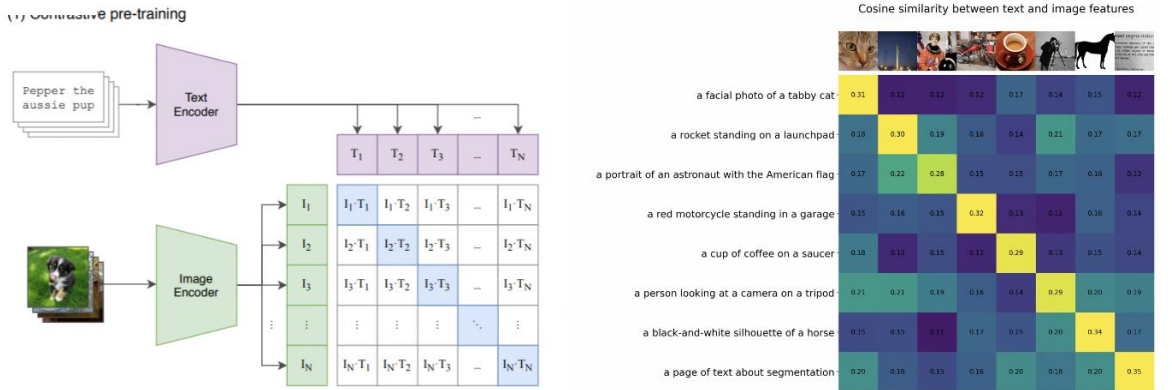
- 이미지와 텍스트의 유사도 측정
- 두 개의 샘플이 유사한 경우 코사인 유사도가 최대가 되도록 학습
- 두 개의 샘플이 다른 경우 코사인 유사도가 최소가 되도록 학습
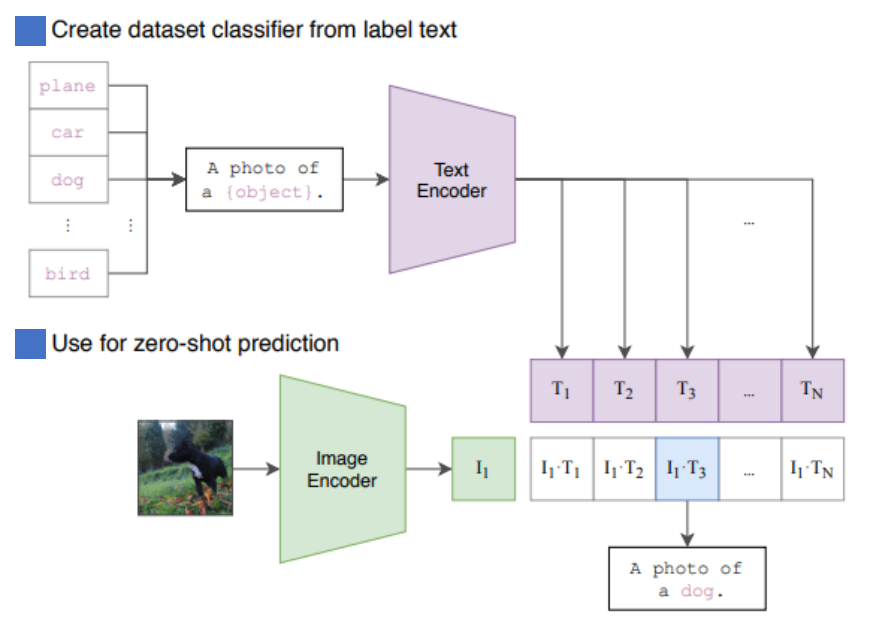
zero-shot prediction
- 한 번 학습된 Clip는 기존의 클래스 라벨 없이 새로운 이미지 분류 작업이 가능함
- 분류할 후보 텍스트 생성
- 특정 이미지를 분류하기 위해 텍스트 프롬프트(prompt)를 생성
- 일반적인 Zero-shot 분류에서는 사전 정의된 클래스를 설명하는 텍스트 리스트를 작성
- 이미지 & 텍스트 임베딩 계산
- CLIP의 이미지 인코더를 사용해 주어진 이미지 x를 이미지 임베딩 v으로 변환
- 텍스트 인코더를 사용해 후보 텍스트 문장들을 텍스트 임베딩 로 변환
- 유사도 계산 및 예측
- 이미지 v와 각 후보 텍스트 간의 코사인 유사도를 계산
- 가장 높은 유사도를 가진 텍스트가 해당 이미지의 예측 결과가 됨
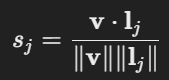
(이 시리즈의 모든 코드는 코랩환경에서 Python으로 작성하였습니다)
이미지 파일 공유
clip : zero-shot image classification Code 1 (pipeline 사용)
# pipeline 모델 생성
# 필요한 함수 임폴트
from transformers import pipeline
# 모델 생성
model_name='openai/clip-vit-large-patch14'
classifier = pipeline(task='zero-shot-image-classification', model=model_name)# 이미지와 텍스트 데이터 생성
# 필요한 함수 임폴트
from PIL import Image
# 이미지 파일 경로 설정
file_path = '/content/drive/MyDrive/CV/kimchi.jpg'
# 이미지 읽기
image = Image.open(file_path).convert("RGB")
# 이미지 설명글 생성 --> 사용자 정의 : 이미지에 대한 설명글을 제시
text = ['a photo of kimchi', 'a photo of Zha Cai', 'a photo of seasoned cabbage']
# 모델의 예측 : 어떤 설명글이 입력 이미지와 유사도가 높은지를 예측
prediction = classifier(images=image, candidate_labels=text)
# 결과 확인하기
print(f'모델의 예측 결과 : \n{prediction}')clip : zero-shot image classification Code 2 (SBERT 사용)
# 필요한 라이브러리 설치
!pip install sentence-transformers# 필요한 함수 임폴트
from sentence_transformers import SentenceTransformer
from PIL import Image
# 사전 학습된 모델 다운로드
model_name='sentence-transformers/clip-ViT-B-32'
model = SentenceTransformer(model_name)
# 이미지 파일 경로 설정
file_path = '/content/drive/MyDrive/CV/kimchi.jpg'# 이미지 설명글 생성
text = ['a photo of kimchi', 'a photo of Zha Cai', 'a photo of seasoned cabbage']
# 이미지 읽기
image = Image.open(file_path).convert("RGB")
# 이미지 --> 임베딩 벡터 추출
img_emb = model.encode(image)
print(f'이미지로부터 추출된 임베딩 벡터의 모양 : {img_emb.shape}')
print('-'*80)
# 텍스트 --> 임베딩 벡터 추출
text_emb = model.encode(text)
print(f'텍스트로부터 추출된 임베딩 행렬의 모양 : {text_emb.shape}')
print('-'*80)
# 코사인 유사도 추출
similarity_scores = model.similarity(img_emb, text_emb)
# 결과 확인하기
print(similarity_scores)- SBERT - similarity
- 이미지 임베딩 벡터와 텍스트 임베딩 벡터간의 유사도 계산이 가능
- 임베딩 벡터의 모양이 달라도 유사도 계산이 가능함
참고 자료
openai clip 공식 문서

AI & Robotics