Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora
continual-learning
목록 보기
13/16
Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora
NAACL 2022
분야 및 배경지식
- Continual Learning
- catastrophic forgetting(기존의 정보를 잊는 현상)을 완화시키면서도 knowledge transfer(연속적으로 학습한 태스크들이 서로의 성능 개선에 도움을 주는 현상)가 가능하도록 태스크/도메인/클래스 등을 연속적으로 학습시키는 것
- NLP에서는 주로 분류 태스크에 대해 연구가 이루어져왔으며, 1) 과거의 예시 혹은 pseudo 예시를 저장하여 사용하거나 2) regularization을 사용하거나 3) model expansion을 사용하는 방식이 가장 널리 쓰임
문제
사전학습된 언어모델(Pretrained Language Model)은 기존에 학습한 데이터 분포와 다른 새로운 데이터 또한 잘 처리해야 함
해결책
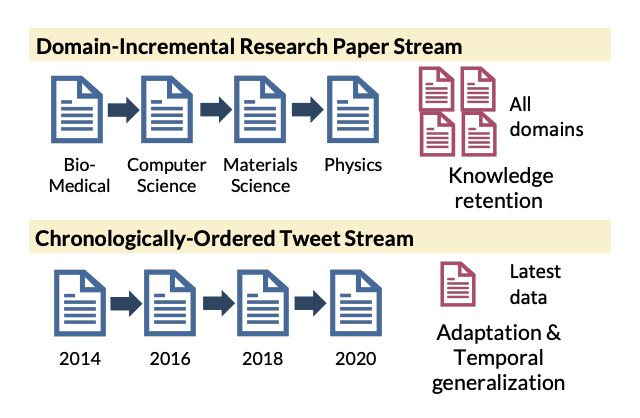
Lifelong Pretraining (연속 사전학습)
- 목표
- 연속적으로 사전학습을 수행하여 downstream task의 fine-tuning에 유용한 모델의 시작점(model initialization) 제공
- 도메인 연속학습(domain-incremental stream)
- 4개 연구분야에 대한 논문 사용(S2ORC dataset), 기존에 학습된 지식이 잘 유지되는지 여부를 판단
- 시간 연속학습(chronologically-ordered stream)
- 2014/2016/2018/2020 트윗 데이터 사용, 최신의 데이터에 대해 좋은 성능을 내는가 & 다른 시간대의 데이터에 대해서도 일반화가 잘 이루어지는가(temporal generalization) 여부를 판단
- distillation-based approach가 다른 방법들에 비해 효과적이라는 사실을 밝힘
- compared to model-expansion, regularization-based, memory replay)
- distillation 예시: logit, representation, contrastive, self-supervised(seed)
평가
- 태스크
- domain-incremental (도메인)
- 관계 도출(relation extraction)
- 개체명 인식(named entity recognition) 등
- chronologically-ordered (시간)
- multi-label 해시태그 예측
- single-label 이모지 예측
- domain-incremental (도메인)
- 데이터셋
- domain-incremental (도메인)
- Biomedical: Chemprot, RCT-Sample
- Computer Science: ACL-ARC, SciERC
- Materials Science: MNER, Synthesis
- Physics: Keyphrase, Hyponym
- chronologically-ordered (시간)
- 수집한 트윗 데이터 중 사전학습에 사용되지 않은 데이터
- domain-incremental (도메인)
- 평가지표
- domain-incremental (도메인)
- Micro-F1, Macro-F1
- MLM perplexity
- chronologically-ordered (시간)
- label-ranking average precision scores (multi-label)
- Macro-F1 (single-label)
- domain-incremental (도메인)
의의
- 기존의 연속학습에서 많이 다루는 도메인 연속학습뿐만이 아니라 시간에 대한 일반화(Temporal Generalization) 성능 또한 고려
한계
- lifelong pretraining은 나중에 학습된 도메인이 이전의 도메인으로부터 학습된 지식의 이전(knowledge transfer) 덕분에 이득을 얻는다고 분석
- 반면 먼저 학습된 도메인의 성능은 forgetting 때문에 제한적이라고 평가
- 하지만 단순히 가장 마지막에 파라미터를 학습했기 때문에 가장 최근에 학습한 도메인 데이터의 성능이 좋은 것이라고 볼 수 있지 않을지 의문
- knowledge transfer에 대한 분석이 다소 naive
- knowledge transfer를 주장하기 위해서는 knowledge transfer가 무엇인지 명확히 정의해야 하며 이를 어떻게 측정할 것인지가 명확히 드러났어야 함
- downstream task에 대한 sequential pretraining에서 가장 좋은 성능을 내는 distillation 방법 또한 세 번째, 네 번째 데이터에서는 성능을 그다지 올리지 못한다고 밝힘
- 2-Phase에서만 성능이 좋은데 distillation을 continual setting에서 좋은 성능을 낸다고 평가할 수 있는지 의문 (2번은 너무 제한적)
- pretraining이기 때문에 비용이 많이 들 것으로 예상되나, continual pretraining을 통해 어느 정도의 computational cost가 들어가는지에 대한 언급은 없음

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab