[NLP 18] BERT(Bidirectional Encoder Representations from Transformers) 2 : BertWordPiece Tokenizer
Natural Language Processing
목록 보기
18/22
[NLP 3], [NLP 4]의 추가 파트입니다
단어 단위 토큰화(tokenization)의 문제점
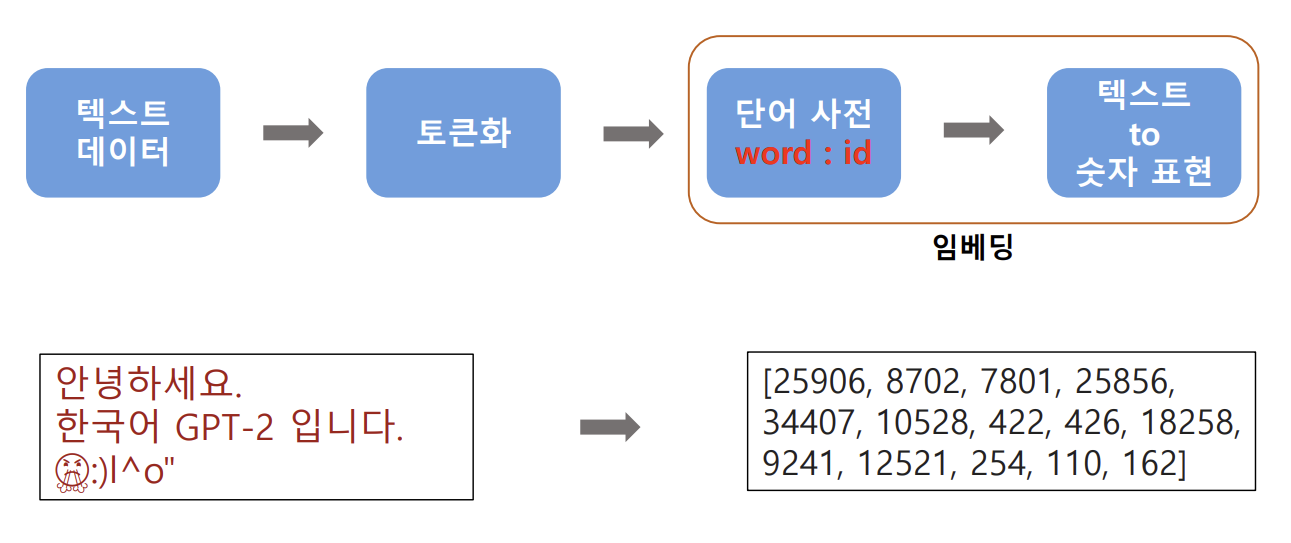
- OOV(Out-Of-Vocabulary) 문제 발생

- 신조어나 특정 상황에서의 단어의 경우 분석이 잘못 될 수 있음
- 문제점을 완화시킬 수 있는 새로운 토큰화 방법 필요
- solution : 서브 워드 단위 토큰화(subword tokenization)
- 서브 워드
- 한 단어를 구성하고 있는 문자의 조합
- 예시 : embedding → em, bed, ding
- 대표적 알고리즘 : BPE(Byte Pair Encoding) tokenization
- 다양한 subword tokenizer 모델
- Transformer : WordPiece tokenizer
- BERT : BertTokenizer
- GPT : BPE tokenizer
BPE(Byte Pair Encoding) tokenization
- text 데이터 단어단위 토큰화 (띄어쓰기 단위)
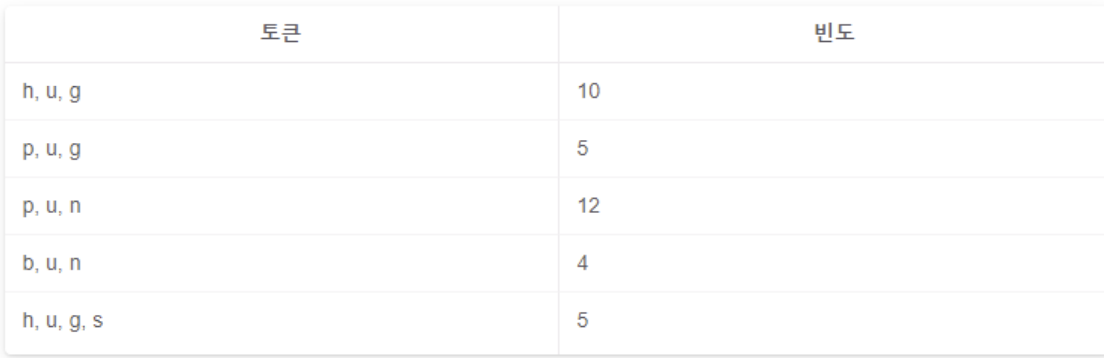
- 모든 단어들을 문자 단위로 분리
- 모든 문자를 단어사전에 등록 (초기 단어사전 등록)
- hug → h, u, g / pug → p, u, g / pun → p, u, n / bun → b, u, n / hugs → h, u, g, s
- b, g, h, n, p, s, u 7개 문자로 모든 토큰 표현 가능 → 7개 문자 → 초기 단어 사전 생성
- 각 토큰을 단어 사전의 문자로 표현
- 단어단위 토큰화 > 문자 단위로 분리
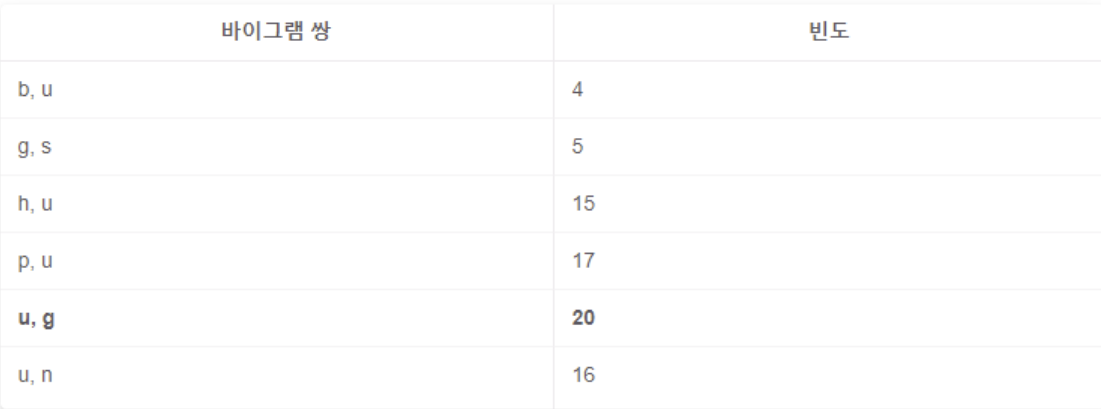
- 각 문자를 두 개(bigram) 씩 묶어 나열
- n-그램(n-gram) : 특정 순서로 인접한 n개의 기호 시퀀스
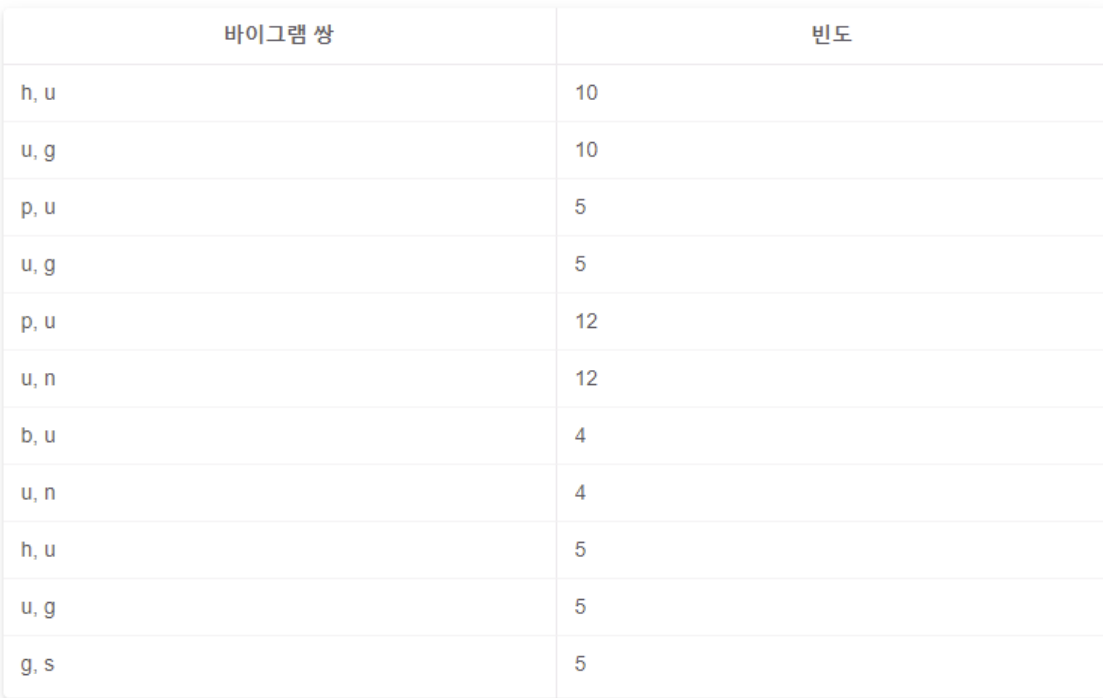
- 바이그램 쌍이 같은 것끼리 그 빈도를 합친다
- 가장 많이 등장한 바이그램 쌍은 u, g로 총 20회 → u와 g를 합친 ug를 단어 사전에 추가
- 단어 사전 업데이트 : b, g, h, n, p, s, u, ug
- 각 토큰을 새로운 단어 사전에 맞게 다시 표시
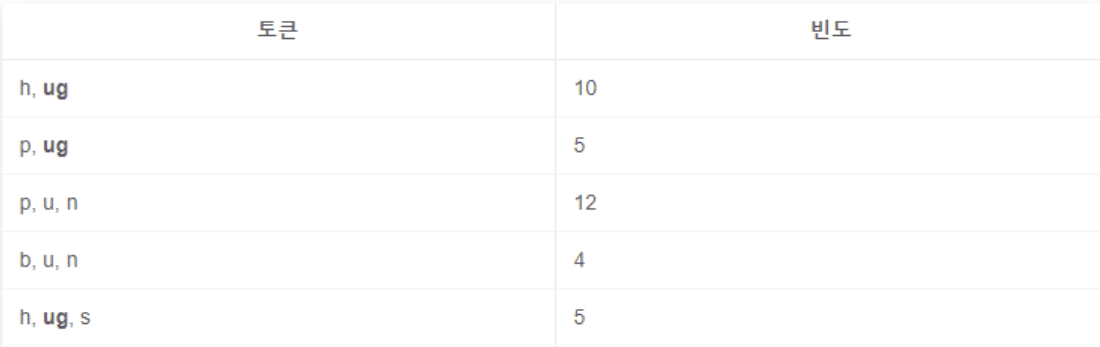
- 바이그램 쌍 빈도 계산
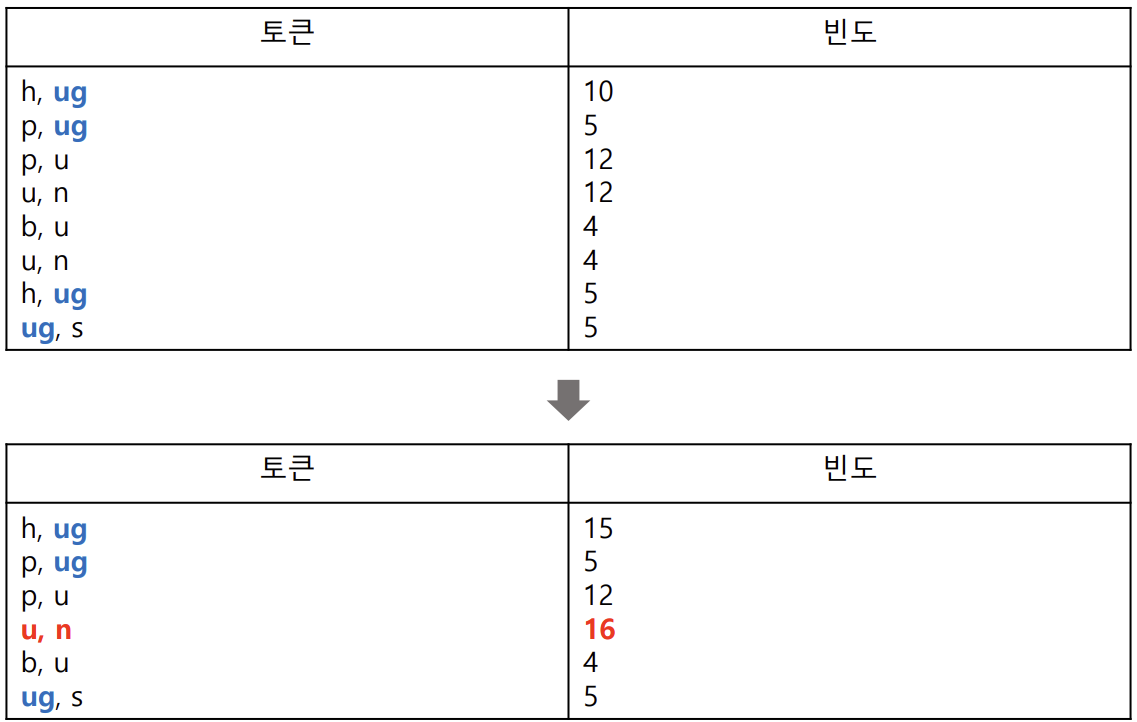
- 가장 많이 등장한 바이그램 쌍은 u, n으로 총 16회 → u와 n을 합친 un을 단어 사전에 추가
- 단어 사전 업데이트 : b, g, h, n, p, s, u, ug, un
- 각 토큰을 새로운 단어 사전에 맞게 다시 표시
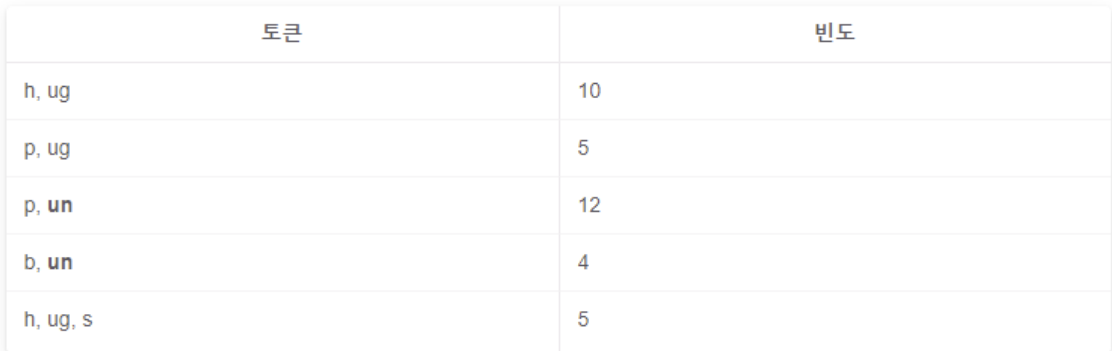
- 6번과 7번 과정 반복
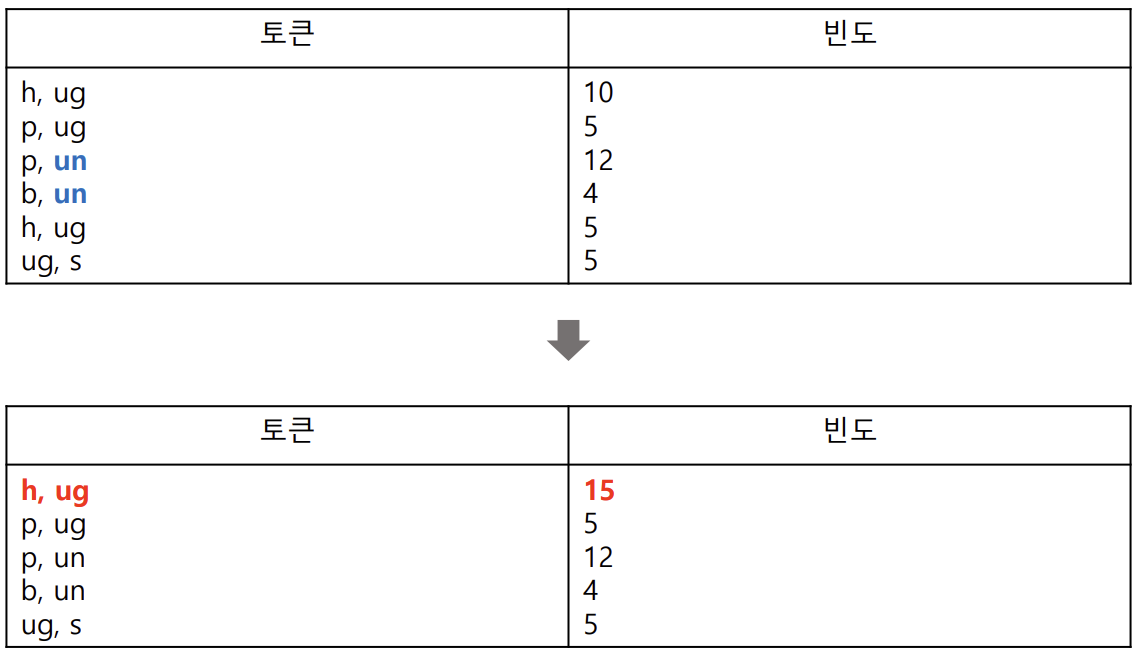



- bigram씩 묶음 > 빈도 계산 > 단어 사전 업데이트
- 원하는 어휘 집합의 크기가 될 때까지 반복(단어사전의 크기)
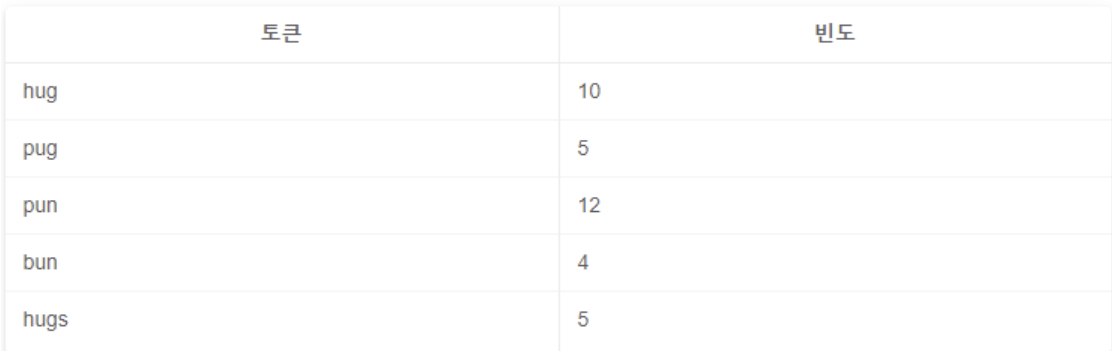
- 자주 등장하지 않는 단어 pug, bun, hugs는 서브 워드로 분리 → 단어 사전에 포함 → 최종 단어사전
- 최종 단어 사전 : b, g, h, n, p, s, u, ug, un, hug, pun
- BPE 알고리즘 → 빈도수가 가장 큰 바이그램 쌍을 병합하는 방식으로 단어 사전 구축
- 토큰화 대상 문장 입력 → 단어 사전 참조 → 단어, 서브 워드, 문자로 토큰화
(문자 > 서브워드 > 문자 순서대로 확인하며 토큰화)
BertWordPiece Tokenizer
- BERT 모델에서 사용되는 Tokenizer 중 하나
- 초기 알파벳을 포함한 작은 단어 사전에서 시작
- 학습 데이터
- 가장 빈번하게 등장하는 바이그램 쌍을 반복적으로 병합, 단어 사전 구성
- 빈도가 낮은 단어는 단어 사전에 포함되지 않고, 서브 워드로 분할되어 단어 사전에 포함
- 서브 워드의 표시 → 두 개의 해시 태그(#)를 사용
ex) 너', '##와', '함께', '##한', '시간', '모두', '눈부', '##셔', '##ᆻ다'
→ ‘##와’의 의미 : ‘##와’라는 토큰은 더 큰 단어의 일부이며, 앞 또는 뒤에 다른 서브 워드가 존재함
→ 참고 : 서브 워드이지만 가장 앞부분에 사용된 토큰(너, 함께 등)에는 해시 태그가 붙지 않음- OOV 처리 : 토큰화의 대상이 되는 문장 중 단어 사전의 단어에 해당하지 않는 단어
→ 서브 워드, 문자 단위로 토큰화
Code 개요
- naver sentiment movie corpus(nsmc) 데이터 이용
- BertWordPieceTokenizer로 토큰화
BertWordPieceTokenizer.train 파라미터
- files : 텍스트 데이터 파일 받아오기 (리스트로 여러개 가능)
- vocab_size : 단어사전의 크기 설정
- min_frequency : 입력값 미만의 빈도수인 단어는 제거
- show_progress : 학습 과정 표시 여부 (True면 표시)
- special_tokens : BERT 모델에서 사용되는 특수한 토큰들을 정의
- [PAD] : 문장 길이를 동일하게 맞춰주는 토큰
- [UNK] : 단어사전에 없는 단어가 입력 되었을때 대체하는 토큰
- [CLS] : 문장의 시작을 나타내는 토큰
- [SEP] : 문장 간의 구분을 위한 토큰 (BERT는 두 개의 문장을 동시에 입력받을 수 있기 때문에 구분해야함)
- [MASK] : Masked Language Model(MLM)에서 사용되는 토큰 (학습 과정에서 일부 단어를 가리고 해당 단어를 예측하는 작업을 할 때 사용)
(이 시리즈의 모든 코드는 코랩환경에서 Python으로 작성하였습니다)
BertWordPiece Tokenizer Code 1 (함수 임폴트 및 텍스트 생성)
# 필요한 라이브러리 설치
!pip install tokenizers# 필요한 함수 임폴트
from tokenizers import BertWordPieceTokenizer
token_min = BertWordPieceTokenizer()
token_max = BertWordPieceTokenizer()
# 텍스트 문장 생성
text = '너와 함께한 시간 모두 눈부셨다. 날이 좋아서 날이 좋지 않아서 날이 적당해서 모든 날이 좋았다.'BertWordPiece Tokenizer Code 2 (vocab_size = 5000에 대한 모델 적용)
# 단어 사전 생성 (min)
file_path = '/content/drive/MyDrive/NLP/nsmc.txt'
token_min.train(
files = file_path,
vocab_size = 5000,
min_frequency = 2
)#생성된 단어 사전 불러오기
vocab_min = token_min.get_vocab()
sorted_vocab1 = dict(sorted(vocab_min.items(), key=lambda x:x[1]))
vocab_min = sorted_vocab1
print(vocab_min)# 토큰화 모델 적용 (vocab_size = 5000)
# text > 단어사전 토큰 이용 > 토큰화 + 인덱스 > 정수 인코딩
encode_min = token_min.encode(text)
print(encode_min)
print(encode_min.tokens)BertWordPiece Tokenizer Code 3 (vocab_size = 20000에 대한 모델 적용)
# 단어 사전 생성 (max)
file_path = '/content/drive/MyDrive/NLP/nsmc.txt'
token_max.train(
files = file_path,
vocab_size = 20000,
min_frequency = 2
)#생성된 단어 사전 불러오기
vocab_max = token_max.get_vocab()
sorted_vocab1 = dict(sorted(vocab_max.items(), key=lambda x:x[1]))
vocab_max = sorted_vocab1
print(vocab_max)# 토큰화 모델 적용 (vocab_size = 20000)
# text > 단어사전 토큰 이용 > 토큰화 + 인덱스 > 정수 인코딩
encode_max = token_max.encode(text)
print(encode_max)
print(encode_max.tokens)참고자료

AI & Robotics