RNN 학습 모델 생성

model 컴파일(compile)
- 개념 : 손실 함수 정의 + 최적화 함수 → 모델 완성
- 손실 함수(loss) : 모델이 계산한 예측과 정답(label)을 비교하여 손실(loss)을 계산
- 최적화 함수(optimizer) : 모델의 가중치를 업데이트하여 손실을 최소화하는 함수
- 학습 : 손실을 최소화하는 가중치 획득 과정

손실 함수(loss function)
- 손실 : 실제 데이터와 모델 예측과의 차이
- 손실의 발생 원인 : 가중치가 최적의 값이 아닐 경우 모델의 예측은 실제 값과 차이가 발생하게 됨
- 손실 함수 : 실제 데이터와 모델 예측과의 차이를 나타내는 수식
손실 함수의 종류
- 이진 분류(binary classification) : tf.keras.losses.BinaryCrossentropy
▶ model.compile(loss='binary_crossentropy')- 다중 분류(multi classification)
① tf.keras.losses.CategoricalCrossentropy() : label → One-Hot encoding
▶ model.compile(loss=‘categorical_crossentropy')
② tf.keras.losses.SparseCategoricalCrossentropy() : label → 정수 인코딩
▶ model.compile(loss=‘sparse_categorical_crossentropy’)- 평균 제곱 오차 (MSE)
① 회귀 문제에서 주로 사용
② 예측 값과 실제 값의 제곱 평균 오차를 계산- loss_weights - 손실에 대한 가중치 설정(none일 경우 랜덤)
- optimizer - 최적화 함수의 종류
- metrics - 모델의 성능을 평가할 추가적인 지표
- weighted_metrics - 메트릭의 가중치 설정 (none일 경우 랜덤)
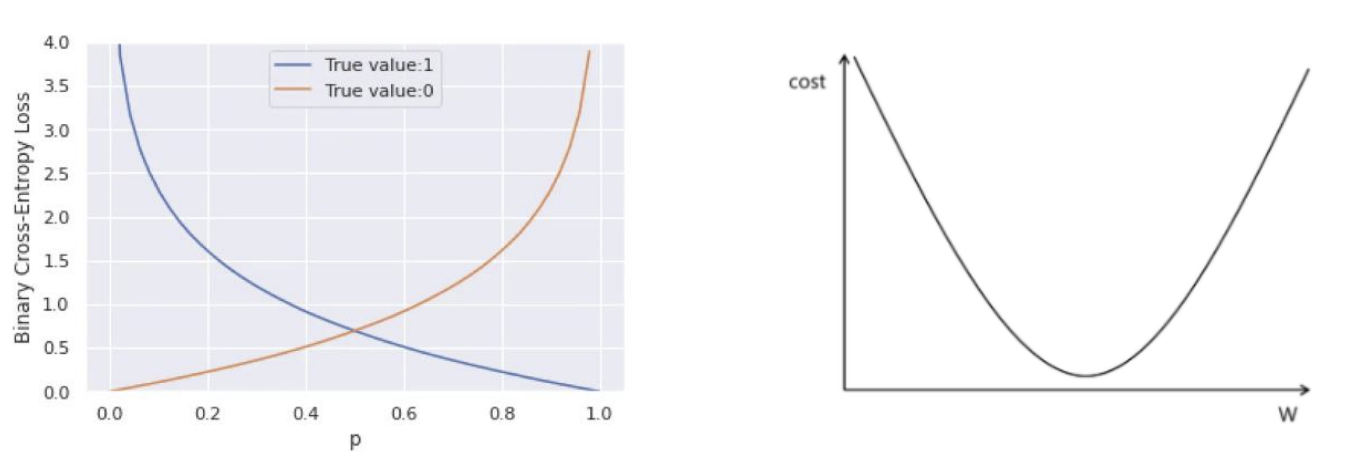
손실 함수에 대한 이해 : tf.keras.losses.BinaryCrossentropy
- 수식 :
① : 손실 값
② : 실제 레이블 (0 또는 1)
③ : 예측값 (시그모이드 함수를 통해 0과 1 사이의 실수값으로 변환된 값)- 손실 값 계산 예시
① test 데이터 : 실제 레이블이 1이고 모델이 예측한 값이 0.8이라고 가정
② ,
③ 손실 값 :- tf.keras.losses.BinaryCrossentropy
- 손실 함수 그래프 모양
최적화 함수(optimizer)
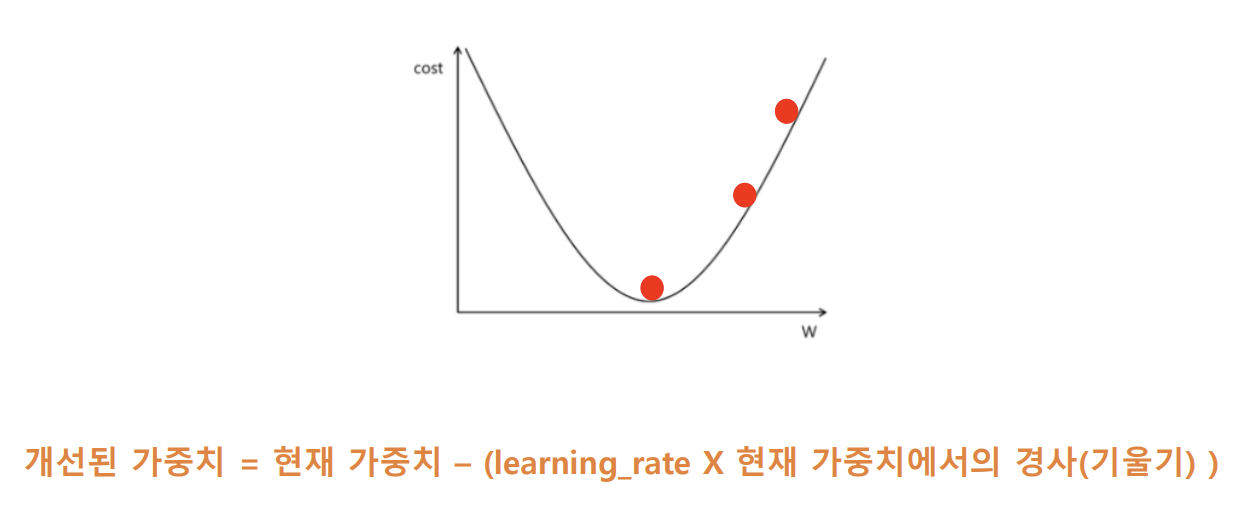
- 최적화 : 손실 함수의 값이 최소화되도록 가중치를 개선하는 것
- 최적화 함수
1) 최적화 방법을 표현하는 수식
2) 기본 : 경사 하강법
최적화 함수의 종류
- 최적화 함수 설정
optimizer = tf.keras.optimizers.Adam(learning_rate)- 모델 컴파일
model.compile(loss, optimizer='adam’, metrics)
tf.keras.Sequential.fit() 파라미터 (arguments)
- x : 행 train 데이터
- y : 열 train 데이터
- batch_size : 한 번에 학습시킬 데이터의 양 (기본값: 32)
- epochs : 학습 횟수
- verbose : 학습 과정에서 출력되는 로그 정보의 양
- 0 : 출력하지 않음
- 1 : 진행상황을 막대로 보여주며, 손실 값과 메트릭을 출력함
- 2 : 막대없이 손실 값과 메트릭을 출력함
- callbacks : 특정 조건에서 실행할 함수들(콜백) 지정 - 리스트 형식으로 저장
- validation_split : 학습 데이터의 일부를 검증 데이터로 사용하는 비율 (0.0 ~ 1.0 사이) - 뒤에서 인덱싱함
- validation_data : 따로 검증 데이터 입력 (입력 시 validation_split이 무시됨)
- shuffle : epochs마다 학습 데이터를 섞을지 결정
- True : 섞음 (기본값)
- False : 섞지 않음
- ‘batch’ : 미니 배치 단위로 데이터를 섞음
- class_weight : 클래스별로 가중치를 부여함
- sample_weight : 개별 샘플별로 가중치를 다르게 적용함
- initial_epoch : 학습이 중단된 후 다시 이어서 학습할 때의 에포크
- validation_batch_size : 검증 단계에서 사용할 배치의 크기 설정 (기본값 : batch_size)
- validation_freq : 검증을 몇 번의 에포크마다 실행할지 설정 (기본값 : 1)
tensorflow.keras.callbacks
- 딥러닝 학습 시 종료 조건이나 모델 저장 조건 등을 사용자가 원하는 대로 설정할 수 있도록 클래스와 매서드를 제공하는 모듈
- Sequential.fit의 파라미터 중 하나 > 모델 학습의 핵심
- 과대적합(과도한 학습 횟수)를 방지함
- 'val_loss' - 손실률에 따라 학습 상태 판단
- 'accuracy' - 정확도에 따라 학습 상태 판단
- verbose - 학습의 진행 사항 표시 여부 (fit(verbose)와 기능 동일) => 학습의 진행 사항을 표시할 경우 verbose=1
- EarlyStopping 클래스
① 학습의 상태를 더 이상 개선시키지 못할 경우 학습을 강제로 종료 시킬 수 있는 기능을 제공
② 사용방법
early_stop = tf.keras.callbacks.EarlyStopping(monitor='val_loss, verbose=1, patience=5)
③ 매개 변수
- monitor: 모니터링할 성능 지표
ex) ‘val_loss’을 입력할 경우, val_loss가 더 이상 감소하지 않을 경우에 작동- restore_best_weights: True로 설정하면 학습이 끝난 후, 성능이 가장 좋았던 시점의 가중치로 복원
- patience: 성능이 개선되지 않는 에포크 수. 이 수만큼 성능 개선이 없으면 학습을 중단
- ModelCheckpoint 클래스
① 학습된 모델을 저장할 때 저장 조건을 사용자가 원하는 대로 설정할 수 있는 기능 제공
② 사용방법
checkpoint = tf.keras.callbacks.ModelCheckpoint(filepath = file_path, monitor = ‘val_loss', verbose=1, save_best_only=True)
③ 매개 변수
- filepath: 모델을 저장할 파일 경로
- monitor: 모니터링할 지표
- save_weights_only: 가중치만 저장할지, 전체 모델을 저장할지 선택
- save_best_only : True 인 경우, monitor 되고 있는 값을 기준으로 가장 좋은 값으로 모델이 저장. False인 경우, 매 epoch마다 모델 저장 (model0, model1, model2....)
+ 그 외
- ReduceLROnPlateau
- 학습률(Learning Rate)이 성능이 개선되지 않을 때 감소하도록 조정함. 성능이 향상되지 않는 경우, 학습률을 감소시킴
- monitor: 모니터링할 지표
- factor: 학습률을 감소시키는 비율
- patience: 성능이 개선되지 않은 에포크 수
- min_lr: 학습률의 최소값. 이 값 이하로 학습률이 내려가지 않도록 설정
- TensorBoard : 학습 과정과 메트릭을 시각화하는 대시보드를 제공
- LearningRateScheduler : 에포크에 따라 학습률을 동적으로 조정
- CSVLogger : 학습 중 발생하는 메트릭과 손실을 CSV 파일로 기록
- TerminateOnNaN : 손실 값이 NaN일 경우 학습을 중단
- ProgbarLogger : 학습 진행 상황을 터미널에 시각적으로 표시
이 글의 코드에서 이어서 작성됩니다
RNN 학습 모델 생성 Code 1 (모델 생성)
# 모델 생성 조건
vocab_size1 = len(vocab) + 3
embedding_size1 = 32
model = tf.keras.Sequential() #기본 모델 생성
# model.add 특정 layer 추가
model.add(tf.keras.layers.Embedding(
input_dim = vocab_size1,
output_dim = embedding_size1,
)
) # Embedding layer (입력층)
model.add(tf.keras.layers.SimpleRNN(
units = 64,
)
) # RNN layer (은닉층)
model.add(tf.keras.layers.Dense(
units = 1,
activation = 'sigmoid',
)
) # Dense layer (출력층)RNN 학습 모델 생성 Code 2 (모델 compile)
# 모델 compile
adamm = tf.keras.optimizers.Adam(
learning_rate=0.0005
)
# compile() 호출
model.compile(loss='binary_crossentropy', optimizer=adamm, metrics=['accuracy'])RNN 학습 모델 생성 Code 3 (모델 학습)
# 모델 학습
# checkpoint() 함수 호출
file_path = '/content/drive/MyDrive/NLP/RNN.keras'
checkpoint = tf.keras.callbacks.ModelCheckpoint(
filepath = file_path,
monitor = 'val_loss',
verbose = 1,
save_best_only = True
)
earlystopping = tf.keras.callbacks.EarlyStopping(
monitor = 'val_loss',
patience = 5,
restore_best_weights = True
)
# fit() 함수 호출, 학습 진행
model.fit(
x = x_train_pad,
y = y_train,
batch_size = 50,
epochs = 100,
verbose = 1,
callbacks = [checkpoint, earlystopping],
validation_split = 0.2
)RNN 학습 모델 생성 Code 4 (모델 평가)
# 학습 모델 불러오기
loaded_model = tf.keras.models.load_model(file_path)
# 평가하기
result = loaded_model.evaluate(x_test_pad, y_test, verbose=1, batch_size=250)
print('loss, accuracy : ', result)참고자료

AI & Robotics