LFPT5: A Unified Framework for Lifelong Few-shot Language Learning Based on Prompt Tuning of T5
continual-learning
목록 보기
11/16
LFPT5: A Unified Framework for Lifelong Few-shot Language Learning Based on Prompt Tuning of T5
ICLR 2022
분야 및 배경지식
Lifelong Learning, Few-shot Learning, Prompt-based Learning
- Lifelong Learning (=Continual Leargning)
- 다른 데이터 분포를 가진 일련의 태스크들로부터 연속적으로 학습
- catastrophic forgetting(이전에 배운 지식을 까먹는 현상)을 완화하는 것이 주요한 목표
- architecture-based, regularization-based, memory-based 방법들이 존재
- Few-shot Learning
- 적은 수의 labeled examples로 태스크를 학습
- overfitting(과적합) 발생 가능
- Prompt-based Learning
- 일반적으로 PL은 task-specific template(=prompt)를 더하는 방식으로 본래의 인풋을 수정
- Prompt는 주로 채워지지 않은 빈칸을 포함하고 있는데, 사전학습된 언어모델이 확률적으로 답변을 생성하게 하여 아웃풋을 결정
문제점
- 기존의 연속학습(Continual Learning)의 한계
- 충분한 양의 labeled data를 가정하나 현실 상황에서 이는 어려움
- 질의응답 형태로 변경가능한 태스크들을 주로 연구하고 sequence labelling task에 대한 연구는 부족(연구 태스크 편향)
- negative transfer에 대한 충분한 고려 없이 전체 모델을 fine-tune
- 이전의 지식을 잊지 않으면서도 새로운 few-shot task에 잘 일반화하는 모델이 필요 (Lifelong Few-shot Language Learning)
해결책
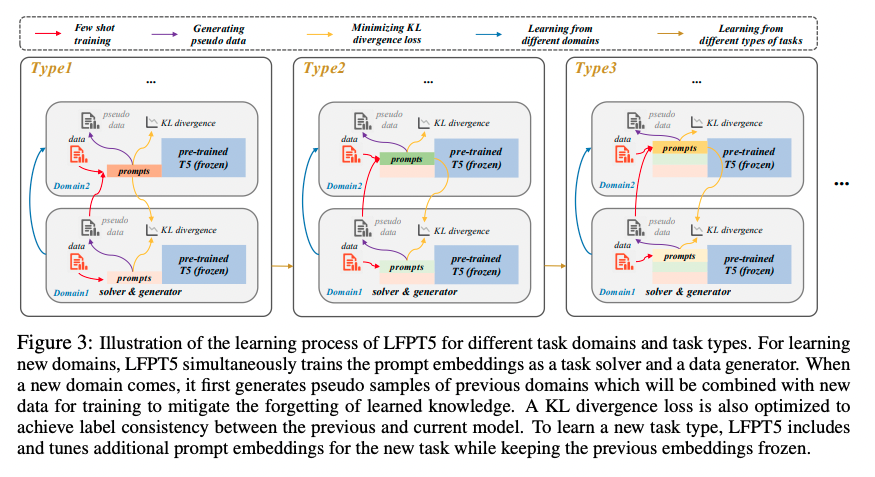
LFPT5 (Lifelong Few-shot Language Learning with Prompt Tuning of T5)
- Prompt Tuning
- T5 모델의 파라미터는 학습하지 않고 고정, meta-learned model로 활용
- task나 domain이 추가됨에 따라 prompt embedding을 학습(soft prompt tuning; 사람의 손으로 작성한 manual prompt의 경우 노동력이 필요하며, 주관적일 수 있고, 오류가 발생할 가능성이 크기 때문에 soft prompt 사용)
- Task Solver
- 해당 태스크를 풀 수 있도록 학습
- Data Generator
- regularization, architecture 방법보다 memory 방법이 더욱 뛰어난 성능을 보임
- input prompt의 generation token을 사용해 학습한 도메인의 pseudo labeled sample을 생성, 다음 학습 때 사용
- KL divergence loss
- 새로 생성한 pseudo samples와 이전 도메인의 데이터의 레이블이 일치할 수 있도록 KL divergence loss 최소화
평가
- 태스크
- sequence labeling: NER
- text classification: news, sentiment, articles into topics, qa categorization
- text generation: summarization
- 데이터셋
- CoNLL03, OntoNotes for NER
- AGNews, Amazon Review, DBPedia, Yahoo for classification
- CNNDM, Wikihow, Xsum for summarization
- 16-shot (NER and classification), 64 examples (generation) 2 samples per class or 4 samples per domain (pseudo)
- metrics
- F1, accuracy, and ROUGE respectively
한계
- summarization의 경우 다른 NER, 분류 태스크와는 다르게 다른 도메인들 사이에 지식을 전이하는 것이 어려움
- Prompt-based Tuning이 Fine-tuning based tuning보다 더 좋은 성능 보임 (새로운 도메인의 few-shot learning에서 PT-based tuning 이 더욱 뛰어남)
- 더욱 좋은 품질의 pseudo sample 생성이 필요 (future work)
- Reviewer들에 따르면, low novelty(combination of previous methods), small number of tasks/domains, not clarify advantages of their approaces compared to standard prompt tuning
의의
- 다른 태스크들뿐만 아니라 다른 도메인들에 대해서도 다양한 방면의 실험이 진행됨
- NLP의 주요한 특징 중 하나인 prompt를 CL에 접목

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab