ELLE: Efficient Lifelong Pre-training for Emerging Data
ACL 2022
분야 및 배경지식
Lifelong Learning, Pretrained Language Model
- Lifelong Learning(연속학습, 평생학습)
- 새로운 지식을 점진적으로 학습하는 동시에 기존의 지식을 잊어버리는 catastrophic forgetting 완화를 목표로 함
- memory-based(=replay), consolidation-based(=regularization), dynamic architecture(=parameter-isolation) 방법 등이 존재
- 효율적인 사전학습
- 기존 PLM의 지식을 활용하여 사전학습을 진행하는 back distill
- 파라미터를 재활용하여 기존 PLM의 크기를 키우는 progressive training 등의 방식 존재
문제
- 사전학습된 언어모델(pretrained language model; PLM)은 정적인 데이터를 기반으로 학습되었으나, 실용적인 쓰임을 위해서는 다양한 출처의 새로운 데이터들을 연속적으로 학습해야 함 (lifelong pretraining; 연속 사전학습)
- 제한적인 컴퓨터 자원을 사용해 효율적으로 연속 사전학습을 진행해야 함 (efficiency; 효율성)
해결책
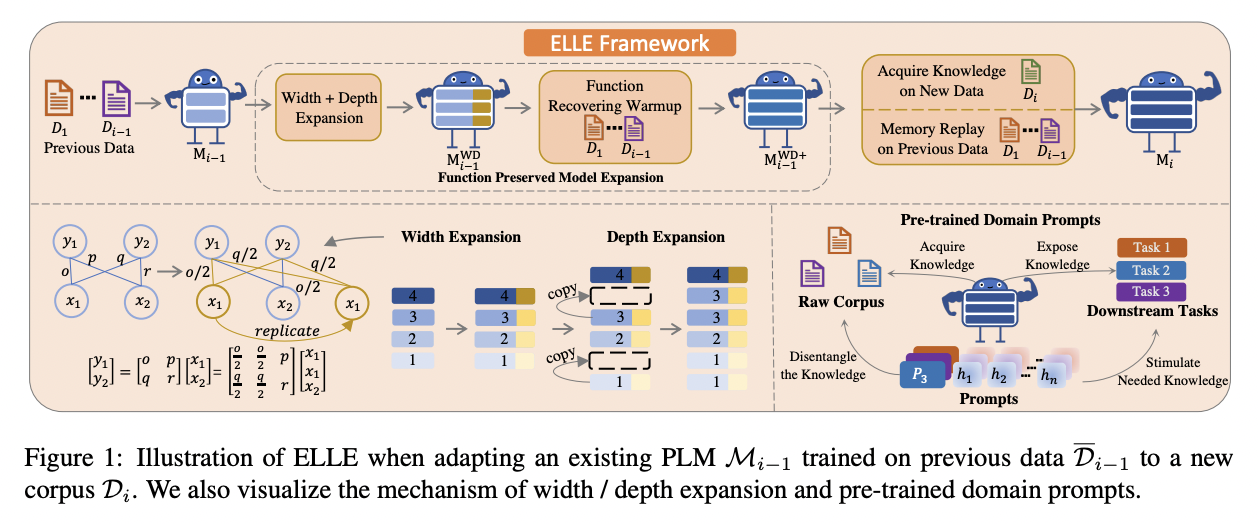
ELLE (Efficient LifeLong pre-training for Emerging data)
- function preserved model expansion
- 효율적인 지식 증가(efficient knowledge growth)를 목표로 유연하게 PLM의 깊이와 넓이를 증가
- 넓이 증가에는 function preserving initialization(FPI)+랜덤 노이즈 사용해 동일한 인풋에 대해 거의 동일한 아웃풋을 가질 수 있도록(=have approximately same functionality)
- 깊이 증가에는 새롭게 제안한 레이어 삽입 방식(랜덤하게 레이어 선택해 각 레이어의 파라미터를 복제하여 해당 레이어 앞 혹은 뒤에 삽입) 사용
- 이러한 과정을 통해 기존 PLM의 지식을 물려받음
- expansion 과정에서 소실된 성능을 복원하기 위해 function recovering warmup(이전 corpora로 expanded PLM 사전학습) 진행
- pretrained domain prompts
- 적절한 지식 촉진(proper knowledge stimulation)을 목표로 다양한 출처의 지식들이 구분(disentangle)될 수 있도록 도메인 프롬프트를 사전학습
- 해당 프롬프트를 도메인 지시자(indicator)로 활용
평가
- 사전학습 데이터
- 5개 도메인의 streaming data (Wikipedia and Bookcorpus, News Articles, Amazon Reviews, Biomedical Papers, Computer science papers)
- 각각 3,400M 토큰 샘플링
- 평가데이터(downstream)
- MNLI, Hyperpartisan, Helpfulness, Chemprot, ACL-ARC
- 모델
- BERT, GPT
- 평가기준
- 1) 사전학습 성능에 대해 average perplexity(모든 학습 데이터에 대한 평균 성능), average increased perplexity(현재 데이터가 이전 데이터에 미치는 영향)
- 2) 평가데이터 기반 downstream 성능 평가
한계
- 각 도메인의 학습 데이터에서 200M 토큰 랜덤 샘플링, 이를 사용해 function recovering warmup과 memory replay 시 사용
- 사전학습 시 필요한 컴퓨터 자원보다 대량의 데이터를 보관하는 비용이 더욱 저렴하다고 설명하나 상당히 큰 규모의 메모리가 필요
의의
- 사전학습(pretraining), downstream task에 대해서 모두 뛰어난 성능
- 학습 시 더 많은 지식을 얻음과 동시에 지식을 잊어버리는 문제를 완화
- 모델 아키텍처와 크기에 무관(agnostic)
- BERT, GPT 등 각기 다른 모델에 모두 사용 가능
- lifelong pretraining에서 네트워크의 크기를 늘리는 것 = architecture 방법이 사전학습과 downstream task 성능을 향상시키는 데에 가장 유용함을 보임
- replay 방법은 pretrain 시 knowledge forgetting을 완화시켜줄 수 있으나 downstream 성능은 떨어질 수 있다는 것을 밝힘
- regularization 방법의 경우 PLM의 knowledge acquisition에 유용하지 않다는 사실을 보임
- 참고: Towards Continual Knowledge Learning for Language Models 또한 네트워크의 크기를 늘리는 것이 가장 유용하다고 평가

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab