
1편에 이어 데이터 import부터 본격적인 데이터 분석을 진행해보겠습니다.
0. 데이터 import
 Figure 1 캡쳐) MYSQL Workbench DATA import 화면
Figure 1 캡쳐) MYSQL Workbench DATA import 화면
Kaggle에서는 CSV파일을 제공합니다. 이 파일을 데이터베이스에 import시키는 과정이 필요합니다. 이 과정에는 두가지 방법이 있는데요. MYSQL의 Workbench에서 지원하는 ‘Table Data Import Wizard’를 사용하면 됩니다.
But, 이는 데이터의 양이 크면 아주 오래 걸립니다! 처음엔 이 과정에서 시간을 많이 허비했습니다.
💡 때문에! 테이블을 직접 생성하고 제약 조건을 설정한 뒤,
LOAD DATA INFILE구문을 이용하여 데이터를import하면 훨씬 빠릅니다.
1. 판매 Data DML 작성하기
제품 판매 데이터를 조작하여 분석해보겠습니다.
편의와 분량상 결과값은 주요 데이터만 공유하겠습니다.
- 총 매출, 판매량, 연도별 판매량
--총매출
SELECT SUM(payment_value) AS total_revenues
FROM olist_order_payments_dataset
;
--총매출(한화)
SELECT SUM(payment_value) * 247.90 AS total_revenues_KRW
FROM olist_order_payments_dataset
;
--총 거래량
SELECT COUNT(*) AS trading_volume
FROM olist_orders_dataset
;
--연도별 판매량
SELECT DATE_FORMAT(order_purchase_timestamp, '%Y') as YEAR, count(*) as Annual_Sales_Volume
FROM olist_orders_dataset
GROUP BY DATE_FORMAT(order_purchase_timestamp, '%Y')판매된 상품의 가격을 총합하여 총 매출을 계산하였고, 헤알(브라질 통화) 단위를 원화로 환율을 계산해보았습니다. (2023년 3월 19일 기준 247.90원)
총 거래량은 판매 데이터의 수를 산출하였습니다.
연도별 판매량은 주문 데이터를 DATA_FORMAT 함수를 통하여 그룹화하여 정의하였습니다.
📍 총 매출은 약 16,008,872 헤알(BRL)으로, 한화 약 4,209,693,012원이네요!
- 평균 배송 기간
orders_dataset에는 다양한 날짜 데이터를 포함하고 있습니다. 이를 활용하여 구매 시점 데이터와 배송 완료 시점 데이터를 연산하여 평균 배송 기간 산출해봅시다.
But, 주문 데이터 중에 도착 정보가 없는 주문 목록이 있습니다!
💡 때문에! 배송 완료 시점이 없는 데이터를 제외시키는 전처리 과정을 쿼리문에 포함시켜주었습니다.
--평균 배송기간
SELECT AVG(date_diff) as delivery_period
FROM
(SELECT DATEDIFF(order_delivered_customer_date, order_purchase_timestamp) as date_diff
FROM olist_orders_dataset
WHERE order_delivered_customer_date != "") DATE📍 delivery_period는 12.4973으로, 평균 약 12.5일 정도 소요됩니다!
