CLASSIC: Continual and Contrastive Learning of Aspect Sentiment Classification Tasks
continual-learning
목록 보기
3/16
CLASSIC: Continual and Contrastive Learning of Aspect Sentiment Classification Tasks
EMNLP 2021
분야 및 배경지식
Continual Learning, Contrastive Learning
- Continual Learning
- 일련의 태스크들을 연속적으로 학습하는 방식
- 일반적으로 학습이 진행됨에 따라 이전 단계에 사용된 학습 데이터들은 삭제, 데이터 프라이버시 등이 중요한 경우 유용한 세팅
- Class Incremental Learning(CIL): 겹치지 않는 클래스(=target, 예를 들어 감정분류의 경우 화남, 슬픔, 기쁨, 안도.. 등의 감정들(예측값))들을 학습)
- Task Incremental Learning(TIL): 각각의 태스크에 대해 학습, 태스크 정보 필요
- Domain Incremental Learning(DIL): 모든 태스크들은 고정된 클래스들을 공유, 태스크 정보 불필요) 등으로 구분할 수도 있음
- Contrastive Learning
- 기존의 Contrastive Learning은 존재하는 데이터에 다양한 변형을 거침 (예: 이미지 데이터의 경우 회전 혹은 자르기)
- 하지만 해당 논문에서는 이전 태스크 모델로부터 hidden space information을 활용해 explicit knowledge transfer and distillation을 위한 view를 생성
- Contrastive learning uses multiple views of the existing data for representation learning to group similar data together and push dissimilar data far away
문제점
- 기존 CL 연구는 catastrophic forgetting 극복 노력, 태스크들 간의 일반화 성능 향상을 위한 knowledge transfer 연구 부족
해결책
CLASSIC (Continual and contrastive Learning for ASpect SentIment Classification)
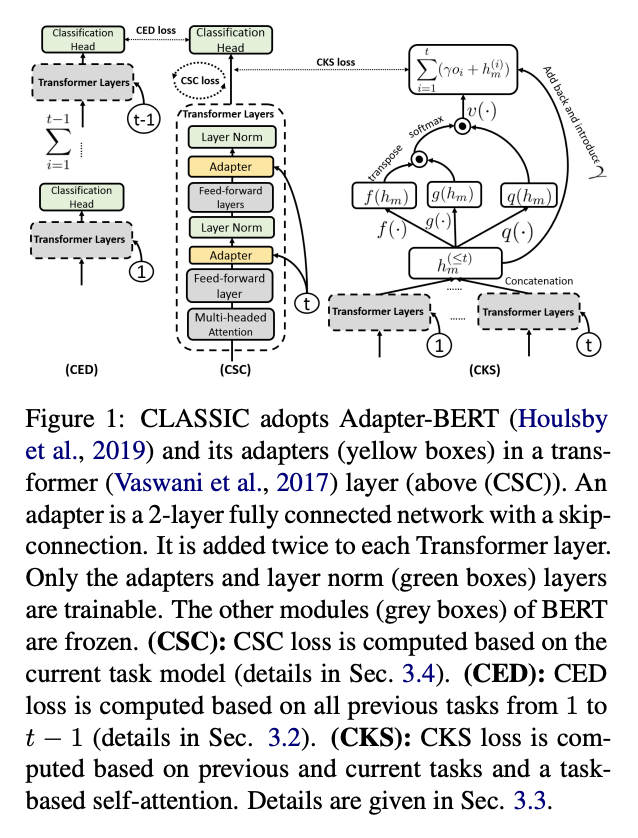
- Adapter-BERT 구조를 활용하여 adapter와 normalization layer만 업데이트되도록 학습, input으로는 hidden states와 task-id 사용 (테스트 시에는 task-id 불필요)
- CKS (Contrastive Knowledge Sharing) for Knowledge Transfer across tasks
- 모든 태스크의 정확성을 향상시키기 위해 공유 가능한 지식을 전이
- 아래의 CED loss와 다르게 class information을 사용, 두 샘플이 동일한 클래스 레이블을 가졌는지에 의해 여러 개의 positive pairs를 가질 수 있음
- CED (Contrastive Ensemble Distillation) for Knowledge Distillation
- Task Mask 사용, 태스크 특화 지식을 보호하여 catastrophic forgetting을 피할 수 있도록 함
- 이전 태스크에서 새로운 태스크에 지식을 distill(공유 가능한 것과 공유 가능하지 않은 것 모두), 새로운/마지막 태스크 모델이 모든 태스크에 대해 분류 수행 가능해 태스크 정보(즉, 태스크 아이디)가 필요하지 않도록 함
- previous task models = teacher networks, current task model = student network
- CSC (Contrastive Supervised Learning for current task model)
- 현재 태스크 모델의 정확도를 개선
- 최종적으로 loss는 cross entropy loss + 람다 CSC loss + 람다 CED loss + 람다 * CKS loss로 구성됨 (람다는 각기 다름)
평가
- 태스크
- Aspect Sentiment Classification
- 예를 들어 핸드폰 리뷰에서 '소리 품질은 안 좋다'라고 한다면 sound quality라는 aspect에 대해 부정으로 감정 분류 가능
- 데이터셋
- 19개 ASC dataset
- HL5Domains, Liu3Domains, Ding9Domains, SemEval14
- metrics
- 정확도, Macro-F1
한계
- Aspect Sentiment Classification이라는 굉장히 특정한 태스크에 국한된 방식
- DIL의 경우 task-id가 없는 게 일반적이라고 알고 있는데, 과연 knowledge distillation 방식의 사용이 test 시 task-id를 불필요하게 만드는 데에 얼마나 일조했는가 (다른 방식으로도 가능하지 않을까?)
의의
- Continual Learning에 Contrastive Learning을 새로이 접목
- 태스크들 사이에 지식전이(knowledge transfer)뿐만 아니라 이전 태스크에서 새로운 태스크에 knowledge distillation을 진행해 task-id의 필요성을 없앰 (일반적으로 Task-incremental CL에서는 task-id가 필요, 해당 연구는 DIL)
- CL, Non-CL setting을 모두 포함해 약 46개의 baseline에 대해서 폭넓은 실험 진행
- forward trasnfer, backward transfer에 대해 모두 효과적임을 보임
- forward: 이전에 배운 지식이 새로 배우는 태스크의 성능 향상에 도움을 주는 경우
- backward: 새로 배운 지식이 이전에 배운 태스크의 성능 향상에 도움을 주는 경우)

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab