k-means 군집화
- k-means(k 평균) 군집화는 군집화에서 가장 일반적으로 사용되는 알고리즘이다
- k-means은 군집 중심점(centroid)이라는 특정한 임의의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법이다
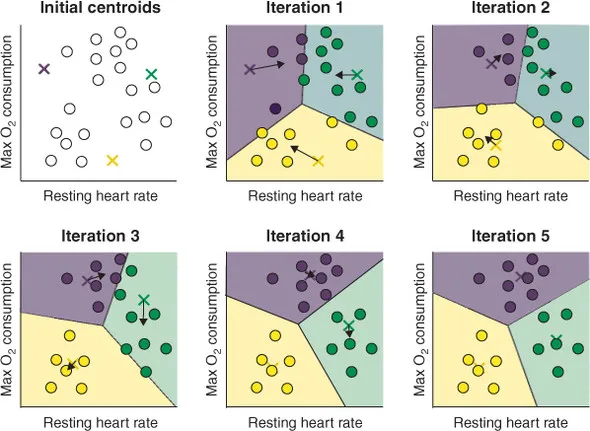
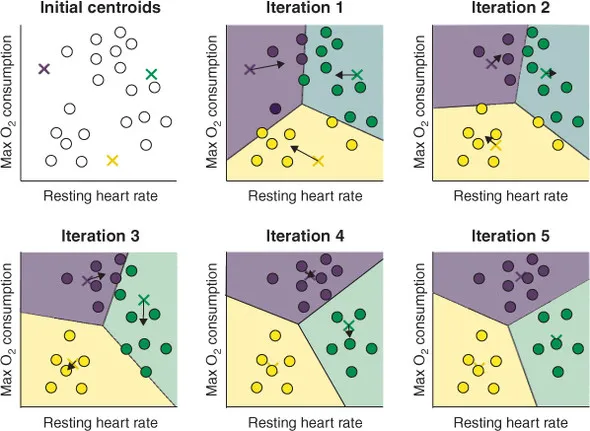
- 3개의 군집 중심점을 설정
- 각 데이터는 가장 가까운 중심점에 소속
- 중심점에 할당된 데이터들의 평균 중심으로 중심점을 이동
- 각 데이터는 이동된 중심점을 기준으로 가까운 중심점에 소속
- 다시 중심점에 할당된 데이터들의 평균 중심으로 중심점 이동
- 중심점을 이동하였지만 데이터들의 중심점 소속 변경이 없으면 반복을 종료한다
k-means 장점
- 일반적인 군집화에서 가장 많이 활용된다
- 알고리즘이 간단하고 쉽다
k-means 단점
- 거리 기반 알고리즘으로 피처의 개수가 매우 많을 경우 군집화 정확도가 떨어진다
- 반복을 수행하는데, 반복 횟수가 많을 경우 수행 시간이 매우 느려진다
- 몇 개의 군집을 선택할 지 가이드 하기 어려울 수 있다
군집 평가(Cluster Evaluation)
- 비지도학습의 특성상 어떠한 지표라도 정확하게 성능을 평가하기는 어렵다
- 대표적으로 실루엣 분석을 사용한다
실루엣 분석(silhouette analysis)
- 실루엣 분석은 각 군집 간의 거리가 얼마나 효율적으로 분리돼 있는지를 나타낸다
- 잘 분리가 됐다는 것은 다른 군집과의 거리는 떨어져 있고 동일 군집끼리의 데이터는 서로 가깝게 뭉처있다는 의미이다
- 실루엣 분석은 실루엣 계수를 기반으로 한다
- 실루엣 계수는 개별 데이터가 가지는 군집화 지표이고 개별 데이터가 가지는 실루엣 계수는 해당 데이터가 같은 군집 내의 데이터와 얼마나 가깝게 군집화돼 있고 다른 군집에 있는 데이터와는 얼마나 멀리 분리돼 있는지를 나타내는 지표이다
- 실루엣 계수는 -1 ~ 1 사이의 값을 가지며, 1로 가까워질수록 근처의 군집과 더 멀리 떨어져 있다는 것이고 0에 가까울수록 근터의 군집과 가까워진다는 것이다. - 값은 아예 다른 군집에 데이터 포인트가 할당되었다는 것이다
- 전체 실루엣계수의 평균값은 1에 가까울수록 좋다
평균 이동(Mean Shift)
- 평균이동은 k-평균과 유사하게 중심을 군집의 중심으로 지속적으로 움직이면서 군집화 한다
- k-means는 데이터의 평균 거리 중심으로 중심점을 이동시키데 반해, Mean shift는 데이터가 모여 있는 밀도가 가장 높은 곳으로 이동한다
- 데이터가 모여있어 확률 밀도 함수가 피크인 점을 군집 중심점으로 선정하며 일반적으로 KDE(Kernel Density Estimation)을 사용
군집화 순서
-
개별 데이터의 특정 반경 내에 주변 데이터를 포함한 데이터 분포도를 KDE 이용하여 계산
-
KDE로 계산된 데이터 분포도가 높은 방향으로 데이터 이동
-
모든 데이터를 1-2까지 수행하면서 데이터를 이동, 개별 데이터들이 군집 중심점에 모임
-
지정된 반복만큼 전체 데이터에 대해 KDE 기반으로 데이터를 이동시키면서 군집화 수행
-
개별 데이터들이 모인 중심점을 군집 중심점으로 설정
.jpg)