Continual Sequence Generation with Adaptive Compositional Modules
ACL 2022
분야 및 배경지식
Continual Learning, Adapter
- Continual Learning
- 연속하여 다른 태스크, 도메인, 클래스 등을 학습하는 문제
- 데이터가 연속적으로 들어오며, 기존 모델이 학습한 데이터와 다른 데이터 분포를 가짐
- experience replay: 이전 학습에 사용되었던 데이터 일부를 학습에 재사용
- regularization: 학습 시 규제 추가해 심각한 왜곡이 일어나지 않도록
- parameter-isolation: 기존 파라미터는 고정, 새로운 태스크에 대해 새로운 파라미터 추가
- CL for Sequence Generation
- auto-regressive 언어모델(LM)을 기반으로 만들어진 LAMOL이 대표적
- knowledge distillation이 효과적임을 밝힘
- Adapter
- 각각의 고정된 사전학습 트랜스포머 레이어에 삽입된 태스크 특화 모듈
문제점
- Catastrophic forgetting, Knowledge Transfer
- 연속학습에서 기존의 파라미터 재사용은 유사하지 않은 태스크들에 대해 catastrophic forgetting(이전 지식을 까먹음)을 야기하며, 새로운 태스크들에 대해 새로운 파라미터를 추가하는 것은 유사한 태스크들 사이의 지식 전파(knowledge transfer)를 어렵게 함
- Continual Sequence Generation is more challenging
- 텍스트 분류, 질의응답과 같은 태스크와 다르게 시퀀스(문자열)생성은 뚜렷한 레이블(정답)이 없기 때문에 더욱 어려움
해결책
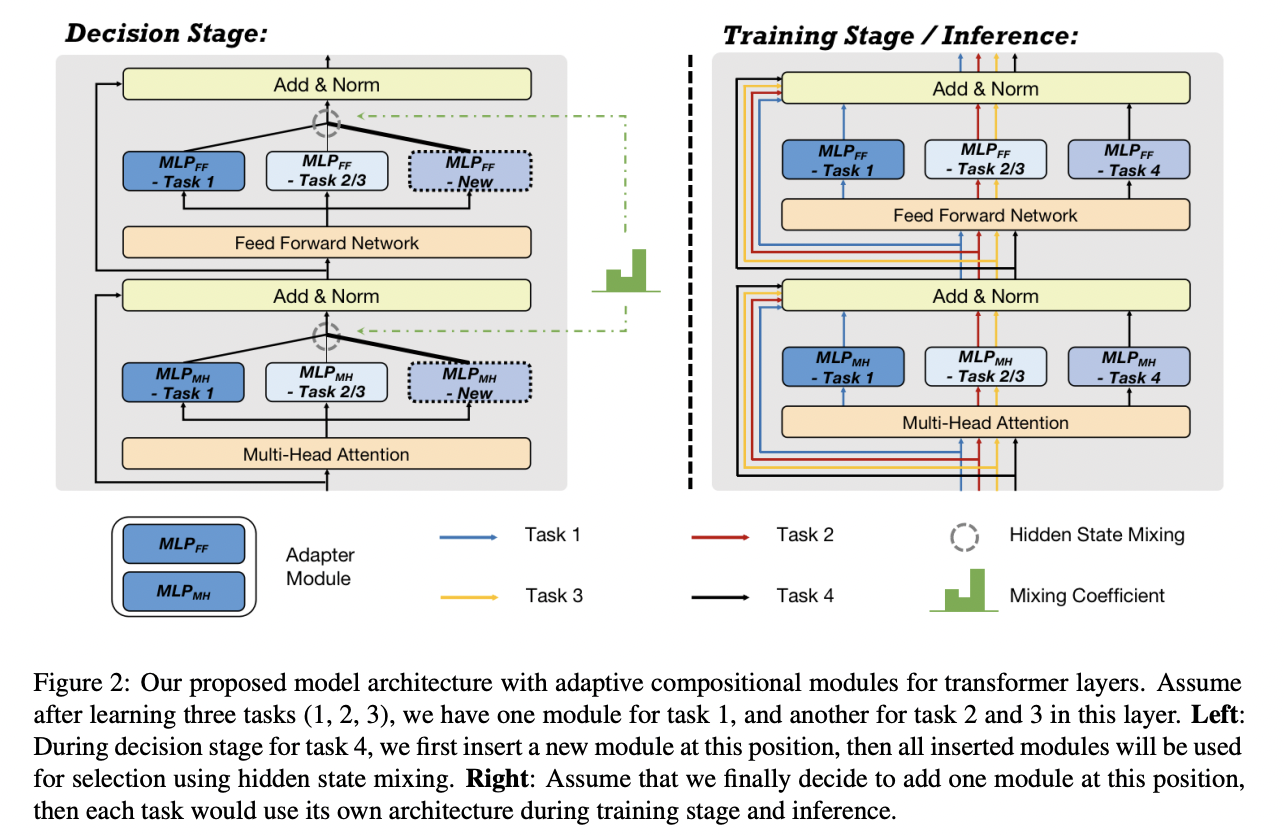
Adaptive Compositional Modules
- Decision Stage
- 어떤 모듈을 재사용하고 새로운 모듈 추가가 필요할지 여부를 결정
- 모듈 선택에는 interpolation-based data augmentation과 neural architecture search에서 영감을 받은 Hidden State Mixing 사용
- 가장 큰 learned weight를 가진 모듈이 가장 유용한 모듈이라고 판단, 재사용
- Training Stage
- 모델 아키텍처 확정 단계
- pseudo experience replay(이전 학습된 태스크와 관련있는 가짜 데이터를 만들어 현재 학습에 재사용) 사용
- 생성모델로 하여금 현재 태스크를 해결함과 동시에 현재 태스크의 예시를 만들도록(=pseudo) 학습
- 학습 loss는 finetuning loss + generation loss의 조합으로 이루어짐
평가
- 데이터셋
- E2ENLG, RNNLG for similar tasks: 유사한 태스크, 다른 도메인
- WikiSQL, CNN/DailyMail, MultiWOZ for dissimilar tasks: distribution shift가 기존과 상당히 다른 태스크
- 태스크
- 자연어 생성, SQL 쿼리 생성, 요약, 태스크 지향 대화
한계
- 재사용을 위한 모듈을 판단하기 위해서는 학습을 거쳐야 하기 때문에 추가적인 학습 시간이 필요 (decision stage)
의의
- Go beyond the notion of task-specific
- 태스크 특화 모듈을 주로 사용했던 기존의 접근 방식과 달리, 모듈 재사용을 통한 지식 전파 극대화 및 상황에 맞는 모듈 추가에 따른 이전 지식 망각 문제 완화를 동시에 달성
- 모듈의 learnable weight coefficient가 특정 레이어에서 균등한 분포를 띄지 않게 하기 위해 entorpy loss를 규제로 추가하였는데, 해당 loss가 파라미터를 추가하는 것과 좋은 성능을 내는 것 사이의 더 좋은 trade-off를 달성함을 밝힘
- weight initialization이 유사한 태스크들 사이의 지식 전파에 중요함을 밝힘
- pseudo experience replay가 성능 향상에 중요함을 밝힘

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab