Continual evaluation for lifelong learning: Identifying the stability gap
continual-learning
목록 보기
14/16
Continual evaluation for lifelong learning: Identifying the stability gap
ICLR 2023
분야 및 배경지식
연속학습 (Continual Learning, Lifelong Learning)
- 연속적으로 새로운 class, domain, 혹은 task를 학습하는 문제
- 분야에 따라 class-incremental, domain-incremental, task-incremental로 분류되기도 함
- Stability-Plasticity tradeoff (안정성-적응성 균형)
- Stability(안정성): 이전에 학습한 데이터 분포에서 얻은 지식을 유지하는 것, 이전의 지식을 까먹을 경우 catastrophic forgetting이 발생
- Plasticity(적응성): 현재 데이터 분포를 잘 학습하는 것
- 둘 사이에는 tradeoff 발생
- Methods
- memory-based (experience replay): 메모리에 학습한 샘플의 일부를 저장, 이후 학습 시 재사용
- regularization-based: L2 norm 등을 이용한 정규화 이용 (model-prior based라고 불리기도 함)
- architecture-based: adapter와 같이 특정 태스크를 위한 파라미터를 모델에 추가
문제
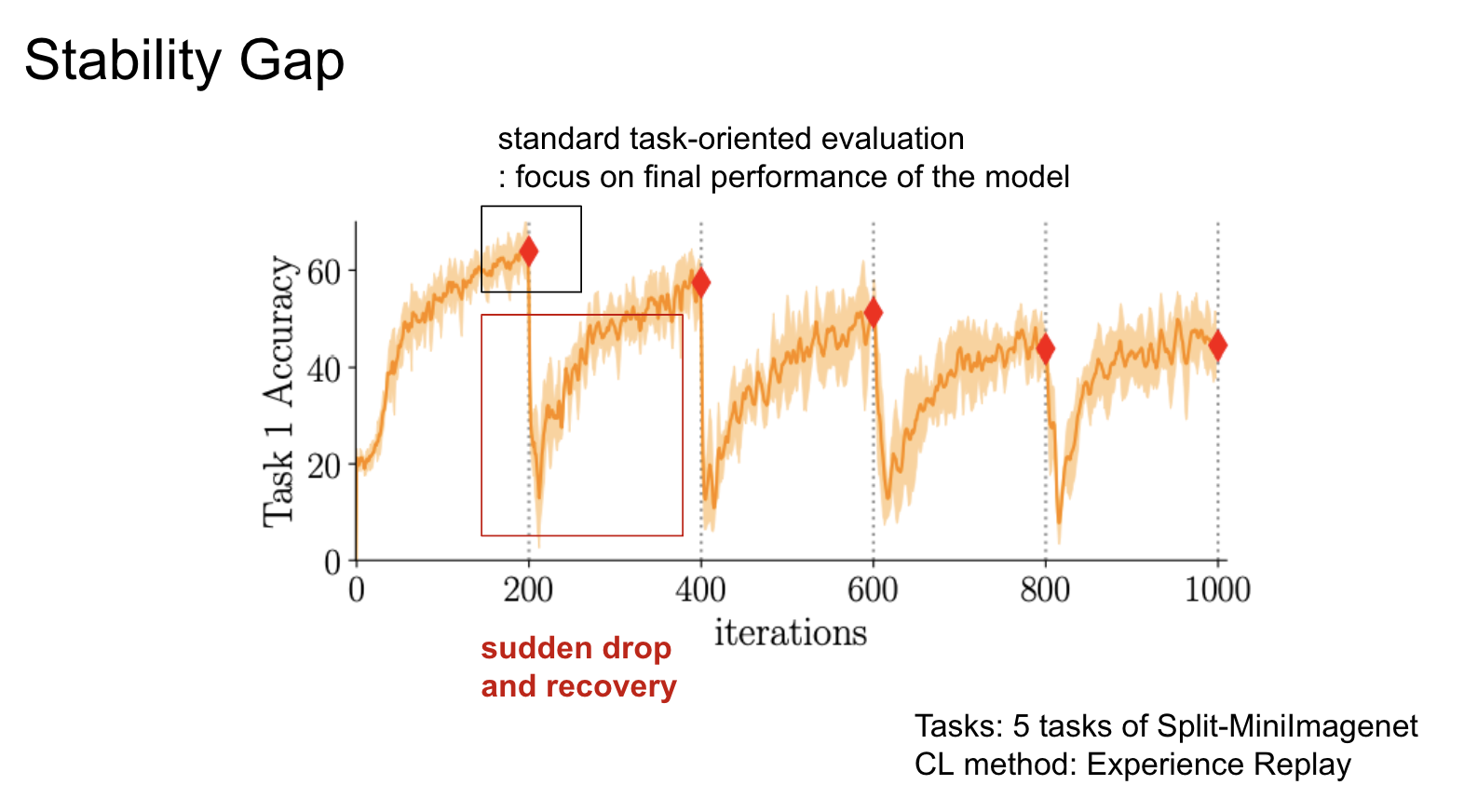
Stability Gap
- 연속학습에서 새로운 태스크를 배우기 시작할 때 기존 태스크의 성능이 일시적으로 크게 떨어지며 (substantial forgetting) 이후 성능이 다시 회복되는 현상
- 연속학습 방법들 중에서 memory-based, regularization-based, distillation 등의 방식에서 Stability Gap이 발생 (architecture-based에서는 발생 X)
해결책
Continual Evaluation
- Stability Gap을 측정하기 위한 새로운 프레임워크
- evaluation periodicity: 연속학습을 위한 평가의 인터벌, 기존의 평가들은 task의 학습이 끝나고 진행되었으나 continual evaluation에서는 iteration 단위로 더 세세하게 평가
- evaluation stream: 연속학습에 사용되는 학습 태스크(데이터셋)에 대한 평가 태스크(데이터셋)
- evaluation metrics: 평가지표
Metrics
Stability-based metrics
- 이전에 학습된 태스크에 대한 지식이 얼마나 유지되는지 평가
- 기존 평가지표
- Average Forgetting (FORG)

- 정확도 차이의 평균
- 값이 클수록 catastrophic forgetting이 큼을 의미
- Average Forgetting (FORG)
- 신규 평가지표
- Average minimum accuracy (min-ACC)

- 이전 평가 태스크들에 대한 절대적인 최소 정확도의 평균
- Windowed Forgetting (WF)

- 윈도우 사이즈 내에서 성능 하락폭이 제일 큰 경우를 측정
- 태스크 단위의 데이터 흐름을 가정하는 게 아니라, 연속적인 학습과정을 가정
- Average minimum accuracy (min-ACC)
Plasticity-based metrics
- 현재 데이터로부터 새로운 지식을 얻는 능력을 측정
- 기존 평가지표
- Learning Curve Area (few-shot measure)
- zero-shot Forward Transfer
- 신규 평가지표
- Windowed Plasticity (WP)

- 윈도우 사이즈 내에서 성능 상승폭이 제일 큰 경우를 측정
- 태스크 단위의 데이터 흐름을 가정하는 게 아니라, 연속적인 학습과정을 가정
- Windowed Plasticity (WP)
Stability-Plasticity trade-off based metrics
- 새로운 태스크에 대한 학습과 이전 태스크에 대한 지식 유지 사이의 균형을 측정
- 기존 평가지표
- Average Accuracy (ACC)
- 이전 태스크들과 현재 학습한 태스크에 대한 정확도의 평균
- Average Accuracy (ACC)
- 신규 평가지표
- Worst-case Accuracy (WC-ACC)

- 현재 태스크의 정확도와 이전 평가 태스크들의 min-ACC (최소 정확도)의 평균
- Worst-case Accuracy (WC-ACC)
평가
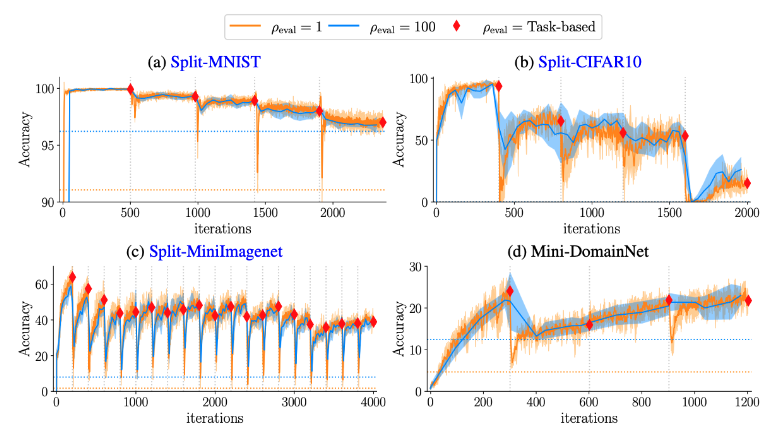
- 태스크 학습이 끝난 이후에 이전 태스크의 성능을 측정하는 것보다 더욱 세세한 주기로 평가하는 것이 stability gap을 파악하는 데에 주효
- 따라서 태스크 학습이 끝난 이후에 태스크 단위로 성능을 평가하던 기존의 평가지표는 stability gap을 파악할 수 없음
- stability gap은 데이터의 분포의 변화가 클수록(=태스크 사이의 유사성이 떨어질수록) 크게 나타남

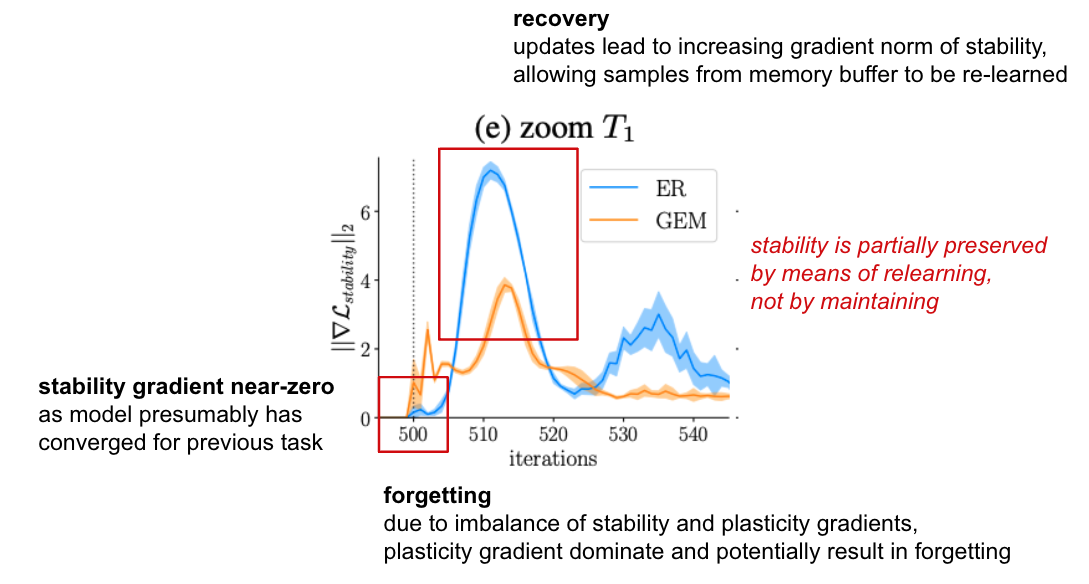
- 원인을 파악하고자 plasticity에 대한 gradient와 stability에 대한 gradient를 분리
- 새로운 태스크 학습이 시작될 때 이전 태스크에 대한 stability gradient는 0에 가까움
- 이전 태스크에 대해 모델이 학습을 통해 수렴(converge)
- forgetting: plasticity gradient와 stabiltiy gradient 사이의 불균형 때문에 (= stabilty gradient가 0에 가깝기 때문에) plasticity gradient를 감소하는 방향으로 학습이 진행, 이전 태스크에 대한 학습 비중 떨어짐
- recovery: 학습이 진행되면서 데이터 분포가 이전 태스크와 달라짐에 따라 stability gradient 증가, 재학습 이루어짐
- 이전 태스크에 대한 성능이 유지되는 것이 아니라 재학습이 이루어짐으로써 안정성이 보장됨을 주장
한계
- stability gap이라는 흥미로운 현상을 증명하고 분석하였으나 비공식적으로 학계에서는 알려져있던 intuition을 공식화한 논문
- 단순한 image dataset과 speech recognition 태스크에 한정된 분석
- stability gap을 줄일 수 있는 메커니즘에 대한 제시가 없음
의의
- stability gap이라는 독특한 현상에 대한 분석과 원인 파악
- continual evaluation이라는 새로운 프레임워크 제시
- 다양한 실험 및 자세한 분석을 바탕으로 논문이 매끄럽게 진행됨

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab