Continual Learning for Text Classification with Information Disentanglement Based Regularization
continual-learning
목록 보기
4/16
Continual Learning for Text Classification with Information Disentanglement Based Regularization
NAACL 2021
분야 및 배경지식
- Continual Learning
- replay-based
- seen tasks의 정보를 모델에게 리마인드
- experience replay, distillation, representation alignment, synthesized with generative models 등이 있음
- 큰 메모리 비용 혹은 상당한 학습 시간을 필요로 함
- regularization-based
- 모델의 결과값, hidden space, 혹은 파라미터를 규제해 기존의 지식으로부터 너무 큰 변화가 일어나지 않도록 함
- 모든 정보를 동일하게 처리/규제해 새로운 태스크에 대한 일반화에 실패하는 경우 발생
- architecture-based
- 다른 태스크를 모델의 다른 요소(components of model)에 연결, 새로운 태스크와 예전 태스크 사이에 간섭을 최소화
- meta-learning-based
- 태스크들 사이의 지식 전이를 직접적으로 최적화하거나, 강건한 데이터 representation을 학습
- replay-based
- Multi-Task Learning
- 모든 학습 데이터를 저장, 새로운 태스크 학습 시 기존의 모든 학습데이터도 함께 학습
- 종종 CL의 upperbound로 여겨지곤 하나 효율성이 떨어지고 비현실적이라는 점에서 배포가 어려움
- Transfer Learning
- 전이학습
- 오직 목표 태스크에 대해서만 초점을 맞추며 catastrophic forgetting (새로운 태스크 학습 시 이전에 학습한 태스크의 지식을 까먹는 현상)에 대한 고려 없음
문제점
- 기존 CL은 이전 태스크로부터 얻은 지식을 보존하는 데에 초점, 새로운 태스크에 대해 잘 일반화하는 데에 대한 연구는 미비
- 일반적인 정보와 태스크 특화 정보가 다르게 처리되어야 함
해결책
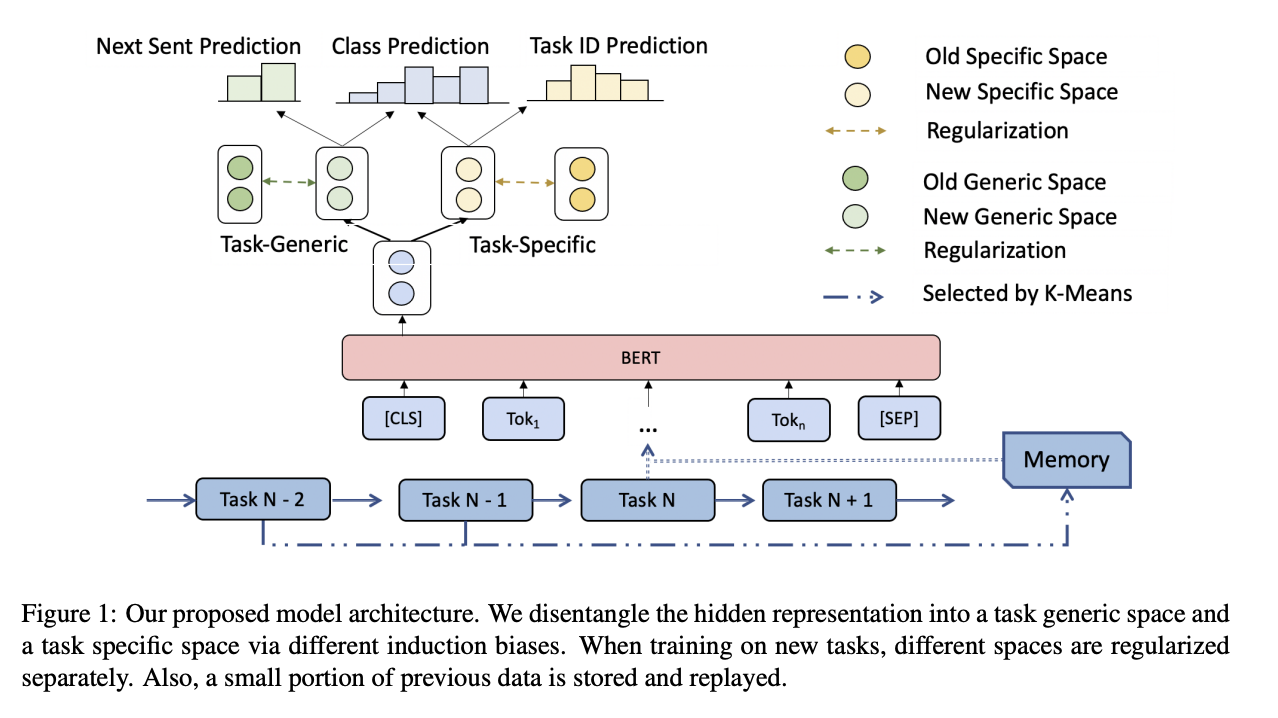
Information disentanglement based regularization method
- Information Disentanglement
- 모든 태스크에 대해 일반적인 representation과 각 태스크에 특화된 representation으로 hidden space를 구분
- hidden representation을 얻기 위한 multi-layer encoder와 2개의 disentanglement(분리) networks를 활용해 아래서 소개한 2개의 auxiliary tasks를 통해 task-generic, task-specific information 구분
- 2 Auxiliary tasks
- next sentence prediction(다음 문장 예측)
- task-id prediction(태스크 아이디 예측)
- 각각 generic(일반적인) / specific(특정한) representation spaces를 학습하기 위해 수행
- Regularization
- 일반화하는 데에 필요로 하는 지식을 다르게 제한할 수 있도록 representations를 다른 정도로 규제(regularization; 정규화)
- Replay
- 대표적인 예시들의 일부를 저장하고 학습 시 반복함으로써 성능 향상 기여
- 저장된 예시들이 다양성과 대표성을 만족시키기 위해 K-means를 사용해 샘플 선정
평가
- 태스크
- Text Classification (task-generic representation과 task-specific representation을 결합해 분류 실행)
- 3개의 태스크 연속학습 & 5개의 태스크 연속학습에 관련해 실험 진행 (순서 다양)
- 데이터셋
- 5개 분류 데이터셋(AG News, Yelp, DBPedia, Amazon, Yahoo! Answer)
한계
- objective function이 5개의 loss function의 조합으로 이루어짐, 상호 간 trade-off는 없을지 확인 필요
의의
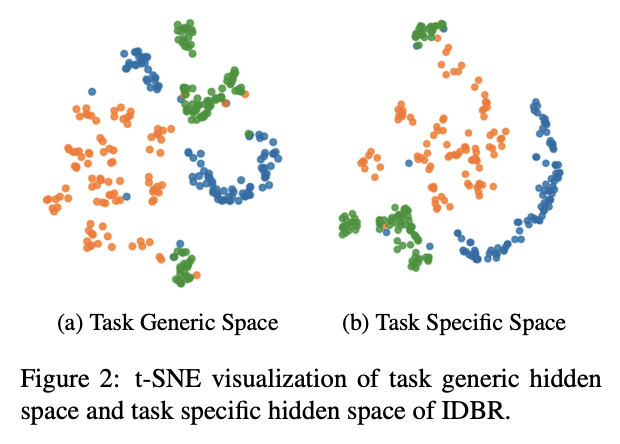
- experience replay에 기반한 단순한 regularization이 NLP의 연속학습에 있어서 강건한 방법임을 밝힘
- 학습하는 태스크의 개수가 늘어날수록 catastrophic forgetting이 심해짐을 밝힘
- t-SNE를 활용하여 task-generic representation과 task-specific representation을 시각적으로 표현

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab