Continual Few-shot Relation Learning via Embedding Space Regularization and Data Augmentation
continual-learning
목록 보기
10/16
Continual Few-shot Relation Learning via Embedding Space Regularization and Data Augmentation
ACL 2022
분야 및 배경지식
Continual Learning, Few-shot Learning, Relation Extraction
- Relation Extraction
- 한 문장의 두 개체 사이의 관계를 파악하는 문제. 질의응답이나 검색과 같은 downstream task 수행에 있어 중요한 역할
- Continual Learning
- 일련의 태스크를 연속해서 학습하는 방법
- regularization-based, architecture-based, memory-based 방법으로 크게 구분할 수 있음.
- 이전에 얻은 지식을 활용함으로써 새로운 환경이나 태스크에 빠르게 적응하는 것이 CL의 주요 목표 중 하나
- Few-shot Learning
- 몇 개의 labeled data를 학습함으로써 태스크를 푸는 방법으로, 과적합의 위험이 존재
- data-based: 이전의 지식을 활용해 데이터를 증가
- model-based: 이전의 지식을 활용하여 hypothesis space를 줄임
- algorithm-based: 전체 hypothesis space에서 최고의 hypothesis를 찾을 수 있는 적합한 전략을 찾음
문제점
- 기존의 CL은 충분한 labeled 학습 데이터에 의존하나 실제 상황에서 large representative labeled data 확보하는 것은 시간과 비용이 많이 듦
- few-shot data로 학습 시 overfitting(과적합) 문제 + 새로운 데이터의 feature distribution과 이전에 학습된 데이터의 embedding space가 다를 시 distortion 발생 가능
해결책
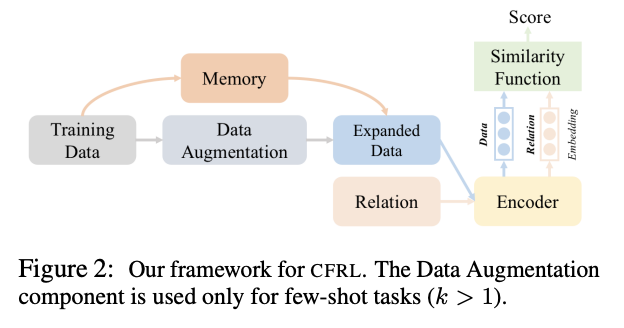
Continual Few-shot Relation Learning (CFRL)
- 이전에 학습한 내용을 잊지 않음 (alleviating catastrophic forgetting)
- 새로운 few-shot task에 충분히 일반화 가능
- 새로운 관계형(relation type)은 계속해서 만들어지기 때문에 CL 필요
Embedding space Regularization and Data Augmentation (ERDA)
- embedding space regularization: cross entropy loss를 활용하여 새로운 관계정보를 학습하는 기존의 비용함수에 더하여 새로운 regularization(규제)을 추가
- multi-margin loss: 예시와 실제 정답 사이의 점수는 증가시키고, 잘못된 레이블에 대한 점수는 낮추기 위한 loss. intra-class compactness를 보장하는 동시에 inter-class distance 증가
- pairwirse margin loss: 예시와 실제 정답 사이의 점수는 증가시키고, 잘못된 레이블에 대한 점수는 낮추기 위한 loss. 가장 가까운 잘못된 레이블의 유사도가 정답 레이블의 점수보다 높을 때 penalize
- contrastive loss: 제한된 데이터를 이용해 효율적으로 배우기 위해 hard negative sample을 활용. 모델이 더욱 정확하고 섬세하게 관계 지식을 학습할 수 있도록 hard negative로부터 적절한 관계를 구별 (hard negative는 entity pair에서 오직 하나만 다른 경우를 의미)
- memory: 새로운 관계 당 하나의 샘플을 선택. centroid feature c에 가장 가까운 예시를 가장 많은 정보를 담은 샘플로 선택, 메모리에 저장
- self-supervised data augmentation: 파인튜닝된 BERT를 사용해 label이 없는 Wikipedia 코퍼스로부터 높은 관계 유사 점수(relational similarity score)를 가진 믿을 만한 샘플을 선택
- Entity Matching을 통한 Augmentation: 개체쌍을 추출, 일정한 threshold 이상의 유사도를 가진 쌍을 선택
- Similarity Search를 통한 Augmentation: entity matching이 실패할 경우, Faiss를 이용해 top-K의 가장 높은 유사 점수를 가진 representation을 활용
평가
- 태스크: Relation Extraction
- 벤치마크: FewRel, TACRED
- metrics: relation classification accuracy
한계
- 기존 CL의 방법인 regularization과 널리 쓰이는 data augmentation을 활용, novelty 부족
의의
- 다른 baseline 대비 뛰어난 성능
- embedding space에 새로운 loss들을 적용해 (2 marginal losses, 1 contrastive loss) 성능 향상

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab