Incremental Few-shot Text Classification with Multi-round New Classes: Formulation, Dataset & System
continual-learning
목록 보기
5/16
Incremental Few-shot Text Classification with Multi-round New Classes: Formulation, Dataset & System
NAACL 2021
분야 및 배경지식
Continual Learning, Few-shot Learning
- Using Textual Entailment for Text Classification: DNNC는 클러스터링을 기반으로 한 분류기로, discriminative nearest neighbor classification의 약자. 두 예시가 같은 클래스에 있는지 아닌지 여부를 비교
문제점
- 제한적인 수의 labeled data만 존재할 경우에도 모델은 원하는 태스크를 잘 수행해야 함
- 새로운 클래스를 지속적으로 학습할 때, 1) 이전 클래스의 예시들을 재학습하지 않아야 하며, 2) 이전 클래스들에 대한 지식을 잊지 않으면서도 3) 동시에 새로운 클래스에 대해서 성능을 보여야 함
해결책
ENTAILMENT and HYBRID
- Text Classification into Textual Entailment (ENTAILMENT)
- 인풋 x를 premise로, class y를 hypothesis로 변경
- 거대한 규모의 entailment dataset이 가진 간접적인 supervision 활용 가능하여 few-shot setting에 도움 (base class 학습 전 사전학습 시 entailment dataset 이용 가능)
- few-shot 예시뿐만 아니라 class name의 정보까지도 학습에 사용할 수 있음 (class name도 유용한 정보 포함)
- entailment pair x, y(positive, negative)를 RoBERTa를 이용해 학습
- HYBRID: ENTAILMENT와 DNNC(Zhang et al. 2020)로부터 나온 쌍(pairs)들을 활용
- base 학습에는 충분한 labeled data 사용(base class), 새로운 클래스를 학습할 때에는 오직 k개의 예시만을 사용(few-shot class), 테스트 시에는 base class, few-shot class와 더불어 학습 시 사용되지 않았던 OOD(out-of-distribution) class 사용
평가
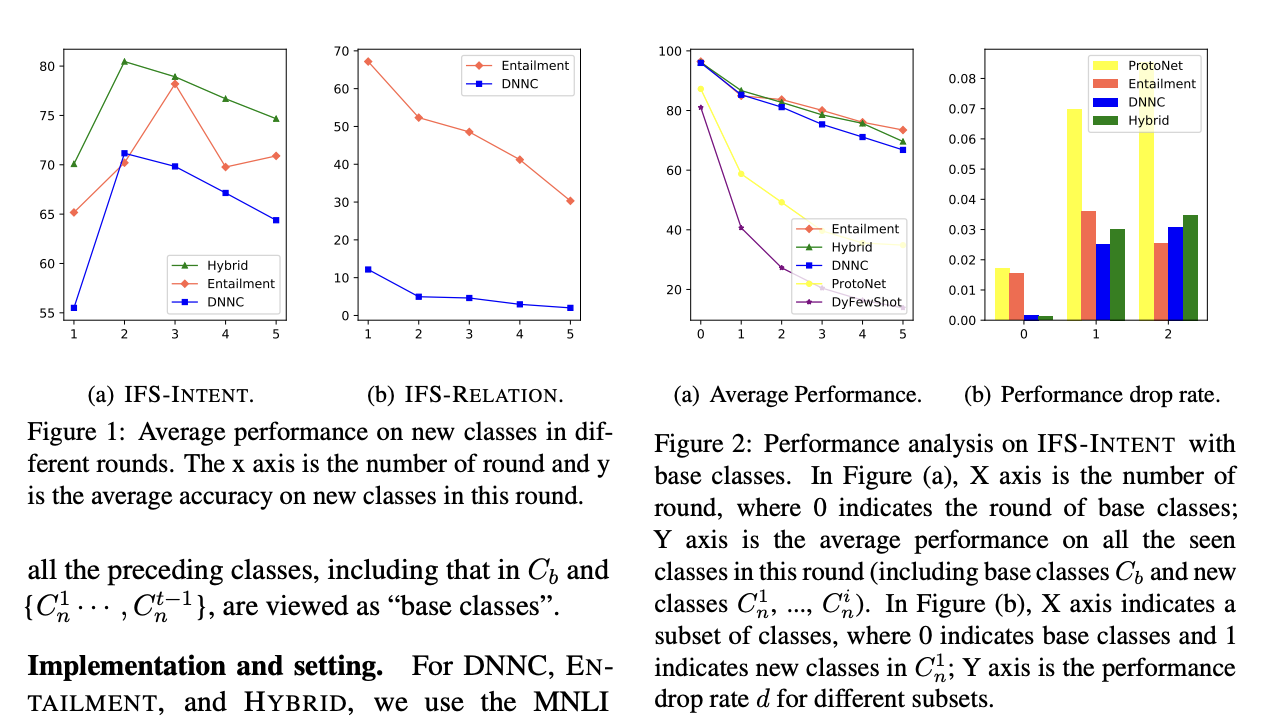
- 태스크: text classifiation (binary)
- intent detection: 사용자 쿼리의 의도를 이해
- relation classification: 주어진 문장에서 두 개체 사이의 올바른 관계를 파악
- dataset
- 사전학습(pretrain): MNLI dataset을 활용
- finetuning: IFS-INENT (converted from BANKING77 which is single domain intent detection), IFS-RELATION (converted from FewRel)
한계
- 두 개의 클래스에 대해 분류하는 binary classification 대상으로, 확장성이 아쉬움
- 기존에 연구되었던 DNNC 대비 엄청난 성능 향상이 이루어졌다고 보기 어려움
의의
- Better Performance: HYBRID가 IFS-INTENT에 대해 최고의 성능을 내며, 전반적으로 평균 성능의 감소 정도를 개선. 학습한 클래스들에 대해 ENTAILMENT와 HYBRID가 가장 좋은 성능을 냄
- Entailment가 전체 학습 클래스들의 평균 정확도에 있어서 가장 좋은 성능을 내고, DNNC는 더욱 안정적이고 더욱 낮은 성능 감소율을 보이며, 둘을 결합한 HYBRID는 두 모델의 장점을 갖고 있다는 사실을 보임

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab