- 사이킷런의 분류를 위한 Classifier클래스와 회귀를 위한 Refressor클래스는 모두 Estimator클래스의 자식 클래스이다
교차 검증
- 과적합의 문제를 해결하기 위해 교차검증이 필요하다
- 교차검증은 모의고사를 여러 번 보는것과 같다
K 폴드 교차 검증
- K개의 데이터 폴드 세트를 만들어서 K번만큼 각 폴드 세트에 학습과 검증 평가를 반복적으로 수행
- K가 5이면 데이터를 5개로 나누어 평가한 뒤 이 평가를 평균한 결과를 가지고 예측 성능을 평가한다
Stratified K 폴드
- Stratified K 폴드는 불균등한 분포도를 가진 레이블 데이터 집합을 위한 K 폴드 방식
- 불균등한 분포를 가진 레이블은 특정 레이블이 특이하게 많은 상태
- Stratified K 폴드는 데이터를 K로 나눌 때 레이블의 분포를 고려해서 나누어 준다
- 일반적으로 분류문제에서는 Stratified K 폴드로 분할되어야 한다
- 회귀문제에서는 Stratified K 폴드가 지원되지 않는다
GridSearchCV
- 교차검증과 최적 하이퍼 파라미터 튜닝을 한 번에 수행
데이터 전처리
- 사이킷런의 ML모델들은 데이터의 결측치를 허용하지 않는다
- 문자열 데이터의 경우 숫자로 인코딩 해야한다
레이블 인코딩
- 카테고리 피처를 숫자형으로 변환
- Tv → 1, 냉장고 →2, 컴퓨터 → 3 이런식으로 변환
- 레이블 인코딩은 선형회귀와 같은 ML알고리즘에서는 더 큰 숫자의 피처를 중요하게 생각 할 수 있어서 선형회귀에서는 적용하지 않아야 한다
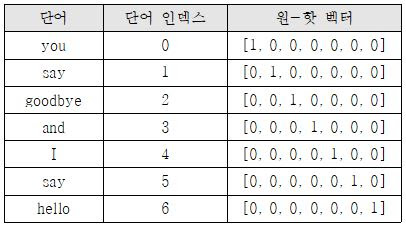
원-핫 인코딩
- 해당 피처에만 1로 표시하고 나머지는 0으로 채워넣는 방식
피처 스케일링과 정규화
- 서로 다른 변수의 값 범위를 일정한 수준으로 맞춰주는 작업을 피처 스케일링(feature scaling)이라 한다
표준화(Standardization)
- 데이터의 피처 각각이 평균이 0이고 분산이 1인 가우시안 정규 분포를 따르도록 변환
- 피처의 평균을 빼고 표준편차로 나누어 계산
- 사이킷런 StandardScaler로 사용 가능
정규화(Nomalization)
- 서로 다른 피처의 크기를 통일하기 위해 크기를 변환해주는 개념
- 0~1로 값을 모두 바꿔주는 과정
- 사이킷런 MinMaxScaler로 사용가능
-
스케일링을 적용할 때 전체 데이터를 한번에 스케일링 변환 후 학습 데이터와 테스트 데이터로 나누는 것이 좋다
-
성능 평가 지표는 분류냐 회귀냐에 따라 여러 종류로 나뉜다
정확도(Accuracy)
- 실제 데이터에서 예측 데이터가 얼마나 같은지
- 정확도는 불균형간 레이블 값 분포에서 판단할 경우 적합한 평가 지표가 아니다
오차행렬(confusion matrix)
- 이진분류에서 평가 지표로 많이 활용
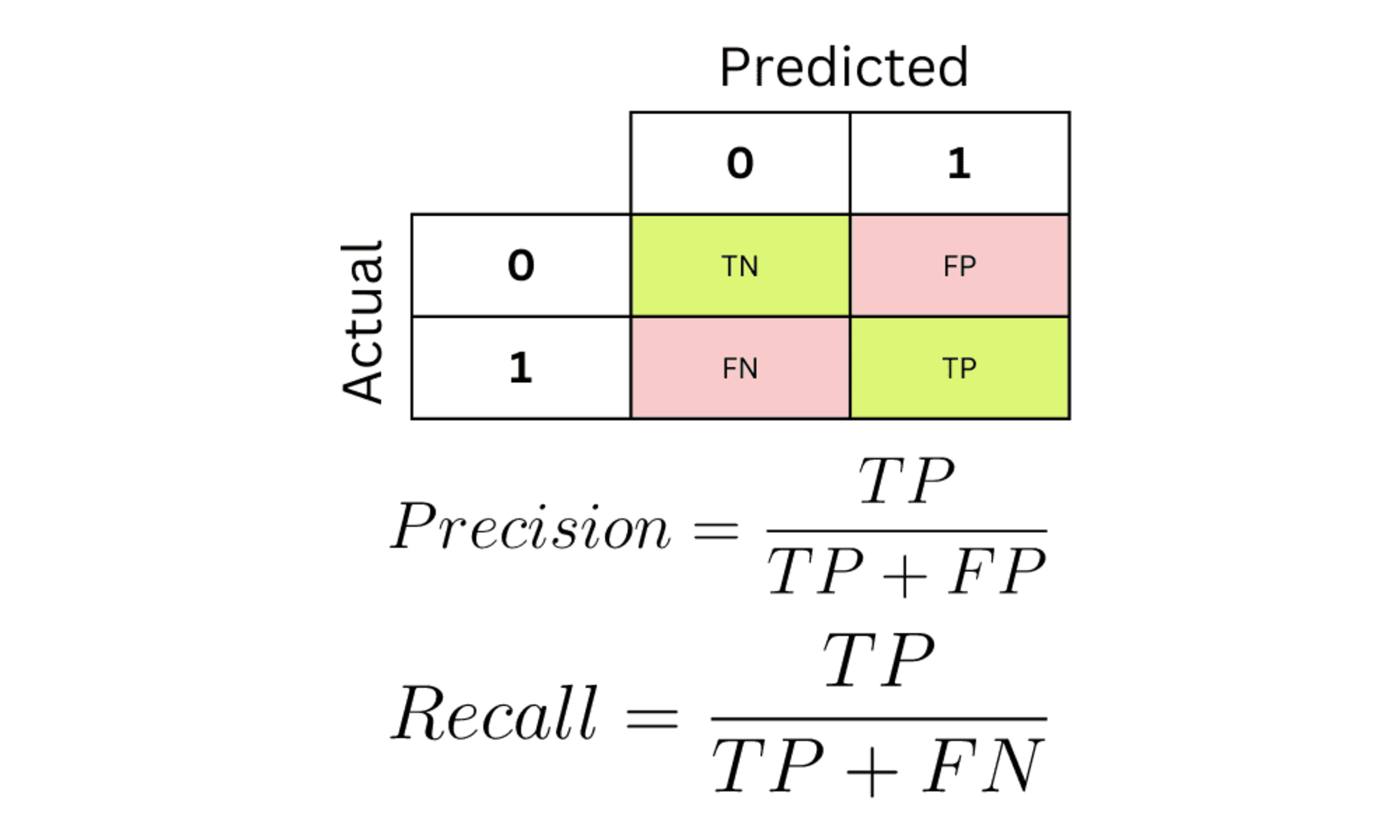
- 예측하는 모델의 입장에서 1이면 P 0이면 N
- 맞으면 T, 틀리면 F
정밀도(Precision), 재현율(Recall)
- Precision 은 Positive로 예측한 대상 중 예측화 실제 값이 Positive로 일치 한 비율, Positive 예측 성능을 더욱 정밀하게 측정하기 위한 지표
- Recall 은 실제 Positive중 예측과 실제 모두 Positive로 일치한 데이터의 비율, 민감도(Sensitivity) 또는 TPR(True Positive Rate)이라고도 불린다
- 재현률이 상대적으로 더 중요한 지표인 경우는 P를 N으로 잘못 판단하면 안되는 경우
- 정밀도가 상대적으로 더 중요한 지표인 경우는 N을 P로 잘못 판단하게 되면 안되는 경우
- 정밀도와 재현율은 상호 보완적인 평가지표이기 때문에 Trade-off 가 있다
F1 score
- 정밀도와 재현율의 조화평균
ROC와 AUC
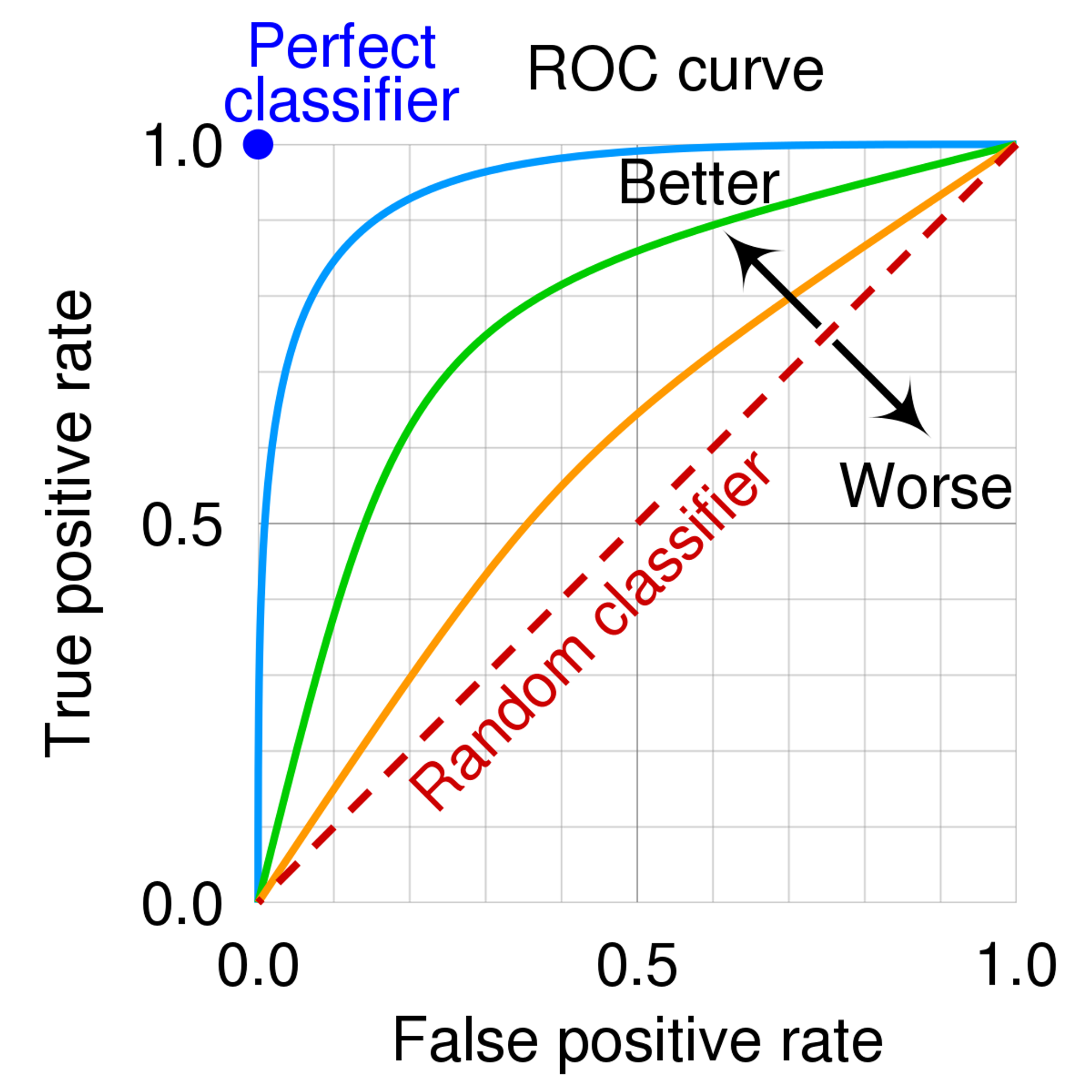
- ROC: FPR(False Positive Rate)이 변할 때 TPR(True Positive Rate)(재현율)이 어떻게 변하는가
- TPR = TP / (FN + TP)
- FPR = FP / (FP + TN)
- AUC: ROC 곡선의 밑 면적
.jpg)