- 지도학습의 대표적인 유형인 분류(Classification)
Decision Tree(결정 트리)
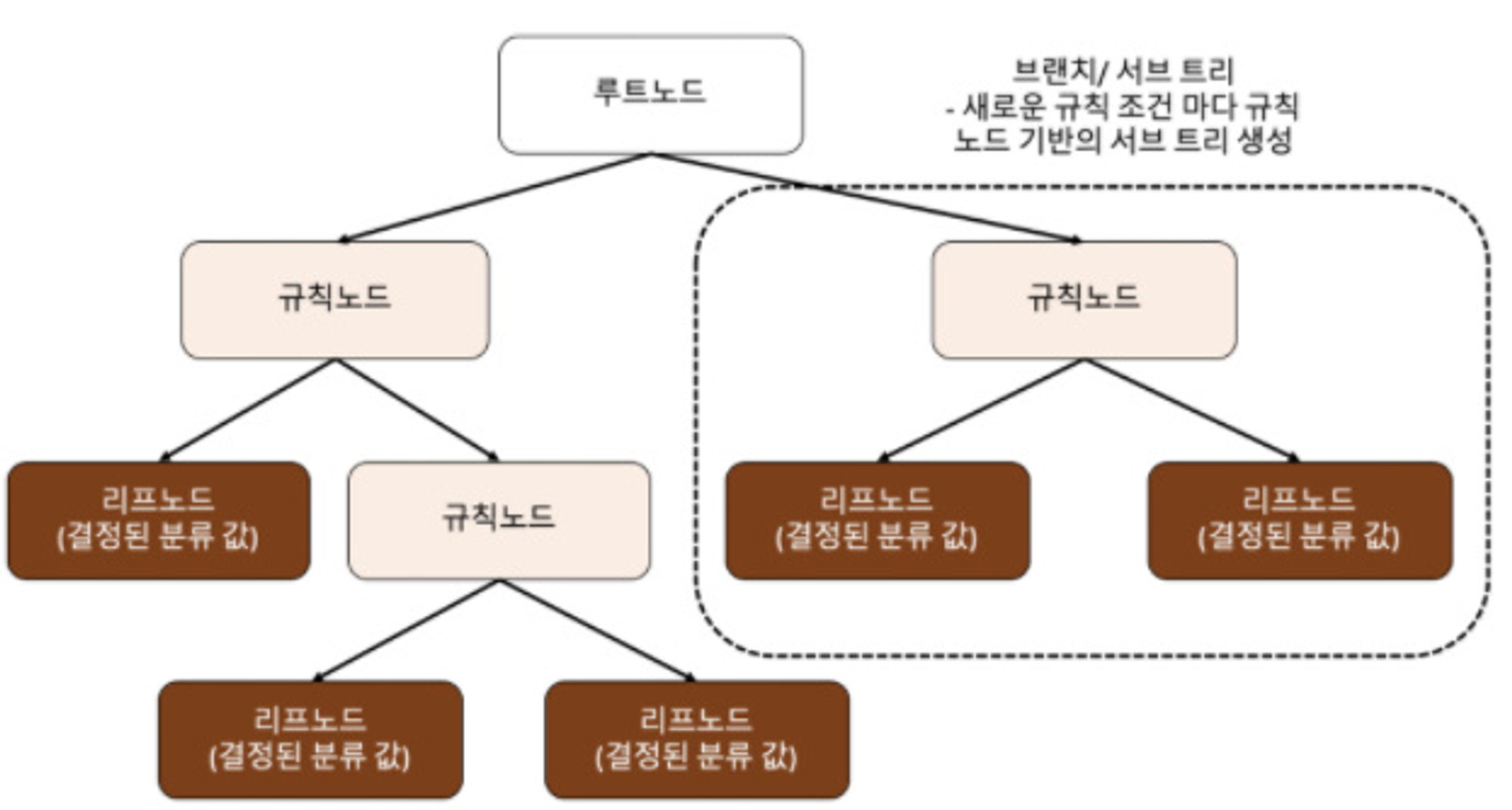
- 규칙 노드가 규칙 조건이 되고 리프 노드는 결정된 클래스 값이다
- 데이터 세트의 피처가 규칙 조건을 만든다
- 많은 규칙노드는 과적합으로 이어질 수 있다
- Decision Tree는 정보 균일도가 높은 데이터 세트를 먼저 선택할 수 있도록 트리를 구성한다
- Information gain을 활용하는데 엔트로피 개념을 기반으로 한다 데이터에 서로 다른값이 많이 섞여 있으면 엔트로피가 높고 같은 값이 섞여 있으면 엔트로피가 낮다
- 1- 엔트로피 = IG 로 해서 IG높은 피처를 기준으로 먼저 분할한다
앙상블(Ensemble Learning)
- 여러개의 분류기를 생성하고 그 예측을 결합함으로써 보다 정확한 예측을 도출하는 기법
- 정형데이터의 경우 딥러닝보다 앙상블이 더 뛰어난 성능을 보인다
보팅(Voting)
- 하드보팅: 여러개의 분류기의 아웃풋을 다수결로 최종 class를 결정
- 소프트 보팅: 여러개의 분류기의 아웃풋을 평균내어 최종 class를 결정
배깅(bagging), 랜덤 포레스트
- 보팅과 다르게 각 분류기에 모든 데이터를 학습으로 넣지 않고 부트스트래핑(bootstrapping) 으로 데이터 세트가 일부 중첩되게 샘플링 후 개별 분류기에 학습
- 랜덤 포레스트는 샘플링 된 데이터를 학습한 분류기의 아웃풋을 소프트 보팅하여 최종 class를 예측
부스팅
- 여러개의 약한 학습기를 순차적으로 학습-예측 하면서 잘못 예측한 데이터에 가중치를 부여하여 오류를 개선해 나가면서 학습
- AdaBoost: 오류 데이터에 가중치를 부여하면서 부스팅하는 알고리즘

- GBM(Gradient Boost Machine): adaboost와 비슷하나 경사하강법을 활용해 오류값(실제갑 - 예측값)을 최소화 하는 방향으로 학습을 수행
- XGBoost: GBM에 기반하지만 더 빠른 학습과 과적합 규제를 할 수 있음
- LightGBM: XGBoost보다 더 빠르지만 적은 데이터에는 과적합이 발생 할 수 있다
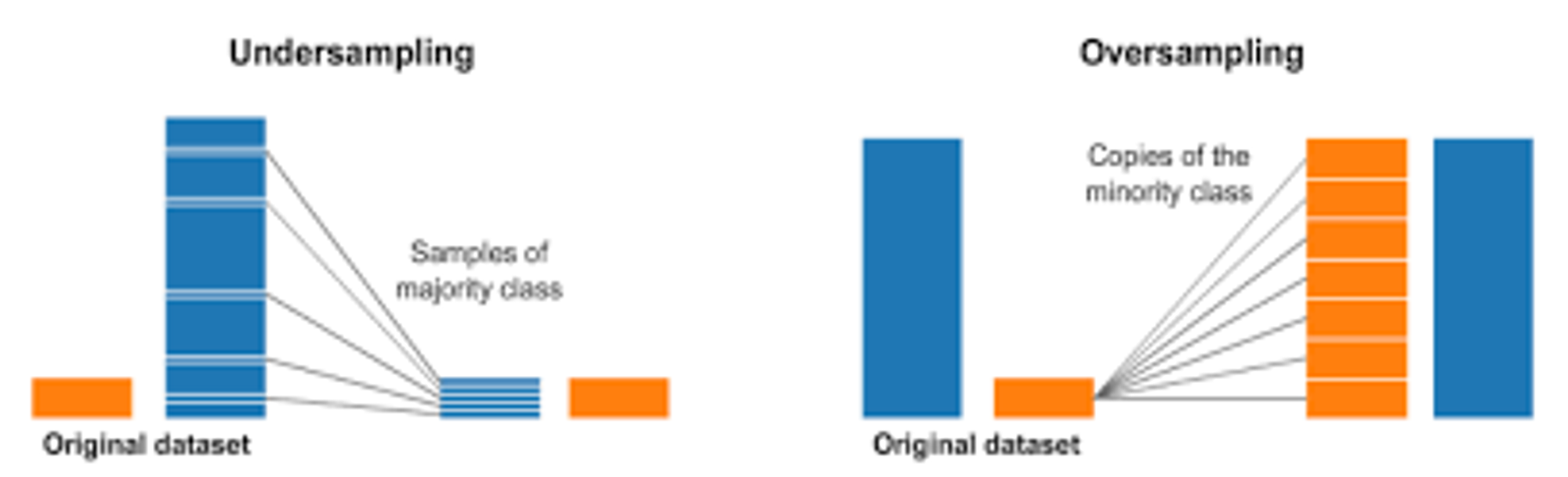
언더 샘플링과 오버 샘플링
-
레이블이 불균등한 데이터 세트를 학습 시킬때, 성능의 문제가 생길 수 있는데 이를 해결하기 위한 방안
-
일반적으로 오버샘플링을 많이 한다
-
언더샘플링: 많은 레이블을 가진 데이터 세트를 적은 레이블을 가진 데이터 세트 수준으로 감소
-
오버샘플링: 적은 레이블을 가진 데이터 세트를 증식
-
오버 샘플링의 대표적으로 SMOTE 방법이 있다. 이 방법은 적은 레이블 데이터 세트의 K 최근접 이웃(KNN)을 찾아서 적은 레이블 데이터와 일정 차이가 나는 새로운 데이터를 생성
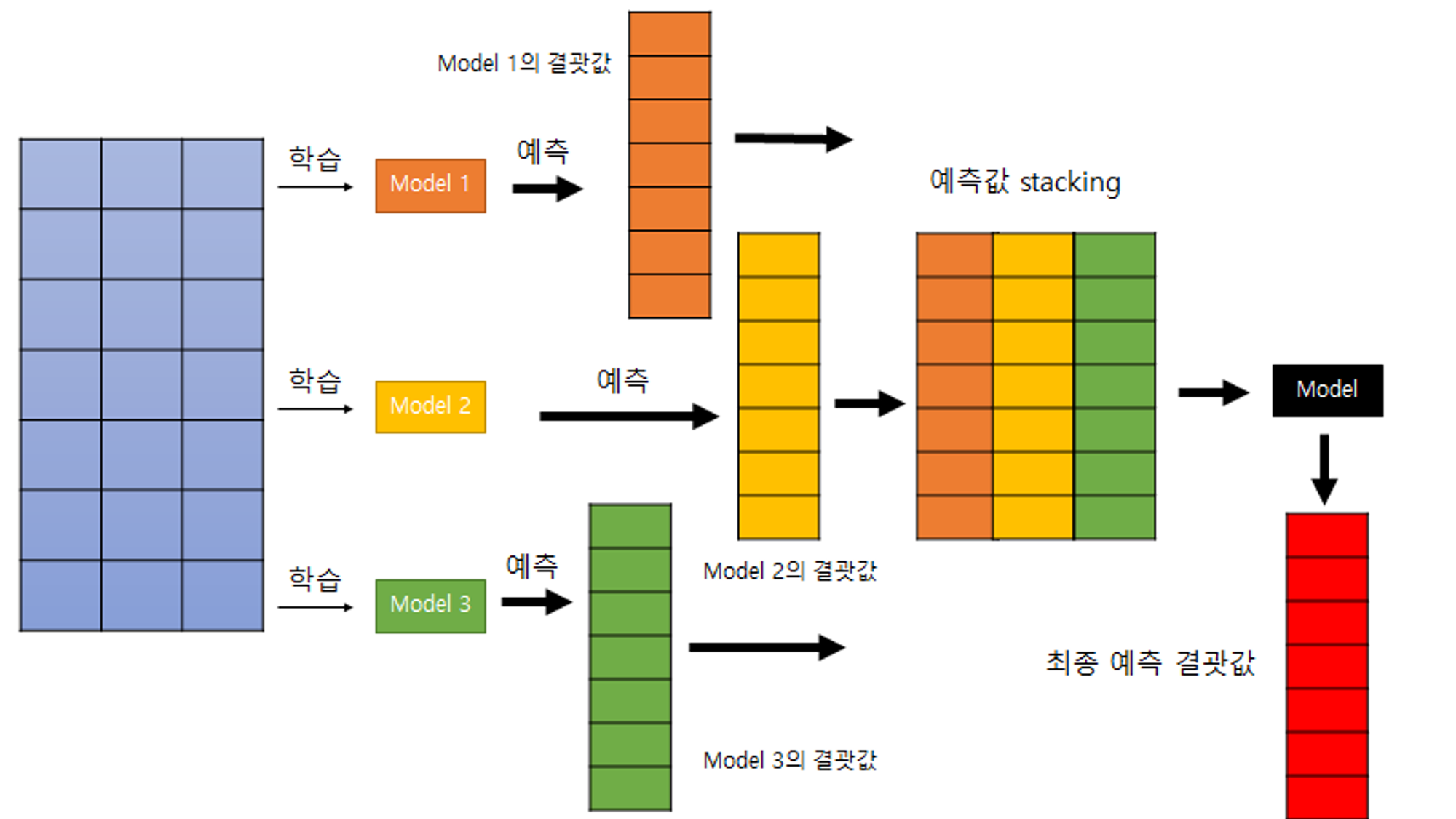
스태킹(Stacking)
- 개별적 알고리즘으로 예측한 데이터를 기반으로 다시 예측을 수행
- 개별 알고리즘의 예측결과를 메타 데이터 세트로 만들어 별도의 ML알고리즘으로 최종 학습을 수행하고 예측
.jpg)