지도학습 알고리즘 중 하나인 DT에 대해 알아보자.
Decision Tree(의사결정나무)는 데이터를 반복적으로 분할하면서 규칙을 만들어 예측을 수행하는 모델이다. 사람이 조건을 따라 결정을 내리는 과정과 유사한 구조를 가지기 때문에 모델의 동작 방식이 직관적이고 해석이 쉽다는 특징이 있다.
1. DT의 기본 개념
Decision Tree는 각 노드에서 하나의 feature를 선택하고,
그 feature에 대해 특정 기준값(threshold)을 기준으로 데이터를 분할한다.
즉 "이 조건을 만족하면 이쪽, 아니면 저쪽" 이라는 질문을 반복하며 데이터를 분류하는 모델이다.
이 과정을 반복해 트리 구조를 만들며, 최종적으로 leaf node 에서 예측을 수행한다.
DT는 분류와 회귀 둘 다에서 사용할 수 있는 알고리즘이다.
- 분류(Classification): 가장 많은 클래스를 예측
- 회귀(Regression): 해당 노드에 포함된 값들의 평균을 예측
2. DT의 특징 및 장점
특징
Decision Tree의 핵심적인 특징은
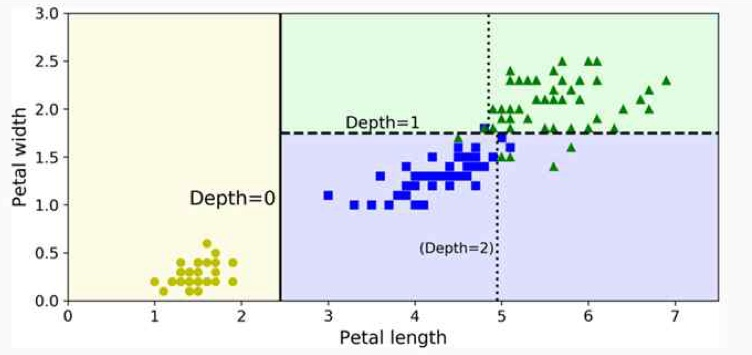
feature 공간을 항상 좌표축에 수직인 방향으로만 분할한다는 점이다.
예를 들어,
petal length < 2.45petal width ≥ 1.75
와 같은 조건으로 분할이 이루어진다.
이는 곧
- 2차원 공간에서는 수직선 또는 수평선
- 3차원 공간에서는 좌표축에 평행한 평면
으로만 영역을 나눈다는 뜻이다.
즉, Decision Tree는
SVM처럼 기울어진 직선이나 곡선 형태의 결정 경계를 직접 만들지 못하고,
여러 개의 축에 수직인 분할을 이어 붙인 계단형(decision boundary) 구조를 형성한다.
이 특성 덕분에 분할 기준이 명확하고 사람이 이해하기 쉬운 규칙 형태로 표현되지만,
동시에 결정 경계가 부자연스럽게 꺾이거나 복잡한 패턴을 표현하기 위해 트리가 깊어지는 한계도 함께 가진다.
장점
- 모델 구조가 직관적 → 해석이 매우 쉬움
- 정규화 필요 없음 (거리 기반 알고리즘이 아님)
- 수치형 / 범주형 feature 모두 사용 가능
- 분류(Classification)와 회귀(Regression) 모두 적용 가능
- 비선형 관계를 자연스럽게 표현 가능
- 탐색적 데이터 분석(EDA)에 매우 유용
3. 분할 기준 (Impurity Measure)
Decision Tree는
“어떤 기준으로 나누는 것이 가장 잘 나누는 것인가?”를
불순도(impurity) 지표를 통해 판단한다.
대표적인 기준은 Gini impurity 와 Entropy(Information Gain) 이다.
Gini Impurity
- pₖ: 해당 노드에서 클래스 k의 비율
- 값이 0에 가까울수록 → 한 클래스만 존재 (잘 분리됨)
- 값이 클수록 → 클래스가 섞여 있음
각 분할 이후의 Gini impurity가 가장 많이 감소하는 방향으로 분할을 수행한다.
Entropy
Entropy는 불확실성의 정도를 의미한다.
- 클래스 분포가 균등할수록 Entropy 최대
- 한 클래스만 있으면 Entropy = 0
4. DT의 단점과 불안정성(Instability)
Decision Tree의 가장 큰 특징이자 약점은
데이터에 매우 민감하다는 점, 즉 불안정성(instability) 이다.
왜 작은 데이터 변화에 민감할까?
Decision Tree는
각 노드에서 현재 시점에서 가장 impurity를 많이 줄이는 분할을 선택하는
탐욕적(greedy) 알고리즘이다.
이 때문에 데이터가 아주 조금만 바뀌어도 impurity 계산 결과가 달라지고, 선택되는 feature나 threshold가 달라질 수 있다.
특히 최상위 노드(root node)의 분할이 달라지면 그 아래의 모든 분기 구조가 연쇄적으로 달라진다.
즉,
초기 분할이 조금만 달라져도 트리 전체 구조가 완전히 바뀔 수 있다.
따라서 데이터의 아주 작은 변화나 일부 샘플의 추가·제거만으로도
트리 구조와 decision boundary가 크게 변하게 된다.
왜 데이터 회전(rotation)에 민감할까?
Decision Tree는 앞서 언급했듯 항상 좌표축에 수직한 방향으로만 분할한다.
따라서 데이터가 회전되면 원래는 한 번의 분할로 잘 나뉘던 데이터도 여러 번의 계단형 분할이 필요해진다.
결과적으로
- 트리가 더 깊어지고
- 구조가 복잡해지며
- 과적합(overfitting) 위험이 증가한다.
즉, Decision Tree는 데이터의 표현 방식(좌표계)에 매우 민감한 모델이라고 볼 수 있다.
5. 과적합을 막기 위한 정규화(Regularization)
Decision Tree는 구조 자체를 제한함으로써 과적합을 방지한다.
대표적인 하이퍼파라미터:
max_depth: 트리의 최대 깊이 제한min_samples_split: 분할을 허용하는 최소 샘플 수max_leaf_nodes: leaf node 최대 개수max_features: 분할 시 고려할 feature 수 제한
이러한 제약을 통해 지나치게 복잡한 트리 생성을 방지하고 일반화 성능을 높인다.
6. 정리
- Decision Tree는 해석 가능한 모델의 대표 주자
- 단독 사용 시 과적합과 불안정성에 취약
- 하지만 구조를 이해하면 머신러닝 전반의 흐름을 이해하는 데 큰 도움
- 실제 실무에서는 Random Forest, Gradient Boosting의 핵심 구성 요소로 활용됨
DT 예제 (코드)
이제 titanic 데이터셋을 통해 생존인지 아닌지 분류하는 코드를 살펴보자.
1. 데이터 전처리 (Feature 선택 + 범주형 변환 + 결측치 제거)
# 데이터 전처리
df = df[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Survived']] # 승객의 생존여부 예측을 위한 Feature
df['Sex'] = df['Sex'].map({'male': 0, 'female': 1}) # sex열을 숫자로 변환: 모델 입력은 숫자만 가능
df = df.dropna() # dropna(), 값이 없는 데이터 삭제. 즉 결측치 제거
X = df.drop('Survived', axis=1) # 입력 변수 X: 생존에 영향을 주는 특성들
y = df['Survived'] # 타겟 변수 y: 생존 여부(사망=0, 생존=1) 즉 'Survived'를 예측 레이블로 사용1-1. Feature 선택
Pclass: 객실 등급 (1등석/2등석/3등석)Sex: 성별Age: 나이SibSp: 함께 탑승한 형제/배우자 수Parch: 함께 탑승한 부모/자녀 수Fare: 요금Survived: 정답 레이블(생존=1, 사망=0)
이 중 Survived는 정답(y) 이므로 학습 입력(X)에서는 제거한다.
1-2. 범주형 처리: Sex를 숫자로 매핑
- 머신러닝 모델은 입력을 수치로 받기 때문에
male/female같은 문자열을0/1로 바꿔준다.
1-3. 결측치 제거
df.dropna()는 결측치가 포함된 행을 통째로 삭제한다.- Titanic 데이터는
Age등에 결측이 많은 편이라
dropna로 샘플 수가 줄어들 수 있다는 점은 참고할 만하다.
(대안: 평균/중앙값 대체, 모델 기반 대체 등)
2. 학습/테스트 데이터 분리
# Training / Test
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1) # 데이터를 훈련용(80%)와 테스트용(20%)으로 분리train_test_split의 기본값은test_size=0.25(즉 학습 75%, 테스트 25%)다.
주석의 “80/20”은 관례적 표현이지만, 이 코드 그대로라면 기본값 기준으로 나뉜다.random_state=1
→ 데이터 분할 결과를 고정해 실행할 때마다 같은 결과가 나오게 한다.
3. Decision Tree 모델 학습
# Model (DT) , fit():Model training
from sklearn import tree
model = tree.DecisionTreeClassifier()
model.fit(X_train, y_train) # 모델 훈련DecisionTreeClassifier()를 아무 옵션 없이 쓰면
트리가 깊어질 수 있는 방향으로 학습되며(제약이 약함), 과적합 위험이 커질 수 있다.fit()은 학습 데이터로 트리 규칙을 만들어 모델을 훈련시키는 단계다.
4. 학습된 트리 시각화
from sklearn.tree import plot_tree
plt.figure(figsize=(12,8))
plot_tree(model, feature_names=X.columns, filled=True)
plt.show()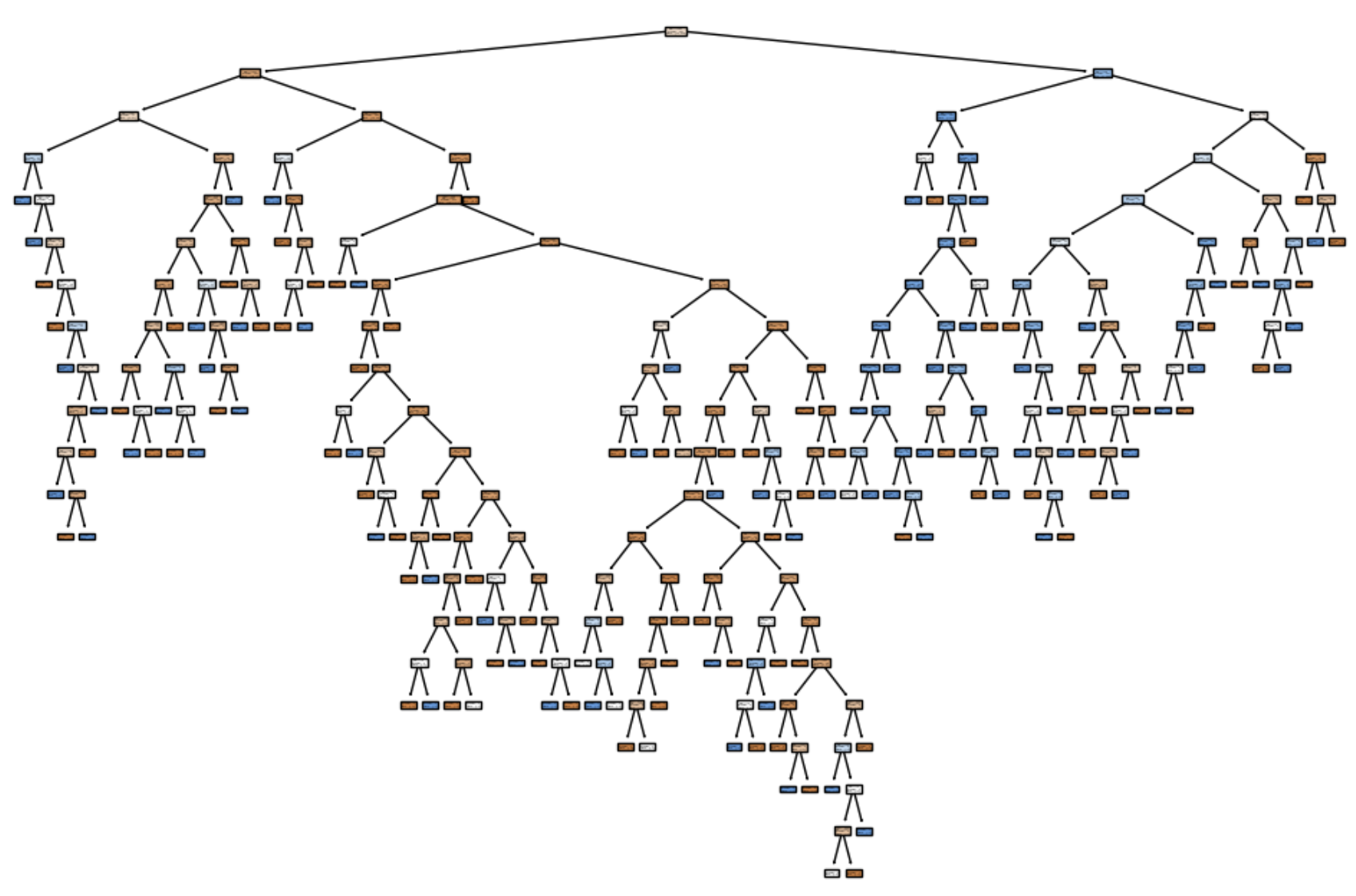
DT의 기본적인 구조이다. 시각화된 모습을 보면 알겠지만 상당히 복잡하다.
