Learn Continually, Generalize Rapidly: Lifelong Knowledge Accumulation for Few-shot Learning
continual-learning
목록 보기
6/16
Learn Continually, Generalize Rapidly: Lifelong Knowledge Accumulation for Few-shot Learning
EMNLP 2021
분야 및 배경지식
Continual Learning, Meta-Learning
- Meta Learning (link)
- 배우는 것을 학습하는 (learn to learn) 문제
- 일반적으로 모델은 대량의 데이터셋을 통해 특정한 태스크를 학습하는데, 이는 사람의 학습방식과 다름
- 사람은 학습하는 방법을 배우기 때문에(=learn to learn), 과거의 경험과 몇 개의 예시를 이용하여 새로운 태스크를 빠르게 학습
- 배우는 것을 학습하는 (learn to learn) 문제
문제점
- 사람의 경우 언어지식을 활용할 때(Human Linguistic Intelligence) 항상 처음부터 배우는 것(=from scratch)이 아니라 이전에 배운 지식들을 조합하거나 분리함으로써 지식 확대
- 하지만 기존 CL의 경우 학습한 태스크들에 대한 성능 유지에 주로 초점, 새로운 태스크에 대해 빠르게 일반화하는 연구 미비
해결책
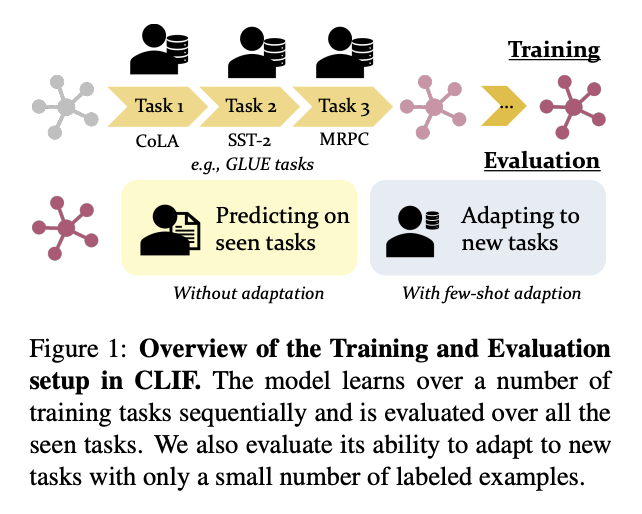
새로운 문제 정의: Continual Learning of Few-Shot Learners (CLIF)
- 연속적인 지식 축적: continuous knowledge accumulation
- 새로운 few-shot(=학습 데이터가 많지 않은) 태스크에 대한 일반화: few-shot generalization(adaptation)
- 학습한 태스크에 대한 성능 유지

새로운 모델: Bi-level Hypernetworks for Adapters with Regularization
- Hyper-Networks
- task representation z를 인풋으로 받아 다른 예측 모델의 파라미터를 생성하는 하이퍼 네트워크. 일련의 태스크에 대해 빠른 adaptive model을 학습할 수 있도록 adapter만을 위한 weight를 생성
- Bi-level
- context predictor를 활용하여 학습데이터로부터 high-resource, few-shot representations를 생성. high-resource representation의 경우 지식 전이를 촉진시키며, few-shot task representation의 경우 더 나은 일반화를 위한 few-shot learning을 가능하도록 함 (high-resource의 경우 CL동안 memory에 저장)
- Regularization
- 이미 학습된 태스크에 대한 forgetting을 방지하고자 weight change를 규제
평가
- Metrics
- few-shot performance
- 연속학습을 진행한 모델이 적은 수의 annotated examples를 가진 학습하지 않은 태스크에 대해 얼마나 좋은 성능을 내는지 확인 (평균 정확도, 상대적 개선정도 활용)
- instant performance
- 연속학습 시 해당 태스크의 학습이 끝난 직후 해당 태스크에 대한 성능. 해당 태스크만 학습했을 때의 성능과 비교하여 모델이 이전 태스크에서 다음 태스크에 얼마나 많은 지식을 전이했는가를 평가 (평균 개선정도, 상대적 개선정도 활용)
- final performance
- 연속학습을 진행한 모델이 과거의 지식을 얼마나 잊었는가에 대한 평가 (instant performance - final performance)
- few-shot performance
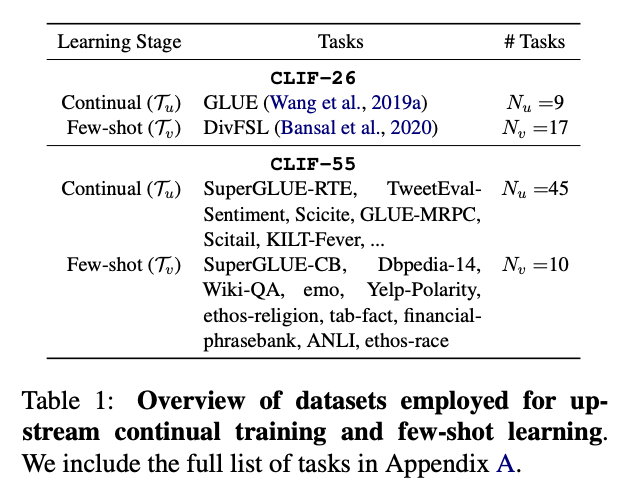
- Tasks
- 자연어추론, 감정분류, 주제분류, 사실관계 파악, 혐오발언 감지, paraphrasing 등
- 모든 예시들은 sequence-to-sequence 질의응답 형식으로 변경되어 하나의 모델이 모든 태스크를 수행할 수 있도록 함
한계
- few-shot representation이 없을 경우 few-shot accuracy가 떨어진다고 하나, 그 정도가 굉장히 미미함 (1.08, 0.33)
- high-resource represenations를 memory에 저장하며, hypernetwork를 추가로 사용하기 때문에 비용 증가
의의
- 기존의 CL 방식들이 catastrophic forgetting(이전에 배운 지식을 망각하는 문제)의 완화에는 도움을 주나 모델의 일반화 성능에 대해서는 큰 도움을 주지 못한다는 사실을 밝힘 (하지만 CL 알고리즘 없이는 연속학습에서 지식 축적이 덜 robust)
- catastrophic forgetting이 일반화 성능에 부정적인 영향을 끼치며, 그보다도 학습한 태스크들(seen tasks)의 성능에 더욱 큰 부정적인 영향을 끼친다는 사실을 밝힘
- BiHNet-Reg의 경우 시간이 지남에 따라 효과적으로 지식을 축적할 수 있음을 보임
- 학습 데이터를 task representation으로 바꾸어 저장하기 때문에 privacy-sensitive(개인정보 민감) 상황에서도 적용 가능

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab