
2편에 이어 이번에는 고객 만족도 Data를 분석해보겠습니다.
- 별점 당 평점 수, 평점 평균
주문 리뷰 데이터를 별점별로 그룹화하여 COUNT해서 별점 당 평점 수에 대해 알아보고, AVG함수를 통해 평점 평균에 대해 알아보았습니다.
--평점 수
SELECT review_score, COUNT(review_score) AS CNT
FROM olist_order_reviews_dataset
GROUP BY review_score
ORDER BY review_score DESC
;
--평점 평균
SELECT AVG(review_score)
FROM olist_order_reviews_dataset
;📍 아래와 같은 데이터를 얻을 수 있었습니다! 전체 평점 평균은 약 4.0으로, 준수한 편이네요.
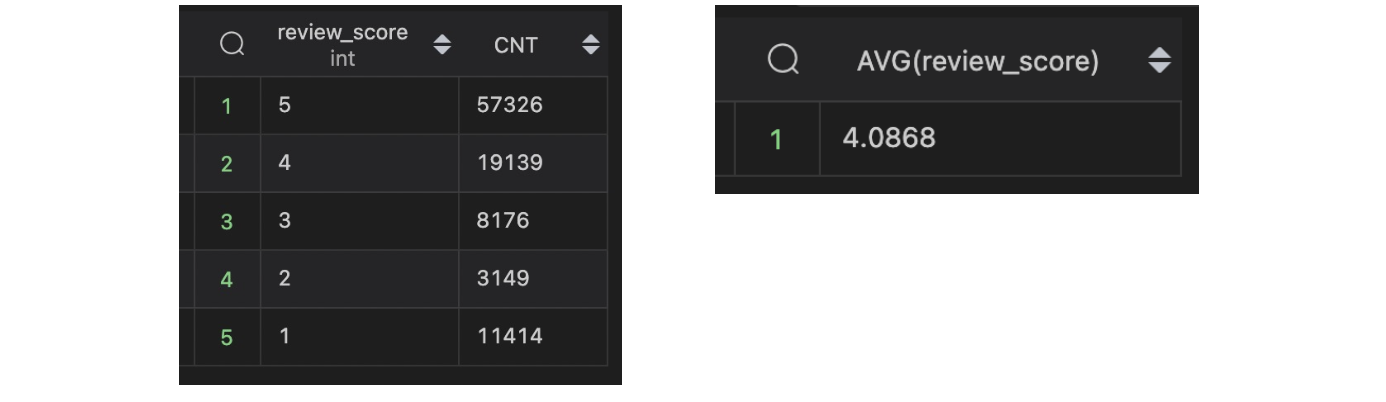
- 평점 비율
앞에서 산출한 평점 수 쿼리를 서브쿼리로 이용하여 비율을 계산했습니다. 같은 쿼리 두개를 JOIN하여 SUM과 COUNT를 해줍니다.
--평점 비율
SELECT review_score, concat(cnt / summ * 100, "%") AS _PERCENTAGE
FROM
(SELECT SUM(CNT) AS SUMM
FROM
(SELECT review_score, COUNT(review_score) AS CNT
FROM olist_order_reviews_dataset
GROUP BY review_score
ORDER BY review_score DESC) C) SUMM
,(SELECT review_score, COUNT(review_score) AS CNT
FROM olist_order_reviews_dataset
GROUP BY review_score
ORDER BY review_score DESC) CNT
;📍 아래와 같은 데이터를 얻을 수 있었습니다!
NPS 지수 (순수고객추천지수) 측정
💡 NPS란?
Net Promoter Score의 약자로 간단히 말해 브랜드에 대한 고객 충성도를 알 수 있는 지표입니다.
11점 척도를 기준으로 산출하나, 5점 척도 평점을 제공하였으므로 5점을 기준으로 산출하겠습니다.
- 1~3점이 Detractors, 4점이 Passives, 5점이 Promoters.
- NPS = Promoters(%) - Passives(%)
여기서 뷰 기능을 활용하여 이전 평점 비율 쿼리로 뷰를 생성하였습니다.
--view 생성하여 산출해보기.
