About CV(computer vision)
컴퓨터 비전이란 컴퓨터가 이미지과 같은 시각 데이터를 통해 정보를 얻어내는 과정이다.
해당 분야에는 크게 3가지의 문제들이 존재한다.
- Image Classification
이미지를 분류하는 작업을 수행한다 - Object Detection
이미지에서 물체를 탐지하는 작업을 수행한다 - Style Transfer
이미지의 스타일을 변화시키는 작업을 수행한다
About Edge Detection
Edge Detection은 이미지에서 경계를 찾는 과정이다.
convolution formula
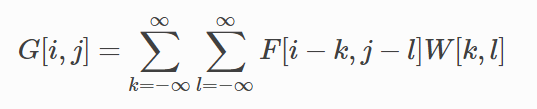
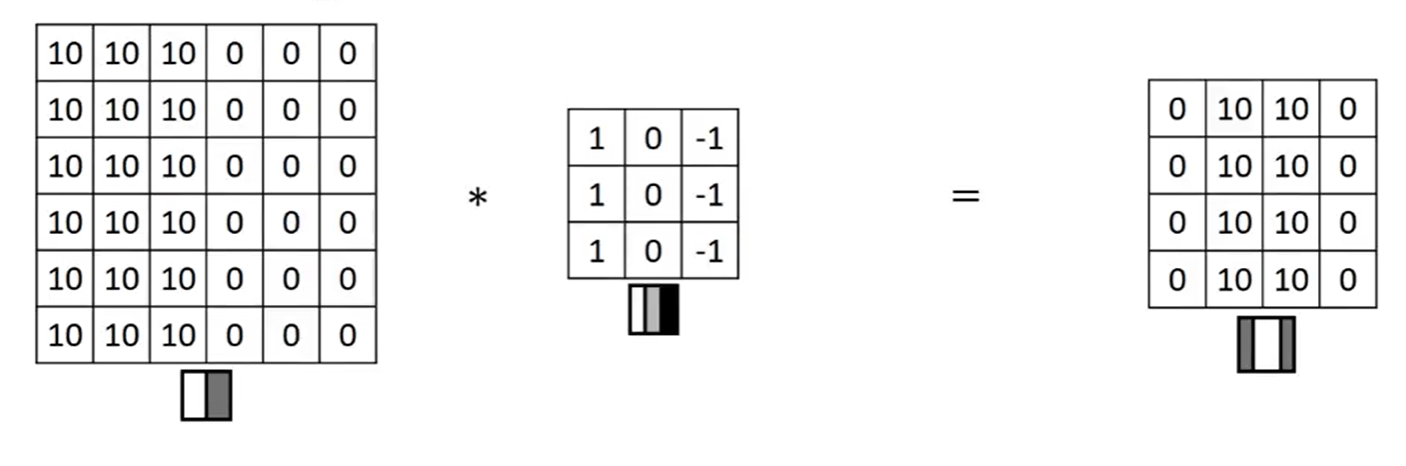
vertical edge detection example
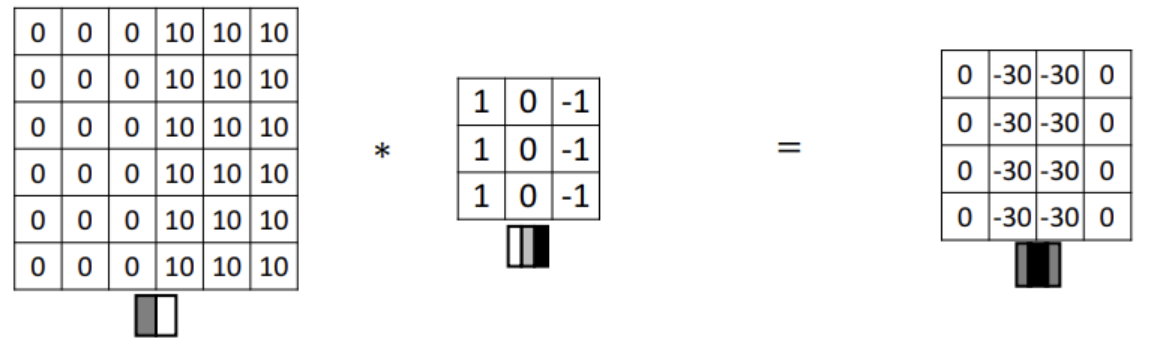
hrizontal edge detection example
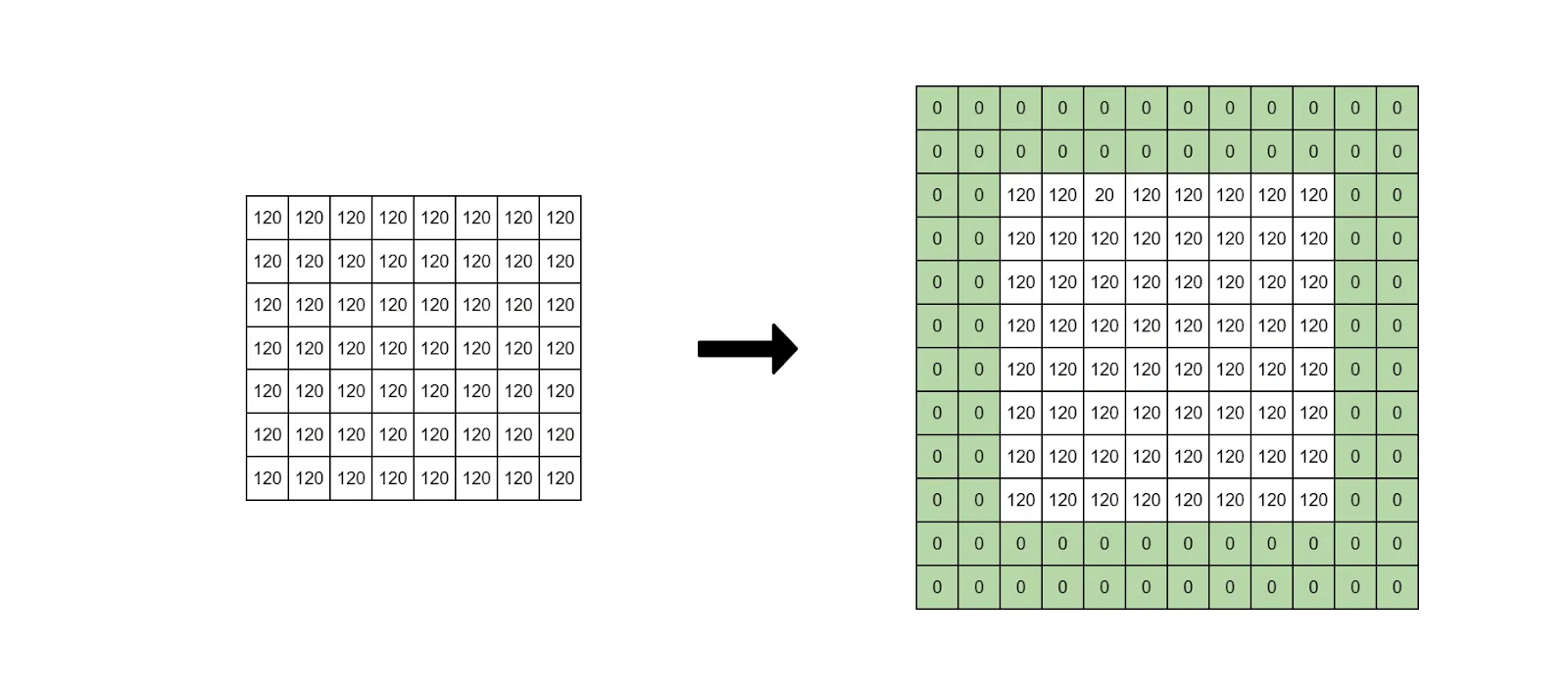
padding
이미지 데이터를 filter에 적용시키는 과정에서 중앙에 가까운 픽셀 데이터는 사용이 많이 되지만, 가장자리 픽셀 데이터는 적게 사용되어 주변에 픽셀 데이터들을 추가하는 것이다
stride
stride는 입력 데이터에 필터를 적용하는 과정에서 연산을 수행후 얼마나 이동할지를 의미한다.
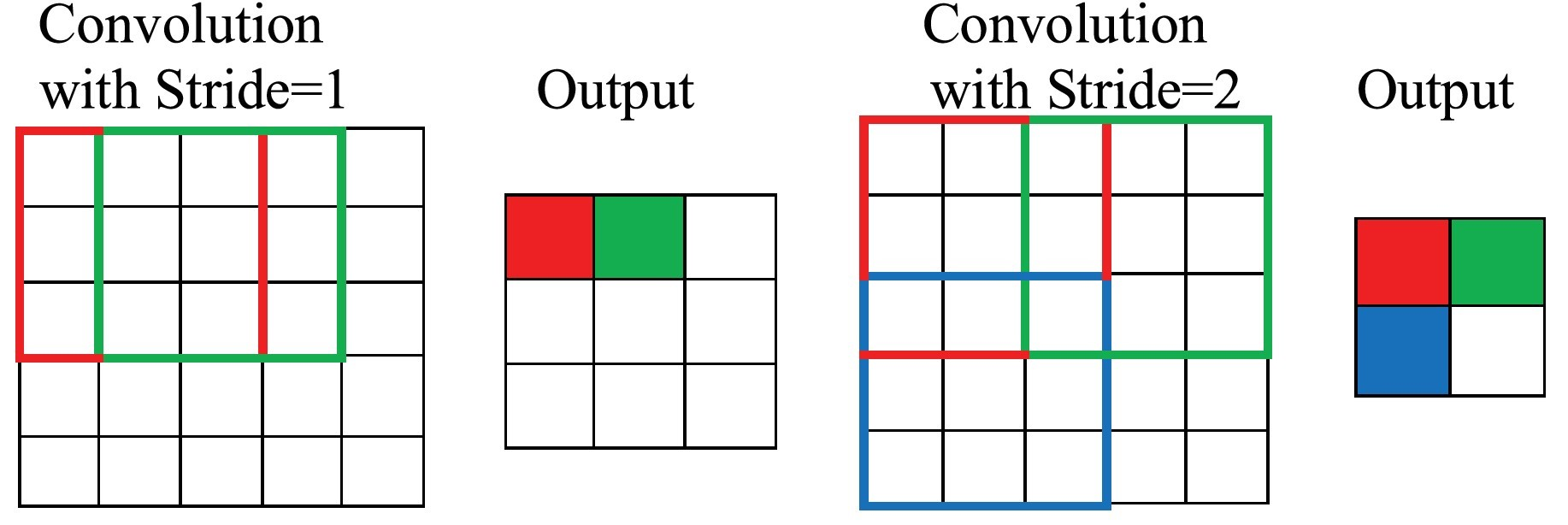
ouput shape
input shape : n x n
filter shape : f x f
padding : p
stride : s
ouput shape = (n + 2 * p - f) / s + 1 x (n + 2 * p - f) / s + 1
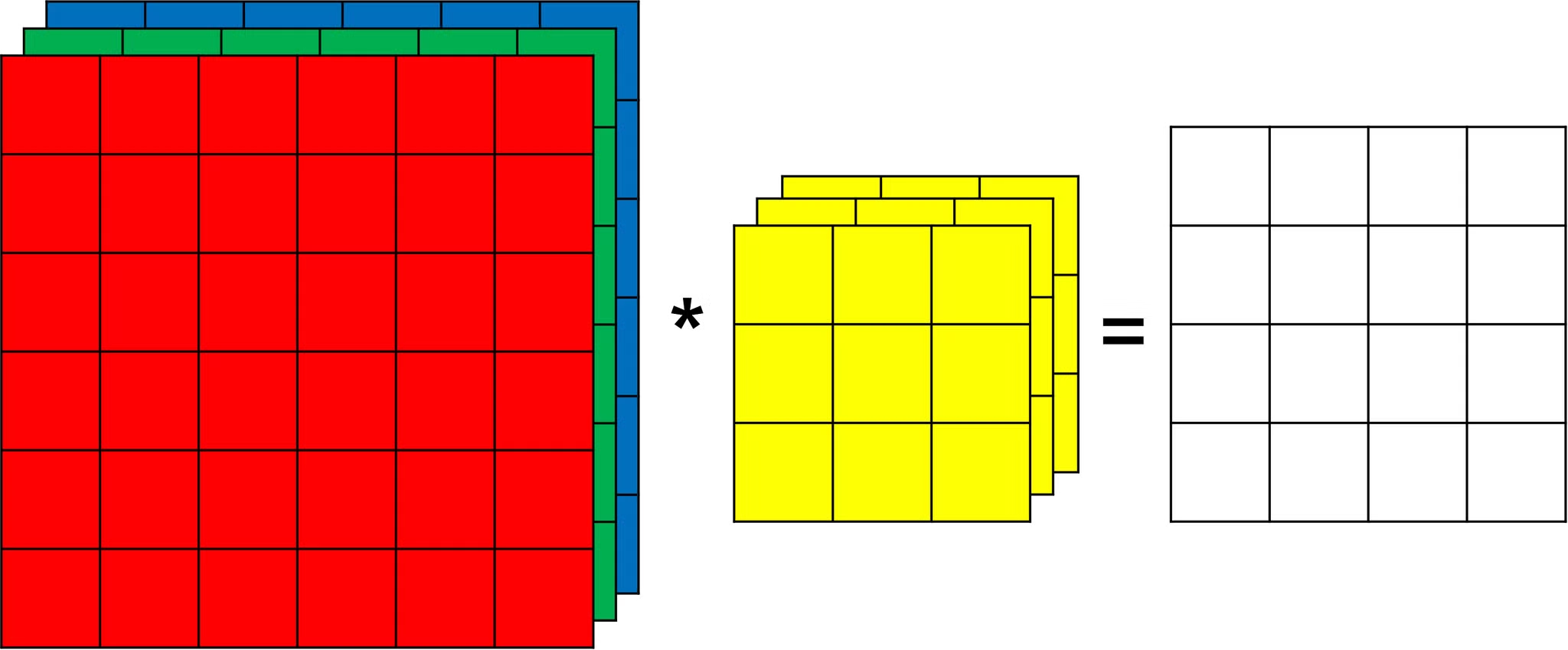
Convolutions Over Volums
지금까지의 합성곱 연산은 모두 2차원 데이터에서 이루어졌다.
하지만 RGB 이미지 같은 경우에는 색상별로 채널이 존재하여 3차원 데이터로 존재한다.
이러한 경우 각 채널별로 필터와의 합성곱 연산을 수행하고 해당 결과들을 합하는 과정을 취한다.
Multiple Filters
목적이 다른 여러 필터들을 모두 사용하기 위한 방법이다.
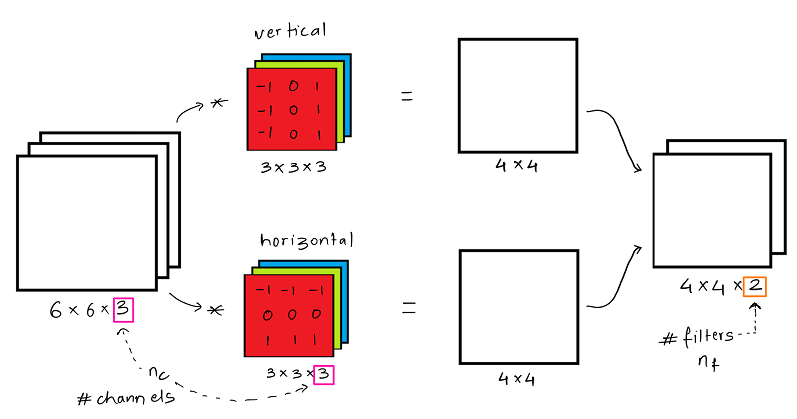
입력 데이터를 각각의 필터와 합성곱 연산을 진행하고 나온 결과를 채널의 형태로 합친다.
따라서 아웃풋의 채널은 필터의 수와 동일하다.
Example ConvNet

지금까지의 합성곱 연산의 과정을 정리하자면 위 그림과 같다.
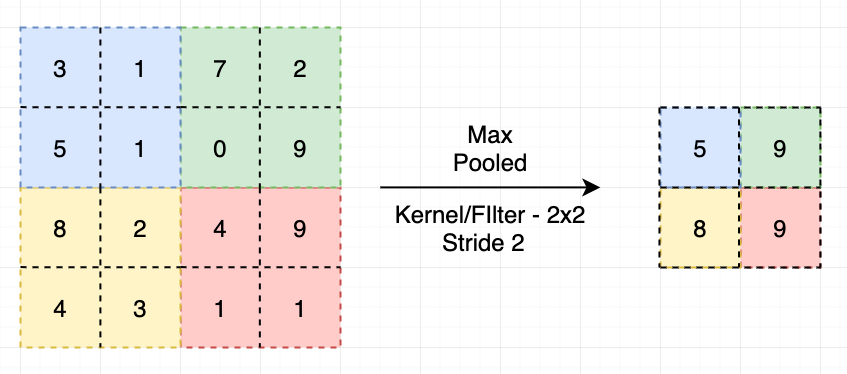
Pooling Layers
가장 중요한 정보를 추출하기 위해 사용되는 방식으로 Max Pooling의 경우 해당 영역에서 가장 큰 값을 가져와 결과 데이터에 추가하는 방식이다.
Flow
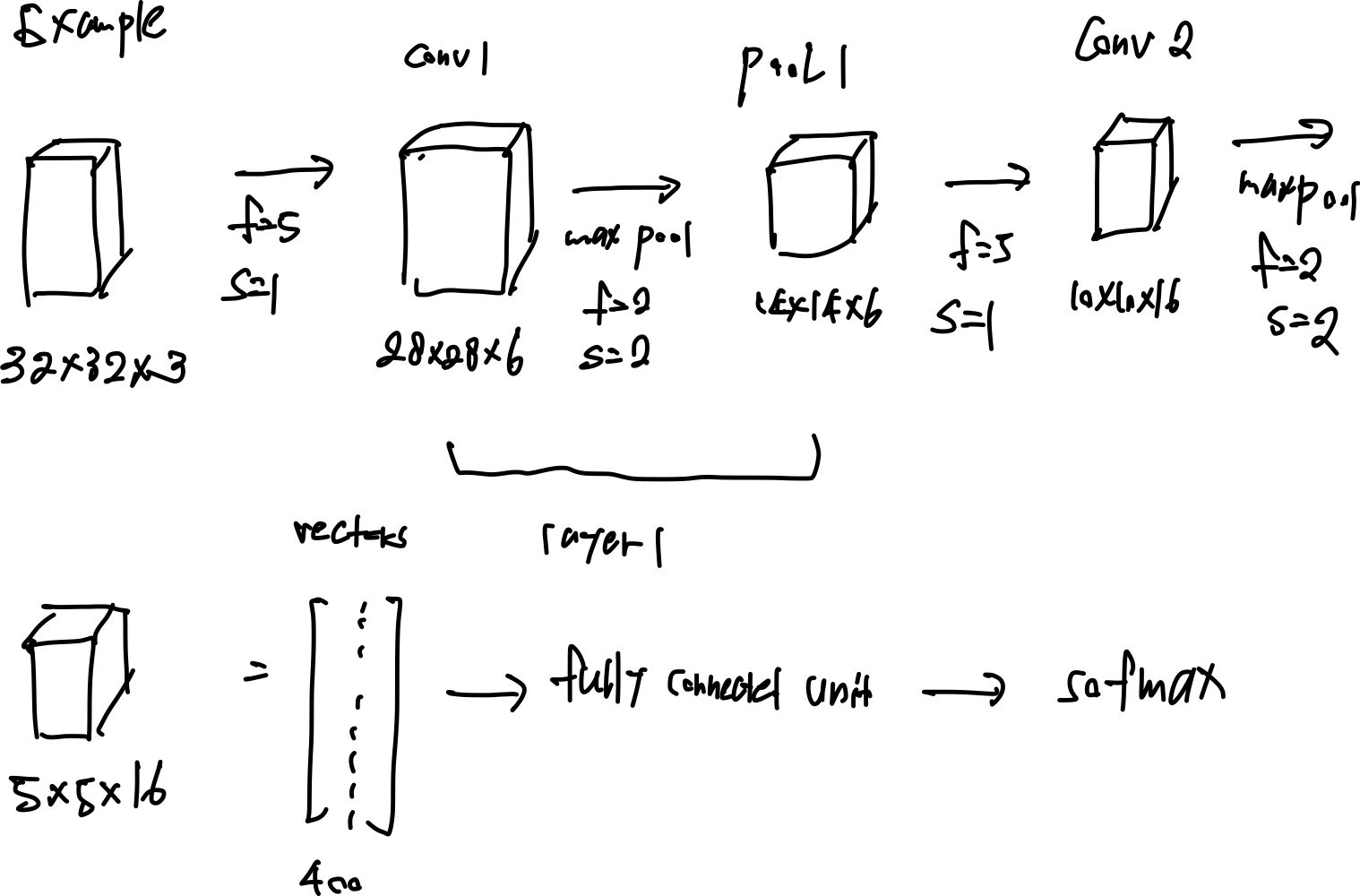
입력 데이터가 들어오게 되면 여러 필터를 적용시켜 데이터를 가공하고 fully connected unit에서 텐서를 1차원 데이터로 변경하고 텐서의 공간을 반환하여 최종 결과를 낸다.
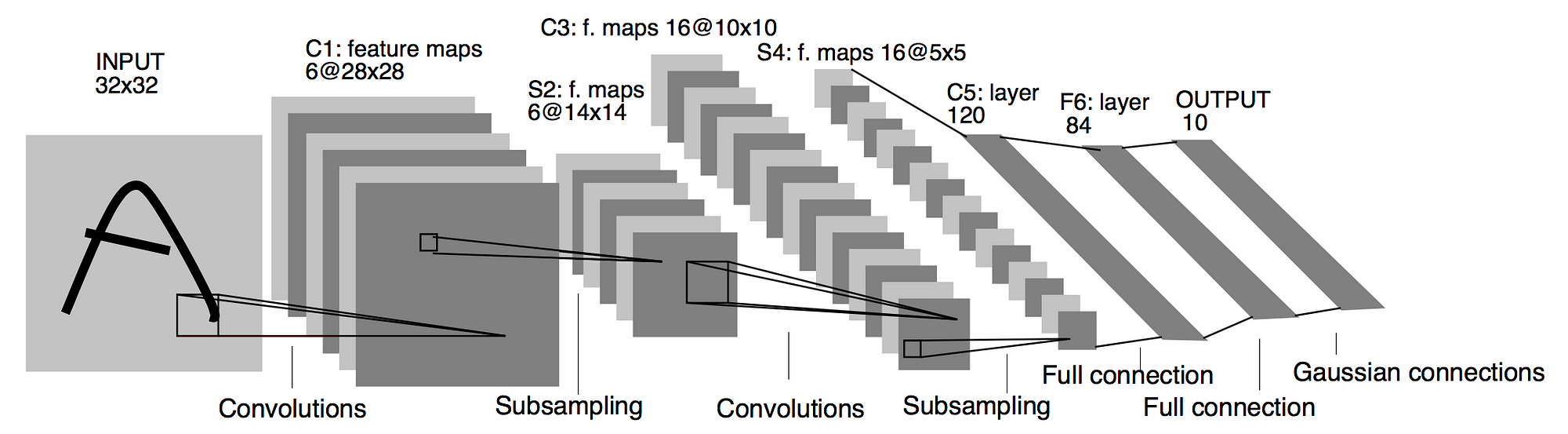
LeNet-5
Alex Net
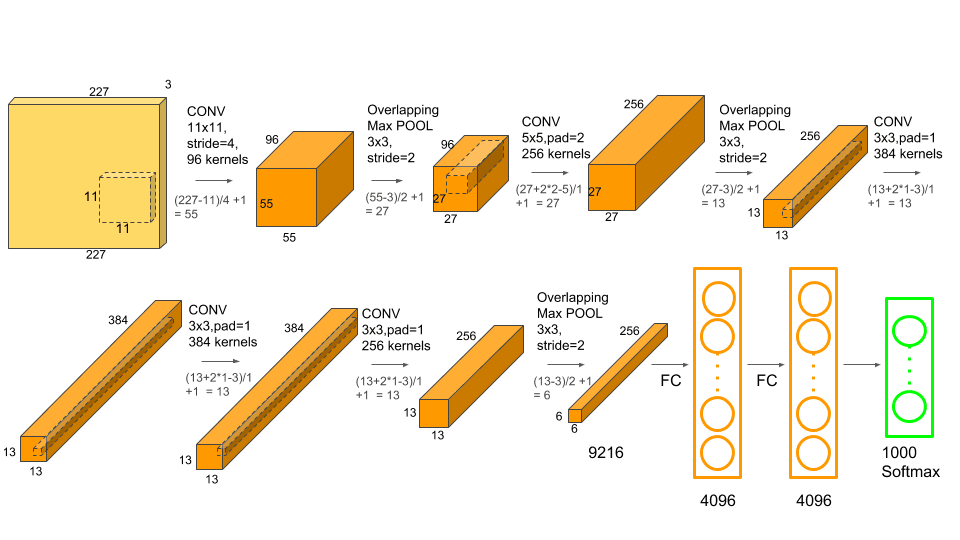
alex net은 lenet과 유사하지만 많은 파라미터를 사용할 수 있으며 ReLU 활성화 함수를 사용한다.
VGG-16
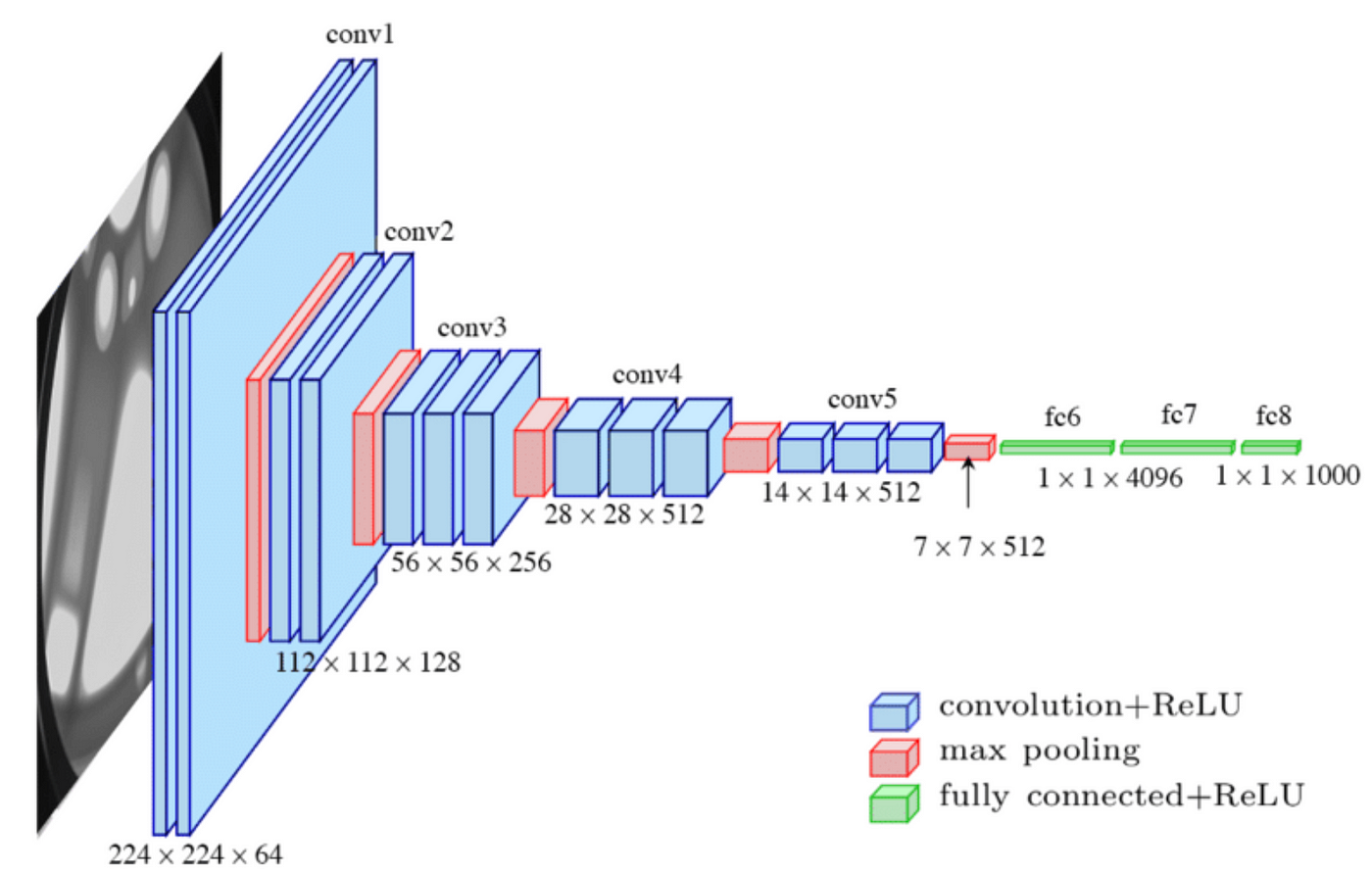
vgg-16은 16개의 레이어를 가지고 있으며 컨볼루션 레이어가 3x3, s=1 로 규격화 되어있으며, 풀링 레이어도 2x2, s=2로 규격화 되어있다.
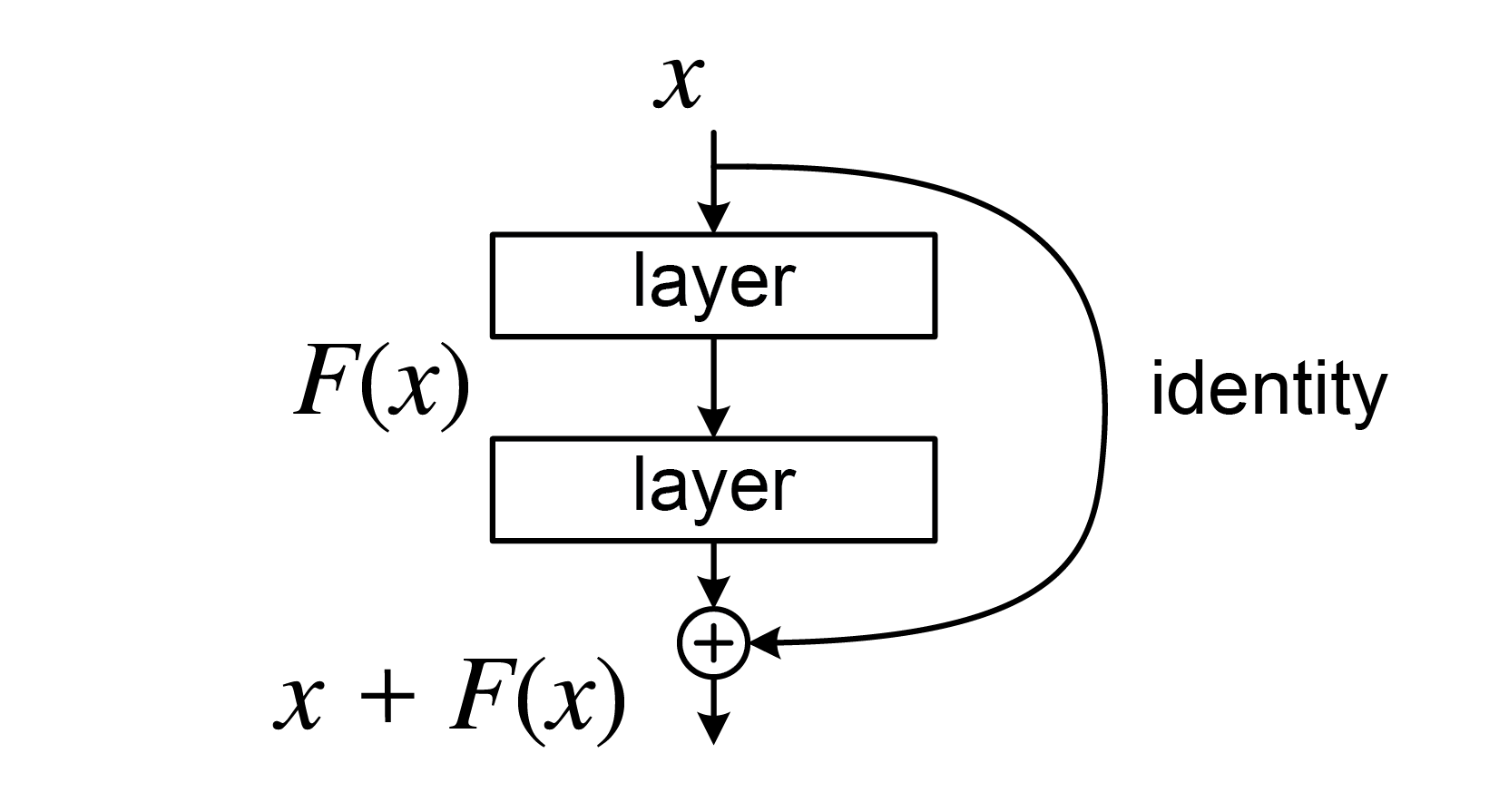
ResNet
입력값과 출력값을 더해주기 위해 shortcut을 추가하는 방식
shortcut을 추가함으로써 기존에 학습한 정보를 보존하고 추가적인 연산이 필요한 부분만 연산을 진행한다. 따라서 학습량이 기존의 방식에 비해 상대적으로 줄어든다.
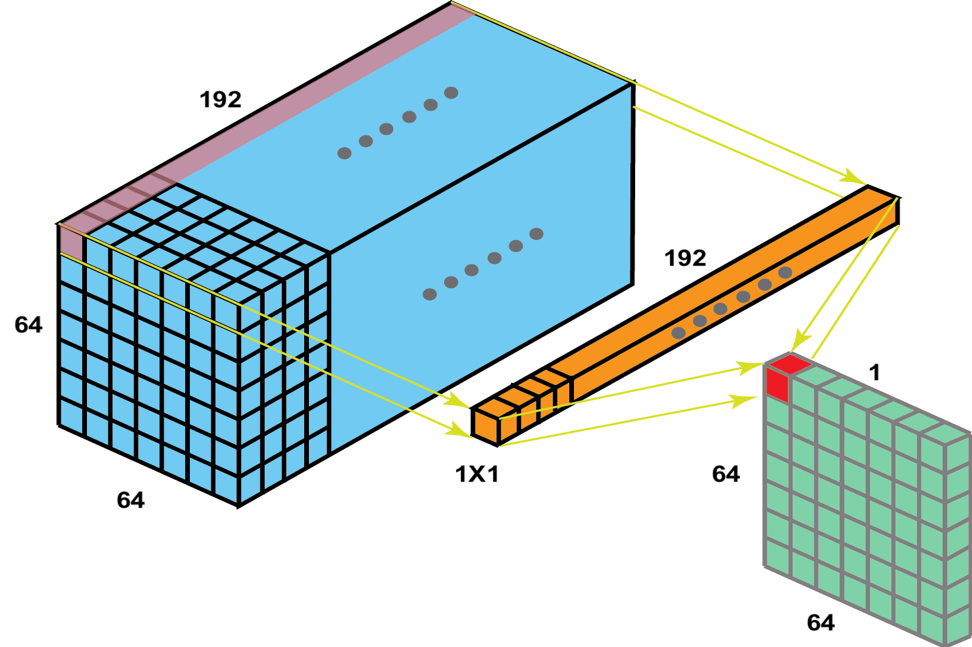
Network in Network
1 x 1 필터와 convolution 연산을 수행하는 방식
해당 연산을 통해 채널의 수를 줄일수 있으며 비선형성을 더해준다.
Inception Network
Inception module
다양한 크기의 convolution filter와 pooling filter를 이용한 후 정보를 종합하는 방식
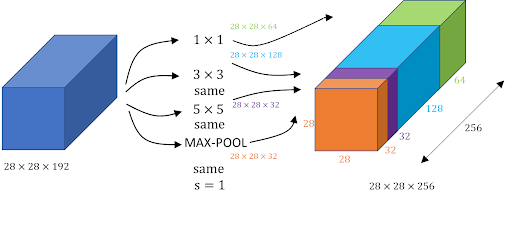
convolution filter와 연산을 수행할 때 direct로 연산을 수행하면 연산량이 많아지는 문제가 발생해 1x1 convolution을 통하여 채널의 수를 줄인 후 연산을 진행한다.
Inception Network
인셉션 네트워크는 인셉션 모델들을 묶은 형태이다.
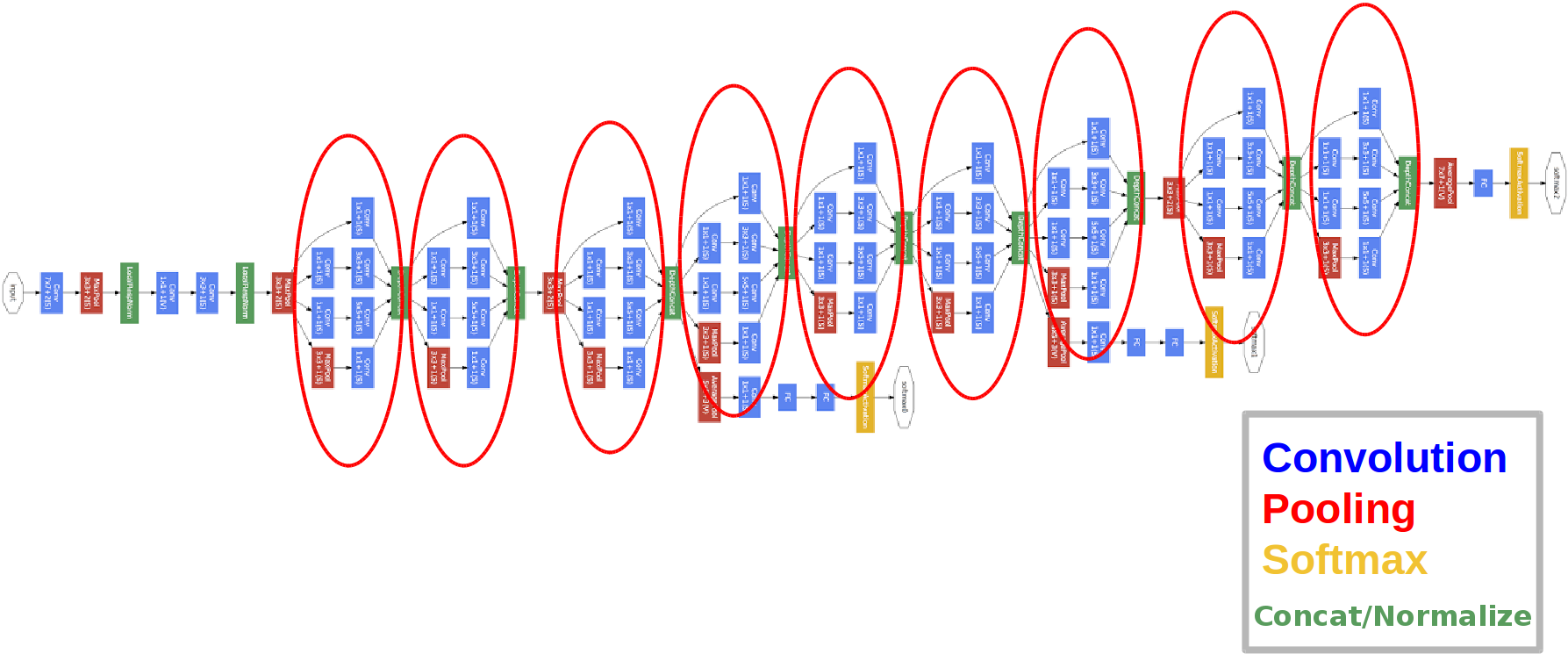
인셉션 네트워크의 구조를 보면 auxillary classifiers가 존재하며 이는 깊은 신경망에서 vanishing gradient 문제를 방지하기 위해 존재한다.
Data Augmentation
하나의 데이터를 변형(확대, 축소, 반전)등을 이용해 여러 데이터를 만드는 과정
- mirroring
- random cropping
- color shifting
이상으로 포스팅을 마치겠습니다.