5. 깊이 제한 + 지니 기준 지정한 DT 학습 및 시각화
model = tree.DecisionTreeClassifier(max_depth=3, criterion='gini',random_state=1) #트리의 최대 깊이를 3으로 제한, 지니지수로 불순도 계산
model.fit(X_train, y_train)
plt.figure(figsize=(15, 10)) # 그림 크기 조절
plot_tree(
model,
feature_names=X.columns,
class_names=['Died', 'Survived'], # 0과 1의 클래스 이름
filled=True, # 색상 채우기
rounded=True, # 박스 모서리 둥글게
fontsize=10 # 글자 크기 조절
)
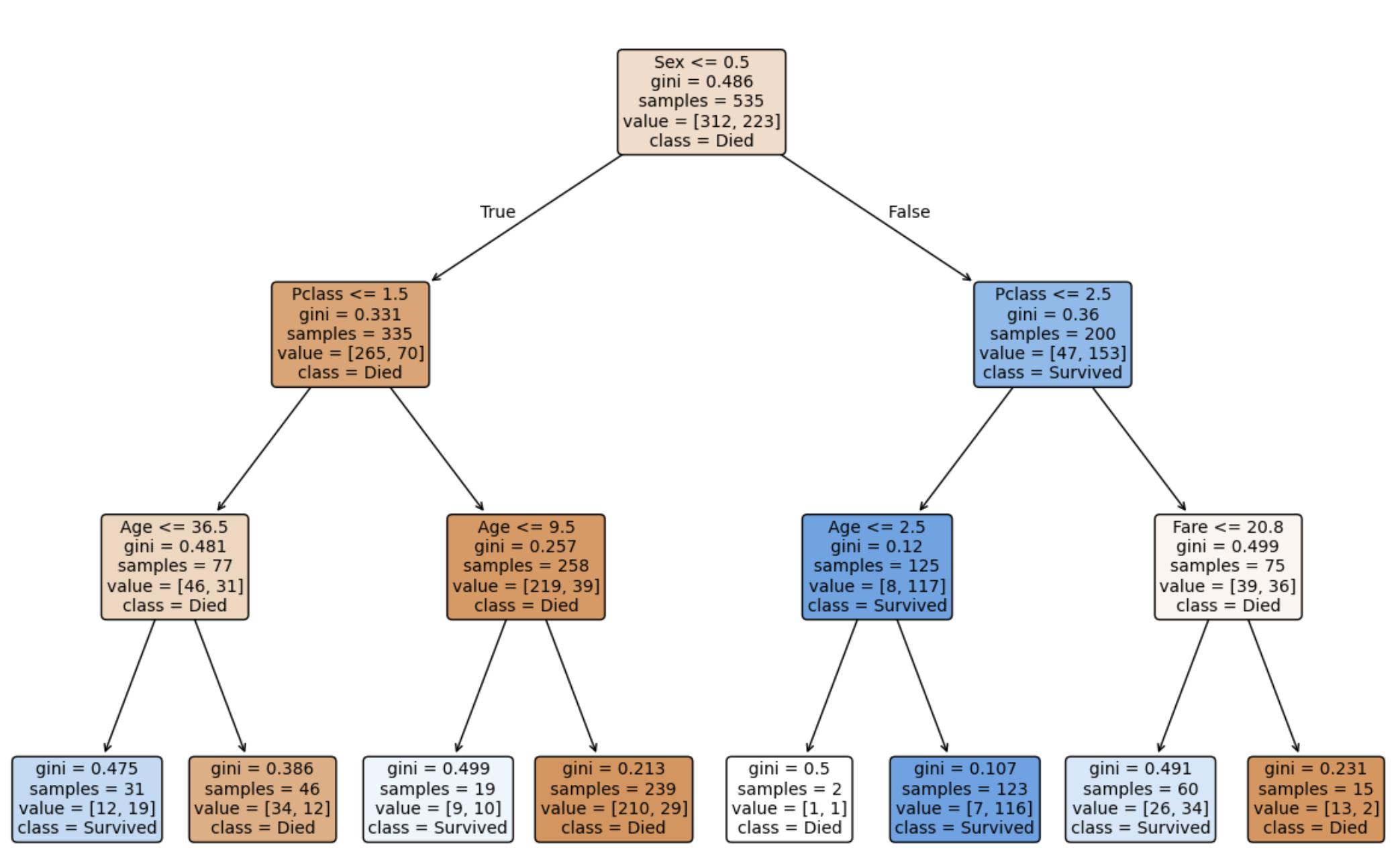
plt.show()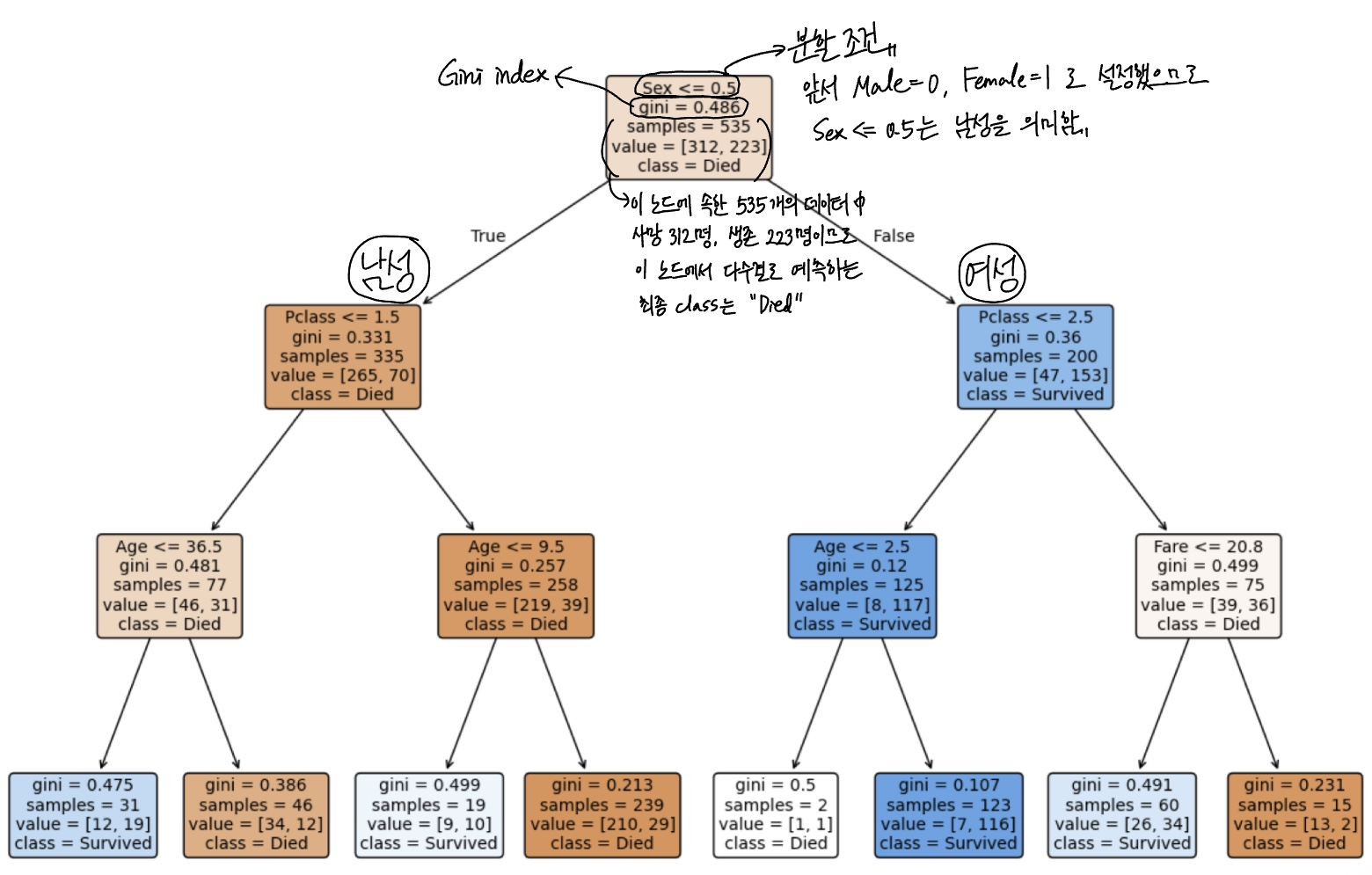
5-1. max_depth=3의 의미
- 트리의 최대 깊이를 3으로 제한해 모델 복잡도를 낮춘다.
- 깊이가 제한되면:
- 규칙이 단순해져 해석이 쉬워지고
- 학습 데이터에 과하게 맞춰지는 과적합이 줄어들 가능성이 높다.
- 즉, 기본 트리(제약 없음) vs 깊이 제한 트리(제약 있음)를 비교해보면
“트리가 깊어질수록 과적합이 쉬워진다”를 직관적으로 확인할 수 있다.
5-2. criterion='gini'
- 분할 기준으로 지니 불순도를 사용한다.
- 분할은 “불순도가 가장 많이 감소하는” 방향으로 진행된다.
5-3. class_names
- 0/1을 의미 있는 이름으로 바꿔 시각화 해석을 쉽게 만든다.
- 0 → Died
- 1 → Survived
6. 정리
- Titanic 데이터(train.csv)로 생존 여부(0/1) 분류 모델을 만든다.
- Decision Tree가 어떤 feature를 어떤 기준으로 분할하는지 시각화로 확인한다.
- 깊이 제한(
max_depth)을 주면 모델이 단순해지고, 과적합을 줄이는 방향으로 제어할 수 있다.