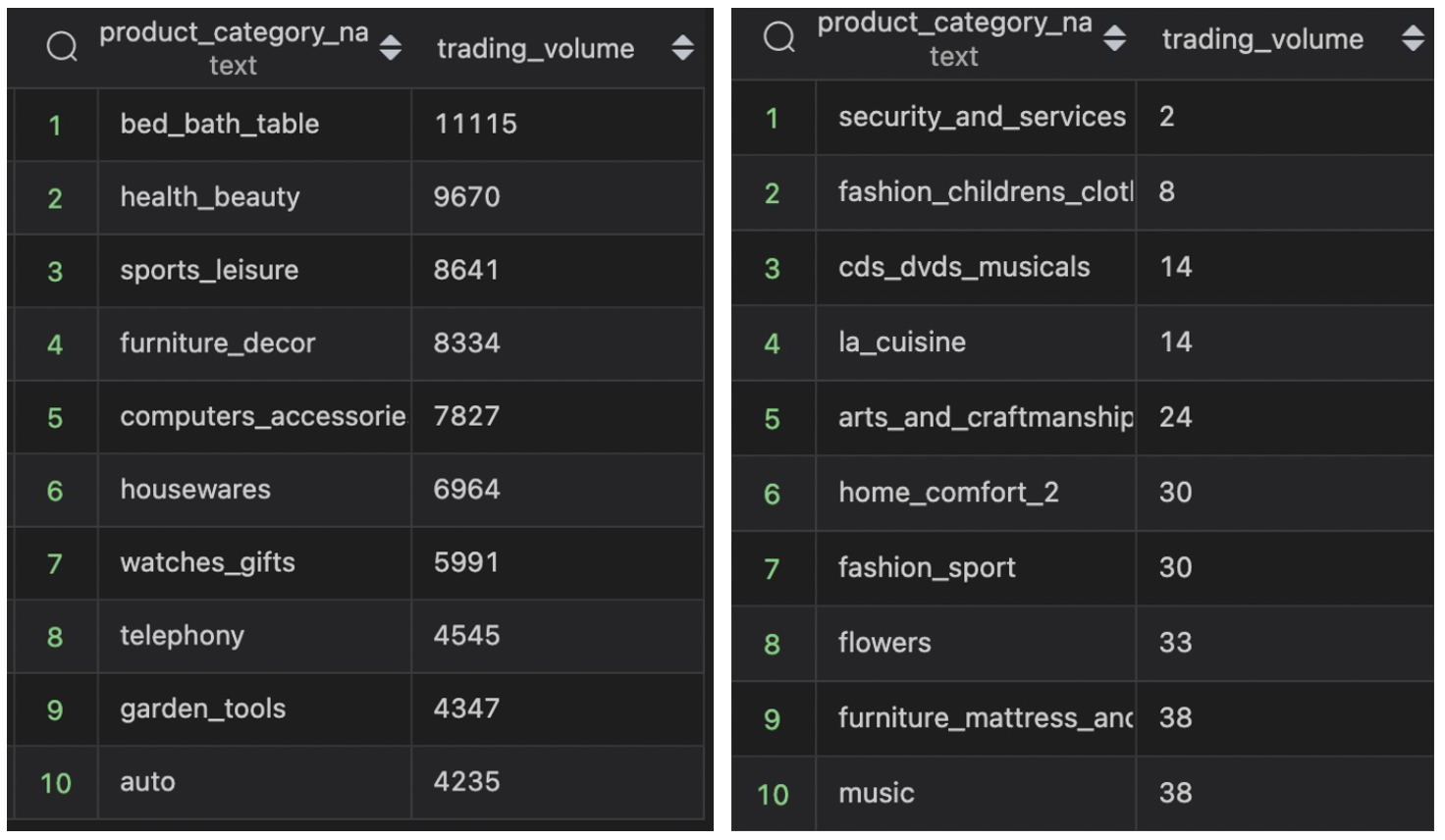
- 카테고리별 판매량, 판매량 상위, 하위 제품 조사하기
이번에는 어떤 카테고리의 제품이 많이 팔리는지 알아보기 위해 상품 카테고리 별로 그룹화하여 판매량을 알아보겠습니다. order_items_dataset을 기준으로 products_dataset을 LEFT JOIN하여 카테고리 이름 기준 그룹화합니다.
But, 카테고리의 이름이 포르투칼어로 구성되어 있어 쉽게 알아볼 수 없었습니다!
💡 때문에! product_category_name_translation 테이블을 이용하여 영어로 이름을 번역해주는 쿼리를 작성해줍니다.
또한, 상하위 10개 목록을 조회하기 위해 LIMIT 함수를 사용합니다.
--카테고리별 판매량
SELECT product_category_name_english, trading_volume
FROM product_category_name_translation T,
(SELECT product_category_name, COUNT(*) AS trading_volume
FROM olist_order_items_dataset O
LEFT JOIN olist_products_dataset P
ON P.product_id = O.product_id
GROUP BY product_category_name
ORDER BY COUNT(*) DESC) V
WHERE T.product_category_name = V.product_category_name
;
--판매량 상위 10 상품 카테고리
SELECT product_category_name_english, trading_volume
FROM product_category_name_translation T,
(SELECT product_category_name, COUNT(*) AS trading_volume
FROM olist_order_items_dataset O
LEFT JOIN olist_products_dataset P
ON P.product_id = O.product_id
GROUP BY product_category_name
ORDER BY COUNT(*) DESC) V
WHERE T.product_category_name = V.product_category_name
LIMIT 10
;
--판매량 하위 10개 상품 카테고리
SELECT product_category_name_english, trading_volume
FROM product_category_name_translation T,
(SELECT product_category_name, COUNT(*) AS trading_volume
FROM olist_order_items_dataset O
LEFT JOIN olist_products_dataset P
ON P.product_id = O.product_id
GROUP BY product_category_name
ORDER BY COUNT(*) ASC) V
WHERE T.product_category_name = V.product_category_name
LIMIT 1
;📍 아래와 같은 데이터를 얻을 수 있었습니다! (상하위 10개 카테고리 결과)
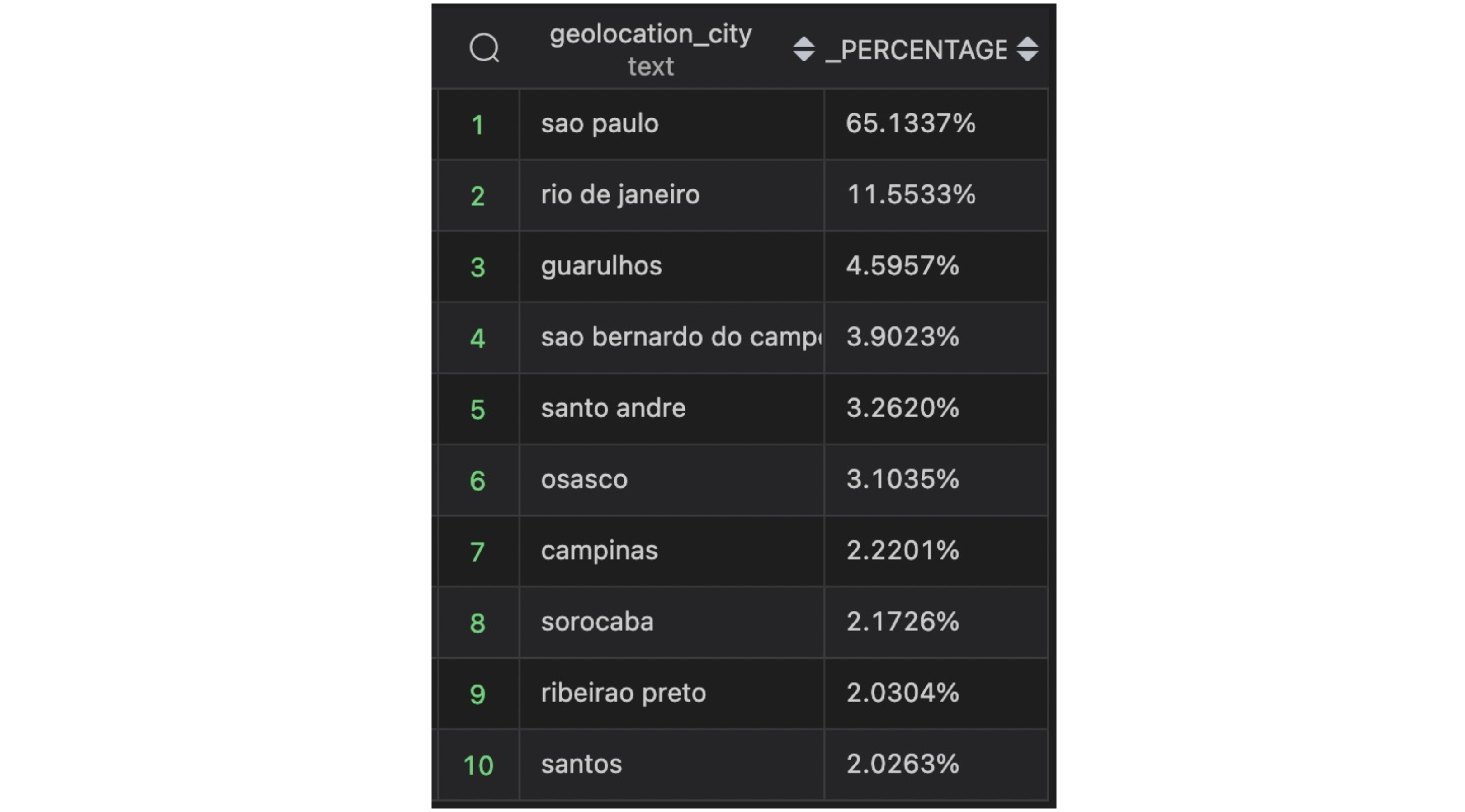
- 주문 지역 분석
어느 지역의 고객이 주문을 많이 하였는가를 알아봅시다. SUM과 COUNT를 각각 해주어 비율을 계산하기 위해 지역별 주문량을 정의한 쿼리 문 두개를 JOIN하여 비율을 산출했습니다.
