GAN이란?
2014년 Ian Goodfellow가 제안한 생성 모델로, 적대적이라는 이름처럼 두개의 신경망이 서로 경쟁하며 학습하는 구조의 모델
GAN의 구조
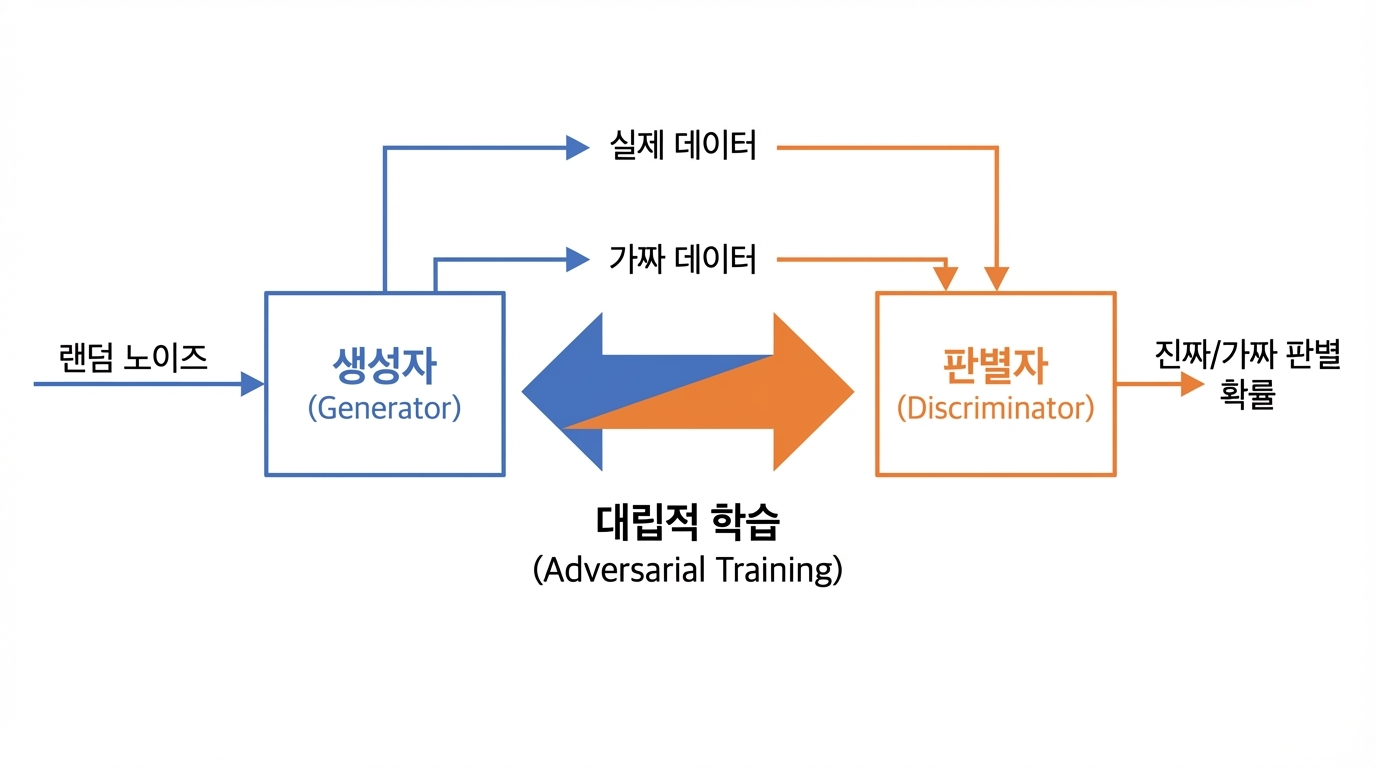
1. 생성자 (Generator)
역할: 가짜 데이터를 생성
입력: 랜덤 노이즈 (보통 정규분포에서 샘플링)
출력: 실제 데이터와 유사한 가짜 데이터
목표: 판별자를 속일 수 있을 만큼 진짜 같은 데이터 생성
2. 판별자 (Discriminator)
역할: 데이터가 진짜인지 가짜인지 판별
입력: 실제 데이터 또는 생성자가 만든 가짜 데이터
출력: 입력 데이터가 진짜일 확률 (0~1 사이 값)
목표: 실제 데이터와 가짜 데이터를 정확하게 구분
GAN의 학습 과정
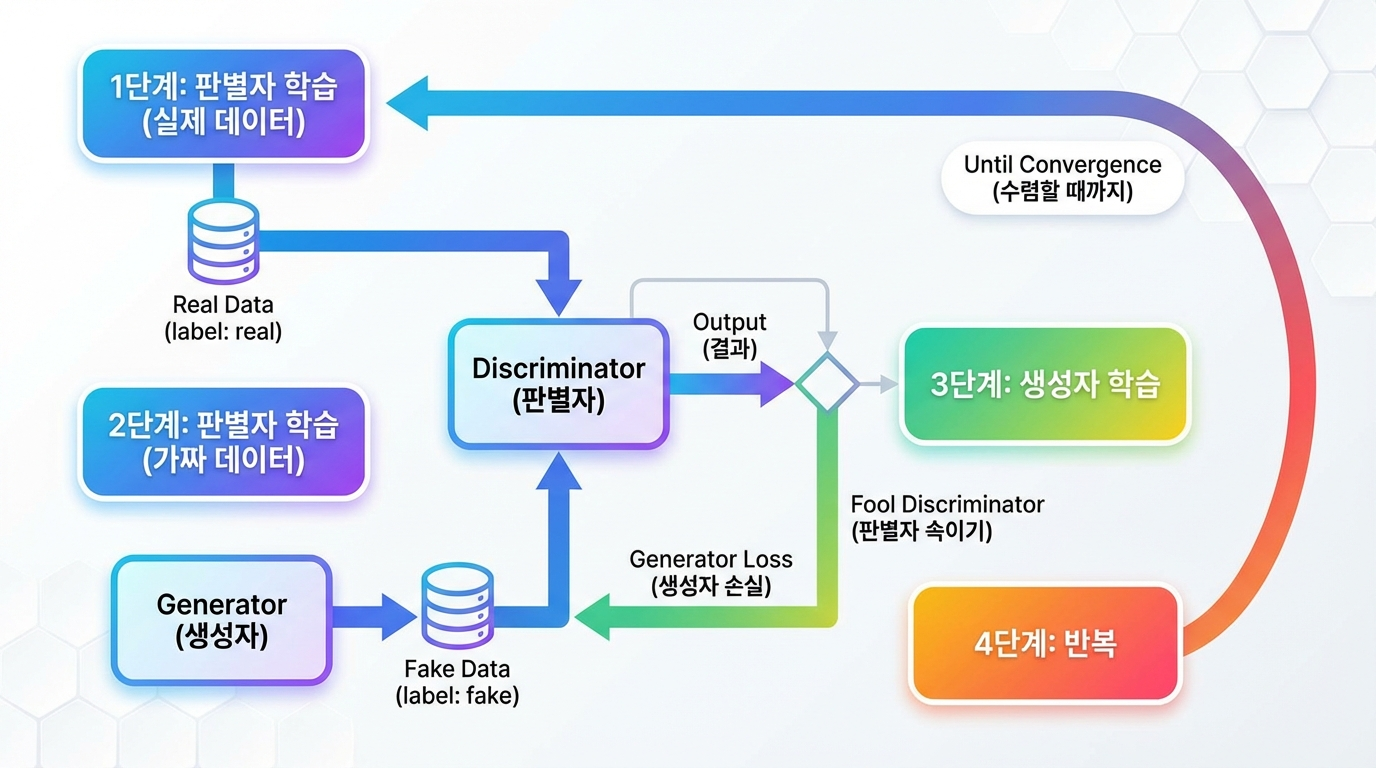
1단계: 판별자 학습 (실제 데이터)
실제 데이터를 판별자에 입력
판별자가 "진짜"라고 높은 확률로 판별하도록 학습
목표: 실제 데이터 → 확률 1.0에 가깝게
2단계: 판별자 학습 (가짜 데이터)
생성자가 만든 가짜 데이터를 판별자에 입력
판별자가 "가짜"라고 낮은 확률로 판별하도록 학습
목표: 가짜 데이터 → 확률 0.0에 가깝게
3단계: 생성자 학습
생성자가 새로운 가짜 데이터 생성
판별자가 이 가짜 데이터를 "진짜"라고 착각하도록 생성자 개선
목표: 판별자를 속이기 (판별자의 출력이 1.0에 가깝게)
4단계: 반복
위 과정을 반복하면서 두 네트워크 모두 점점 강해짐
생성자는 더 진짜 같은 데이터를 만들고, 판별자는 더 정교하게 구분
GAN의 한계
1. Mode Collapse(모드붕괴)
문제: 생성자가 다양한 데이터를 만들지 못하고, 판별자를 속일 수 있는 몇 가지 패턴만 반복 생성
예시:
목표: 다양한 얼굴 이미지 생성
실제 결과: 비슷한 몇 개의 얼굴만 계속 생성
→ 데이터의 다양성 상실생성자가 "이 패턴이면 판별자를 속일 수 있네!"라고 학습
다양성보다는 "속이기 쉬운" 패턴에만 집중
결국 전체 데이터 분포를 학습하지 못함
2. 학습 불안정성 (Training Instability)
문제: 생성자와 판별자의 균형을 맞추기 어려움
Case 1: 판별자가 너무 강함
→ 생성자가 학습할 수 없음 (gradient vanishing)
→ 생성자 발전 멈춤
Case 2: 생성자가 너무 강함
→ 판별자가 항상 헷갈림
→ 의미 있는 피드백 불가능
Case 3: 진동(Oscillation)
→ 두 네트워크가 수렴하지 못하고 계속 요동침
실제 학습 시나리오:
Epoch 1-50: 생성자 우세 → 엉망인 이미지지만 판별자가 구분 못함
Epoch 51-100: 판별자 학습 강화 → 생성자 완전 무력화
Epoch 101-150: 하이퍼파라미터 조정 → 다시 처음부터...
결과: 수백 번의 실험 끝에 겨우 균형 찾기
3. 평가 지표의 부재
생성된 데이터의 품질을 객관적으로 평가하기 어려움
분류 모델: 정확도(Accuracy), F1-Score 등 명확한 지표
GAN: ??? (시각적 평가에 의존)주로 사용하는 평가 방법:
Inception Score (IS): 생성 이미지의 다양성과 품질 측정
Frechet Inception Distance (FID): 실제 데이터와 생성 데이터의 분포 차이
사람의 주관적 평가: 결국 "그럴듯해 보이는가?"로 판단
문제점:
지표와 실제 품질이 항상 일치하지 않음
자동화된 평가가 어려움
4. 학습 데이터에 민감함
문제: 학습 데이터의 품질과 양에 크게 좌우됨
부족한 데이터 → Overfitting → 학습 데이터 복사
편향된 데이터 → 편향된 생성 결과
저품질 데이터 → 저품질 생성물
GAN의 활용사례
-
이미지 생성: 얼굴, 풍경, 예술 작품 생성
[StyleGAN]-고품질 얼굴 생성 -
이미지 변환: 스케치 → 사진, 흑백 → 컬러
[Pix2Pix]-조건부 이미지변환
[CycleGAN]-비지도 학습변환 : 쌍을 이룬학습데이터 없이도 변환가능 -
데이터 증강: 부족한 학습 데이터를 생성
-
초해상도: 저해상도 이미지를 고해상도로 변환
[SRGAN]-이미지 품질 향상 -
스타일 전이: 한 이미지의 스타일을 다른 이미지에 적용
[Neural Style Transfer + GAN]
* 본 글의 다이어그램(GAN 구조도, 학습 과정도, 판별 과정 시각화)은 Genspark AI의 Nano Banana Pro 모델로 제작되었습니다.