앞선 포스트(DT)에서는 Decision Tree가 왜 데이터의 아주 작은 변화나 feature 공간의 회전만으로도 트리 구조와 decision boundary가 크게 달라지는지, 즉 과적합이 발생하는 근본적인 이유를 중심으로 정리하였다.
이번 포스트에서는 그 문제의식에서 출발해 Random Forest가 왜 등장했는지, 그리고 앙상블(Ensemble) 학습의 관점에서 Random Forest가 어떻게 Decision Tree의 약점을 보완하는지를 흐름 중심으로 정리한다.
1. Ensemble Learning의 기본 아이디어
Ensemble(앙상블)은 여러 개의 모델을 함께 사용해 예측 성능을 높이는 방법이다.
직관적으로 보면, 한 전문가의 판단보다 여러 전문가의 의견을 종합한 판단이 더 안정적인 경우가 많다. 머신러닝에서도 마찬가지로, 하나의 모델이 낸 예측보다 여러 모델의 예측을 결합한 결과가 일반적으로 더 좋은 성능을 낸다. 이 아이디어가 바로 앙상블의 출발점이다.
Ensemble learning의 목표
- 서로 다른 관점을 가진 모델들을 결합
- 개별 모델의 오류를 상쇄
- 전체 예측의 신뢰도와 일반화 성능 향상
2. 왜 Decision Tree는 Ensemble에 적합한가?
Decision Tree는 단독 모델로 보면 불안정하지만,
앙상블의 base model로서는 매우 적합한 특성을 가진다.
- 학습 속도가 빠름 (Low computational complexity)
- 데이터 분포 가정이 필요 없는 비모수(non-parametric) 모델
- 구조가 단순해 여러 개를 만들어도 부담이 적음
즉,
불안정하지만 만들기 쉬운 모델
→ 여러 개를 모아 쓰기에 이상적
3. Ensemble의 핵심: 다양성 & 무작위성
앙상블이 효과를 내기 위한 핵심 조건은 다양성과 무작위성이다.
다음 두 조건이 만족될 때,
ensemble model은 base model보다 우수해진다.
- Base model들이 서로 다른 예측을 낼 것
- Base model 각각이 무작위 예측보다 나을 것
Random Forest는 다양성과 무작위성을 확보하기 위해 Bagging과 Random subspace라는 두 가지 개념을 도입한다.
4. Bagging (Bootstrap Aggregating)
4.1 Bootstrap Sampling
Bagging의 첫 단계는 bootstrap sampling이다.
- 원본 학습 데이터에서
- 중복을 허용한 랜덤 샘플링 (sampling with replacement) = 복원추출
- 원본과 같은 크기의 여러 학습 데이터셋 생성
이렇게 만들어진 데이터셋을 bootstrap set이라 부른다.
각 Decision Tree는
- 서로 다른 bootstrap set으로 학습되며
- 특정 샘플에 과도하게 의존하는 현상이 줄어든다.
4.2 Result Aggregating (결과 결합)
여러 트리가 예측한 결과는 하나로 합쳐야 한다.
(1) Hard Voting (Majority Voting)
- 각 트리의 예측 클래스를 그대로 사용
- 가장 많이 나온 클래스를 최종 예측으로 선택
(2) Weighted Voting
- 단순 다수결이 아니라 가중치를 부여
- 가중치는 보통
- 학습 정확도
- 예측 확률(prediction probability)
등을 기준으로 설정
Random Forest 분류에서는
- 기본적으로 다수결(hard voting)
- 확률 기반 평균도 함께 활용 가능
5. Random Subspace (Feature Randomness)
Bagging만 사용하면,
- 데이터는 달라지지만
- 여전히 중요한 feature가 반복적으로 선택될 수 있다.
이를 방지하기 위해 Random Forest는
Random Subspace 기법을 추가로 사용한다.
핵심 아이디어
- 전체 feature 중 일부만 무작위로 선택
- split 시에도 모든 feature를 보지 않음
즉,
각 트리는 서로 다른 데이터 + 서로 다른 feature 공간에서 학습
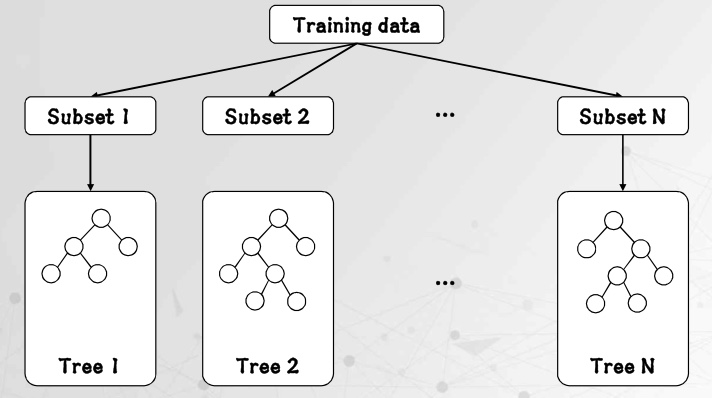
6. Generalization Error 관점에서의 Random Forest
각각의 DT는 과적합될 수 있지만, Random Forest는 그 수가 충분히 많을 때 큰 수의 법칙에 의해 전체 에러는 바운드 된다. 즉 전체 에러는 일정 수준 이하로 안정화된다고 이해하면 된다.
이 식에서 중요한 요소는 두 가지이다.
6-1. : 트리들 사이의 평균 상관관계
- 각 Decision Tree들이 얼마나 비슷한 예측을 하는지를 나타낸다.
- 값이 클수록 트리들이 같은 방향으로 판단하고, 같은 실수를 반복한다.
- 이 경우 여러 트리를 평균 내더라도 에러 감소 효과가 작다.
Random Forest에서는 Bagging(bootstrap sampling) 과 Random Subspace(무작위 feature 선택) 를 통해 트리들 사이의 상관관계를 낮춘다.
→ 를 작게 만드는 것이 핵심 전략이다.
6-2. : 개별 트리의 예측력 (strength)
- 하나의 Decision Tree가 정답을 맞힐 수 있는 힘을 의미한다.
- 값이 클수록 각 트리가 무작위 추측이 아니라 의미 있는 규칙을 학습하고 있다는 뜻이다.
Random Forest는 각 트리를 충분히 성장시켜 기본적인 예측 성능(s)을 확보한다.
핵심 정리
- ↓ (트리들이 서로 다를수록)
- ↑ (각 트리가 잘 맞힐수록, 즉 각 트리의 기본 성능이 좋을수록)
-> 전체 Generalization Error는 감소한다.
즉, Random Forest는 “잘 맞히는 트리를 많이 만들되, 서로 다르게 만들자” 라는 전략을 수식으로 뒷받침하는 모델이다.
7. 흐름 정리
Decision Tree의 과적합 문제
↓
하나의 트리는 불안정하다는 인식
↓
여러 개의 트리를 결합하는 Ensemble 아이디어
↓
Bagging으로 데이터 다양성 확보
↓
Random Subspace로 feature 다양성 확보
↓
트리 간 상관관계 감소
↓
Random Forest 탄생
마무리
이번 내용을 정리하면서 느낀 점은 Random Forest가 단순히 DT를 여러 개 모아놓은 모델은 아니라는 것이다.
Decision Tree가 가지는
- 과적합에 취약한 구조
- 데이터의 작은 변화에도 크게 흔들리는 불안정성
이러한 약점을 정확히 이해하고, 이를 다양성과 무작위성을 바탕으로 한 앙상블(Ensemble) 이라는 아이디어로 해결한 모델이 바로 Random Forest라는 생각이 들었다.
특히 DT의 한계를 먼저 이해하고 나니 Random Forest는 새로운 알고리즘이라기보다 자연스러운 확장이라는 생각이 들었다.
평소 공부할 때 개별 개념들을 따로 외우기보다는, 각 개념이 왜 등장했는지, 개념들 간의 연관성은 무엇인지 그 흐름을 이해하는 것을 중요하게 생각하는 편인데, Random Forest는 그런 관점에서 특히 인상적인 모델이었다.