CREATE View REVIEW
AS
SELECT review_score, concat(cnt / summ * 100, "%") AS _PERCENTAGE
FROM
(SELECT SUM(CNT) AS SUMM
FROM
(SELECT review_score, COUNT(review_score) AS CNT
FROM olist_order_reviews_dataset
GROUP BY review_score
ORDER BY review_score DESC) C) SUMM
,(SELECT review_score, COUNT(review_score) AS CNT
FROM olist_order_reviews_dataset
GROUP BY review_score
ORDER BY review_score DESC) CNT
;--NPS Score
SELECT Promoters._PERCENTAGE - Passives._PERCENTAGE AS NPS_score
FROM
(SELECT _PERCENTAGE
FROM review
WHERE review_score = "5") Promoters,
(SELECT _PERCENTAGE
FROM review
WHERE review_score = "4") Passives
;📍 NPS 지수는 38점으로 산출되었습니다.
NPS 지수를 개발한 베인컴퍼니의 기준으로 좋은 수준의 점수라고 할 수 있습니다. 이에 대해 카테고리별 NPS 지수가 더 명확하고 의미있는 자료라 판단되어 구현해보려 했으나 부족한 실력과 시간으로 인해 원하는 결과값을 얻지 못했습니다.
--베인컴퍼니의 NPS 기준
0 이상일 경우: 괜찮은 점수다.
20 이상일 경우: 좋은 수준의 점수다.
50 이상일 경우: 훌륭한 점수다.
80 이상인 경우: 세계적인 수준의 점수다.
- 평점이 많은 카테고리
평점(리뷰)가 많이 작성된 카테고리에 대해 알아보겠습니다.
But, 상품 중에는 카테고리가 없는 상품이 존재합니다!
💡 때문에! 카테고리가 없는 상품을 걸러주는 쿼리문을 포함시켜 전처리를 해줍니다.
카테고리 이름, 상품 아이디 쿼리를 기준으로 리뷰 데이터를 LEFT JOIN 하고, 이를 카테고리 이름을 기준으로 그룹화, 리뷰 수 카운트로 내림차순을 한 후 카테고리 이름을 영어로 번역해주었습니다.
--평점이 많은 상품 카테고리
SELECT product_category_name_english, NumOfREVIEW
FROM product_category_name_translation T,
(SELECT ID.product_category_name, COUNT(R.review_score) AS NumOfREVIEW
FROM
(SELECT P.product_category_name, O.order_id
FROM olist_order_items_dataset O, olist_products_dataset P
WHERE O.product_id = P.product_id AND
product_category_name != "") ID --카테고리가 없는 상품 걸러줘야 함.
LEFT JOIN olist_order_reviews_dataset R
on ID.order_id = R.order_id
GROUP BY ID.product_category_name
ORDER BY COUNT(R.review_score) DESC) R
WHERE T.product_category_name = R.product_category_name
;- 평점 5점을 많이 받은 카테고리
평점 5점을 많이 받은 카테고리도 찾아보았습니다. 이전 쿼리문과 형태는 비슷하나, 평점 5점을 받은 카테고리만 노출되도록 WHERE절에 추가적인 옵션을 만들어주었습니다.
SELECT product_category_name_english, 5score
FROM product_category_name_translation T,
(SELECT C.product_category_name, COUNT(review_score) AS 5score
FROM
(SELECT O.order_id, P.product_category_name
FROM olist_order_items_dataset O, olist_products_dataset P
WHERE O.product_id = P.product_id) C,
olist_order_reviews_dataset R
WHERE C.order_id = R.order_id AND
R.review_score = '5'
GROUP BY C.product_category_name
ORDER BY COUNT(review_score) DESC) R
WHERE T.product_category_name = R.product_category_name
;
📍 평점 5점을 가장 많이 카테고리로는 'health_beauty'로, 5857개를 받았습니다. 'bed_bath_table'(5785개), 'sport_leisure'(5121개), 'furniture_decor'(4452개)...
Membership System 구현해보기
수업에서 배운 TRIGGER 기능을 활용해보기 위해 Membership System을 만들어 보았습니다.
But, 해당 데이터셋이 계속해서 새로운 데이터가 입력되지 않는 상태이고, (2)편의 '재구매율과 고객 당 구매 횟수'에서 보았듯 고객별 고유 아이디가 구매할 때 마다 생성되어 구매 횟수 축적이 안되는 문제점이 있었습니다.
💡 때문에! TRIGGER를 이용하여 기능만 구현해보았습니다.
멤버쉽 테이블을 하나 더 만듭니다. 저는 구매 횟수 구간 별로 브론즈, 실버, 골드, 플래티넘 등급을 부여할 것인데요, 이에 그레이드 컬럼의 디폴트 값을 브론즈로 설정하고, 아이디는 고객 정보의 고객 아이디를 참조합니다. 또한 재구매 횟수는 이전 고객당 구매횟수 테이블을 뷰로 생성하여, 아이디와 재구매 횟수 전체를 멤버쉽 테이블에 인서트해주었습니다.
--trigger 이용 멤버쉽 시스템 만들기
--Membership Table 생성
CREATE TABLE Membership(
Grade CHAR(10) DEFAULT "Bronze",
ID CHAR(32),
re_purchace SMALLINT,
PRIMARY KEY (ID)
FOREIGN KEY (ID) REFERENCES olist_customers_dataset(customer_id));
;'Grade'의 DEFAULT값을 "Bronze"로 하여 가입 첫 등급을 설정하였습니다.
--Merbership에 고객데이터 삽입
INSERT INTO Membership(ID, re_purchace)
SELECT customer_id, re_pur
FROM repur
;이전의 '고객 당 구매 횟수' 테이블의 정보를 'Membership' 테이블에 삽입합니다.
--trigger 생성
DELIMITER //
CREATE TRIGGER MembershipSystem
AFTER UPDATE ON REPUR
FOR EACH ROW
BEGIN
IF R.re_pur >= 5 THEN
UPDATE Membership
SET M.Grade = "Silver"
FROM REPUR R, Membership M
WHERE R.customer_id = M.ID;
ELSE IF R.re_pur >= 10 THEN
UPDATE Membership
SET Grade = "Gold"
WHERE REPUR.customer_id = Membership.ID;
ELSE IF R.re_pur >= 15 THEN
UPDATE Membership
SET Grade = "Platinum"
WHERE REPUR.customer_id = Membership.ID;
END IF;
END ;//
DELIMITER
;REPUR(고객 당 구매 횟수) 테이블이 업데이트되면 TRIGGER가 발동됩니다.
5회 이상 구매 시 Grade를 "Silver"로, 10회 이상 구매 시 Grade를 "Gold"로, 15회 이상 구매 시 Grade를 "Platinum"으로 UPDATE합니다.
코드 상단과 하단의 DELIMITER는 트리거의 중간중간에 들어가는 세미콜론(;)과 구분해주기 위한 문법입니다.
📍 확인해봅시다!
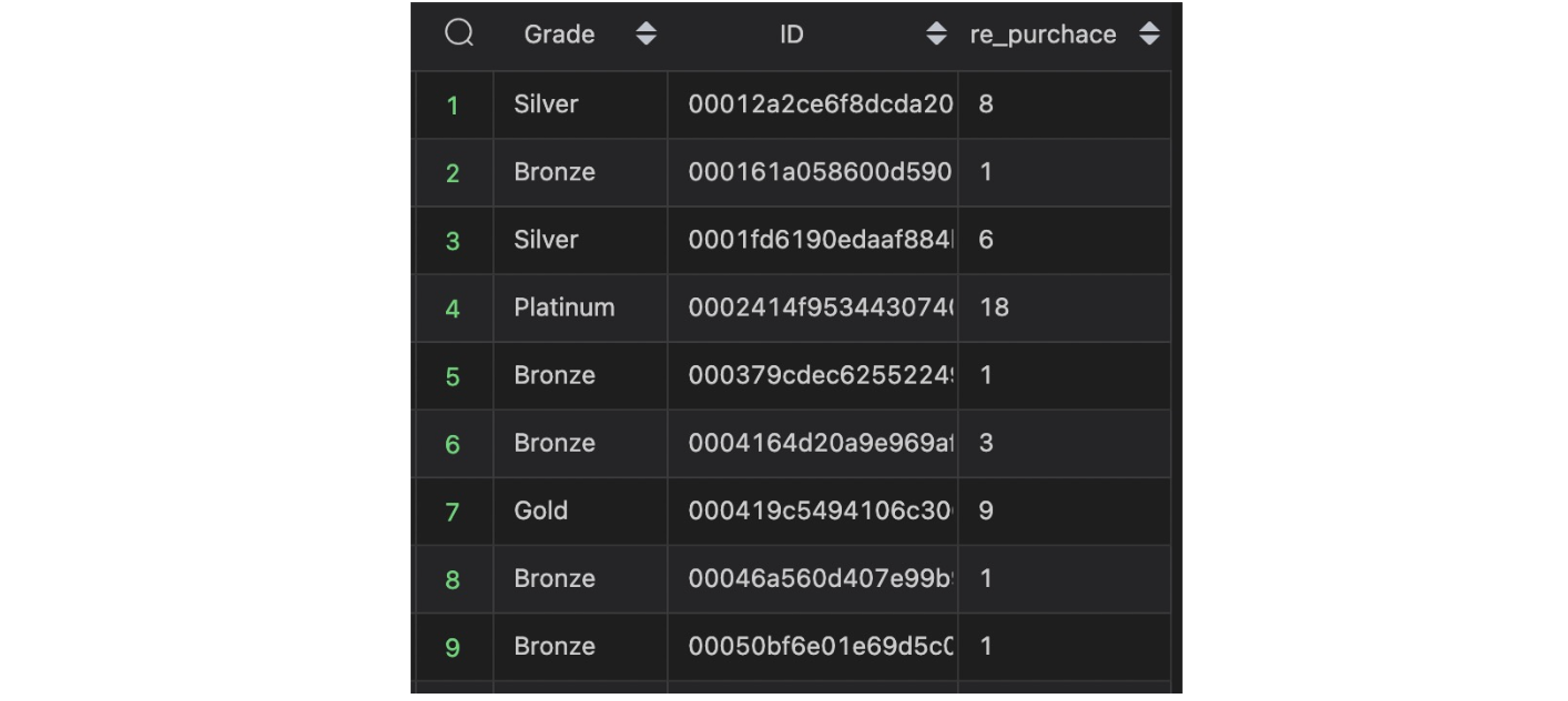
앞서 말씀드렸듯 해당 데이터셋이 계속해서 새로운 데이터가 입력되지 않는 상태이기 때문에 REPUR 테이블을 인위적으로 조작하여 Membership System이 잘 작동하는지 확인해보았습니다.
Feedback
이번 분석 과제의 피드백을 받기 위해 현직에서 일하시는 학교 선배에게 피드백을 받아보았습니다!
1. Table JOIN 시,
SELECT table1.column, table2.column
FROM table1, table2
WHERE table1.column = table2.column위와 같은 WHERE절에서 비교연산자(=)를 이용한 JOIN보다
SELECT table1.column, table2.column
FROM table1 JOIN table2
ON table1.column = table2.columnJOIN - ON 키워드를 이용하여 직접 JOIN하는 것이 상대적으로 더 가독성이 좋고, 최신의 방식이며 효율적이라고 합니다.
2. 코드 가독성을 위해 행갈이를 자주 해주자.
--출처 : datarian's velog
SELECT day, time, SUM(total_bill)
FROM tips
WHERE sex = 'Female' AND smoker = 'Yes'
GROUP BY day, time위와 같이 행 구분이 없는 코드보다,
SELECT day
, time
, SUM(total_bill)
FROM tips
WHERE sex = 'Female'
AND smoker = 'Yes'
GROUP BY day
, time이와 같이 행 구분이 되어있는 코드가 가독성이 좋습니다.
참고 코드 출처 : datarain's velog (SQL 가독성을 높이는 다섯 가지 사소한 습관)
지금까지 Kaggle 데이터셋을 활용하여 SQL 데이터 분석 과제를 해보았습니다.
비전공자에 DB에 대한 지식이 많이 부족하여 잘못된 설명이나 오류가 있을 수 있습니다!
잘못된 정보가 있다면 피드백 부탁드립니다.
감사합니다!