-- 주문 지역(상위 10) 비율
SELECT geolocation_city, concat(count / summ * 100, "%") AS _PERCENTAGE
FROM
(SELECT SUM(count) AS summ
FROM (SELECT geolocation_city, COUNT(geolocation_city) as count
FROM olist_geolocation_dataset
GROUP BY geolocation_city
ORDER BY count(geolocation_city) DESC
LIMIT 10) city) SUMM
,(SELECT geolocation_city, COUNT(geolocation_city) AS count
FROM olist_geolocation_dataset
GROUP BY geolocation_city
ORDER BY count(geolocation_city) DESC
LIMIT 10) COUNTT📍 아래와 같은 데이터를 얻을 수 있었습니다!
브라질에서 인구가 가장 많은 도시인 '상파울루'에서 약 65%로 가장 많이 주문했네요.
- 카테고리별 매출
다음은 카테고리별로 매출을 계산해보았습니다.
But, 작성한 SQL문이 에러가 뜨지 않고 계속해서 로딩만 되는 문제가 있었습니다. 결과값과 에러문 조차 뜨지 않아 해결하지 못했는데요, 뷰를 이용해서 테이블을 나누어 조회를 시도해봐야 겠습니다.
--카테고리별 매출
--***조회 실패***
SELECT *
FROM
(SELECT O.product_id, P.payment_value
FROM olist_order_items_dataset O, olist_order_payments_dataset P
WHERE O.order_id = P.order_id) _value,
(SELECT O.product_id, P.product_category_name
FROM olist_order_items_dataset O
RIGHT JOIN olist_products_dataset P
ON P.product_id = O.product_id) _category
WHERE _value.product_id = _category.product_id
;- 재구매율과 고객 당 구매 횟수
재구매율과 고객 당 구매 횟수 데이터에 대해 알아보았습니다.
고객 아이디 별로 그룹화하여 주문 아이디를 통해 COUNT하고, 이를 고객 아이디로 다시 COUNT하면 재구매 데이터를 얻을 수 있습니다. 또한 고객 아이디에 대한 주문 아이디를 COUNT하면 한 고객 아이디 당 몇개의 상품을 주문했는지 파악할 수 있습니다.
But, 해당 데이터는 한 고객이 다양한 상품을 주문하면 고유한 고객 아이디가 입력되는 것이 아닌 구매할 때마다 고객 아이디가 새롭게 생성되는 것으로 추정됩니다.
따라서 모든 고객 아이디가 하나의 상품을 구매한 것으로 결과가 나와 무의미한 데이터가 산출되었습니다.
--재구매율
SELECT count(customer_id), freq
FROM(SELECT O.customer_id, COUNT(O.order_id) AS freq
FROM olist_orders_dataset AS O
GROUP BY O.customer_id) C
GROUP BY freq
;
--고객당 구매 횟수
SELECT O.customer_id, COUNT(O.order_id) AS re_purchase
FROM olist_orders_dataset AS O
GROUP BY O.customer_id
;👉 다음 포스팅에서는!
고객 만족도 데이터에 대해 알아보고, 직접 구현한 Membership System에 대해 소개하겠습니다.
