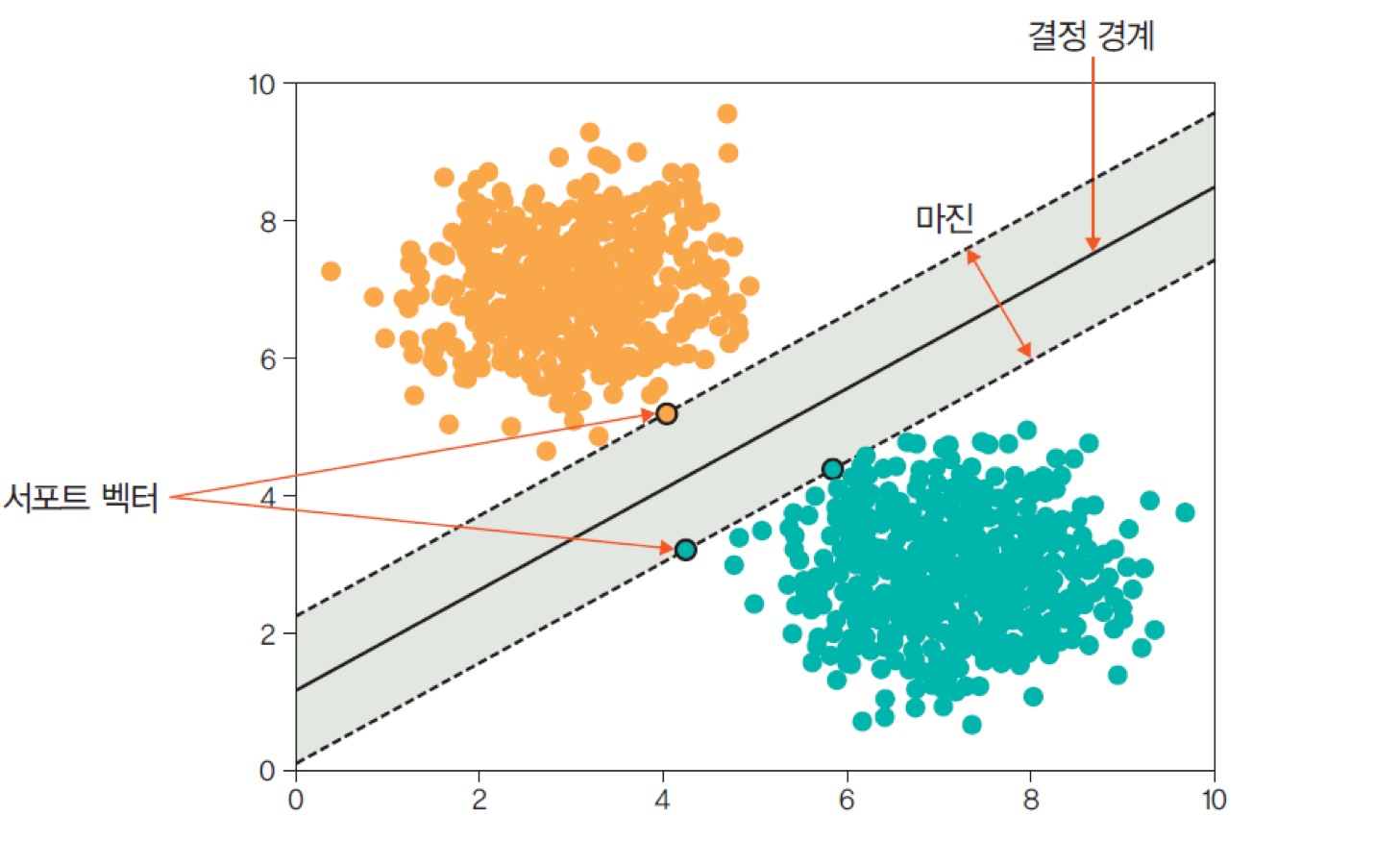
SVM(Support Vector Machine)은 지도학습에 해당하며, 두 클래스 사이의 거리(margin)를 최대화하는 결정 경계(Decision boundary)를 찾는 알고리즘이다.
SVM을 본격적으로 학습하기 전에 먼저 최적화(optimization)의 개념을 알아야 한다.
SVM은 겉보기에는 하나의 알고리즘처럼 보이지만, 실제로는 제약이 있는 볼록 최적화 문제를 세우고 이를 라그랑지안 → 듀얼 문제 → KKT 조건으로 정리해 해를 구하는 방식으로 동작한다.
따라서 SVM을 제대로 이해하기 위해서는 아래와 같은 최적화의 흐름이 먼저 잡혀 있어야 한다.
1. 최적화 문제의 표준형 (Standard Form)
현실의 많은 문제는 “목표 + 조건” 형태로 정리된다.
이를 통일된 기호로 표현하면 다음과 같은 최적화 문제의 표준형(Standard Form)이 된다.
각 항의 의미는 다음과 같다.
- : 결정변수 (정하고 싶은 값, 모델 파라미터 등)
- : 목적함수(cost function) — 최소화 대상
- : 부등식 제약(inequality constraints)
→ 넘으면 안 되는 조건 - : 등식 제약(equality constraints)
→ 정확히 만족해야 하는 조건
즉 를 최소화하고, 제약조건들을 만족하도록 해야하는 것이다.
핵심은, 대부분의 문제를 이와 같은 형태로 정리해두면 이후 라그랑지안, 듀얼 문제, KKT 조건으로 자연스럽게 이어질 수 있다는 점이다.
2. Convex(볼록) 최적화가 특별한 이유
표준형 문제 중에서도 아래 조건을 만족하면 볼록 최적화(convex optimization) 문제로 분류된다.
- 목적함수 가 볼록(convex)
- 부등식 제약 함수 도 볼록(convex)
- 등식 제약은 affine(아핀) 형태
(예: , 직선·평면)
볼록 최적화가 특별한 이유는 단 하나로 요약된다.
로컬 최적해(local optimum) = 글로벌 최적해(global optimum)
일반적인 최적화 문제는 로컬 최소점이 여러 개일 수 있어 찾은 해가 진짜 최선인지 보장하기 어렵다.
반면 볼록 문제에서는 그런 함정이 없기 때문에, 최적해를 찾으면 그 해가 곧 전역 최적해가 된다.
SVM이 안정적으로 동작하고 수식이 깔끔하게 닫히는 이유가 여기서 시작한다.
3. 볼록 집합과 볼록 함수
3-(1) 볼록 집합 (Convex Set)
집합 내부의 두 점 를 잡았을 때,
그 둘을 잇는 선분 위의 모든 점
이 다시 집합 내부에 있으면 해당 집합은 볼록 집합이다.
즉, 두 점을 이어도 선분이 집합 밖으로 튀어나가지 않는다.
3-(2) 볼록 함수 (Convex Function)
함수 가 볼록이면 다음 부등식이 성립한다.
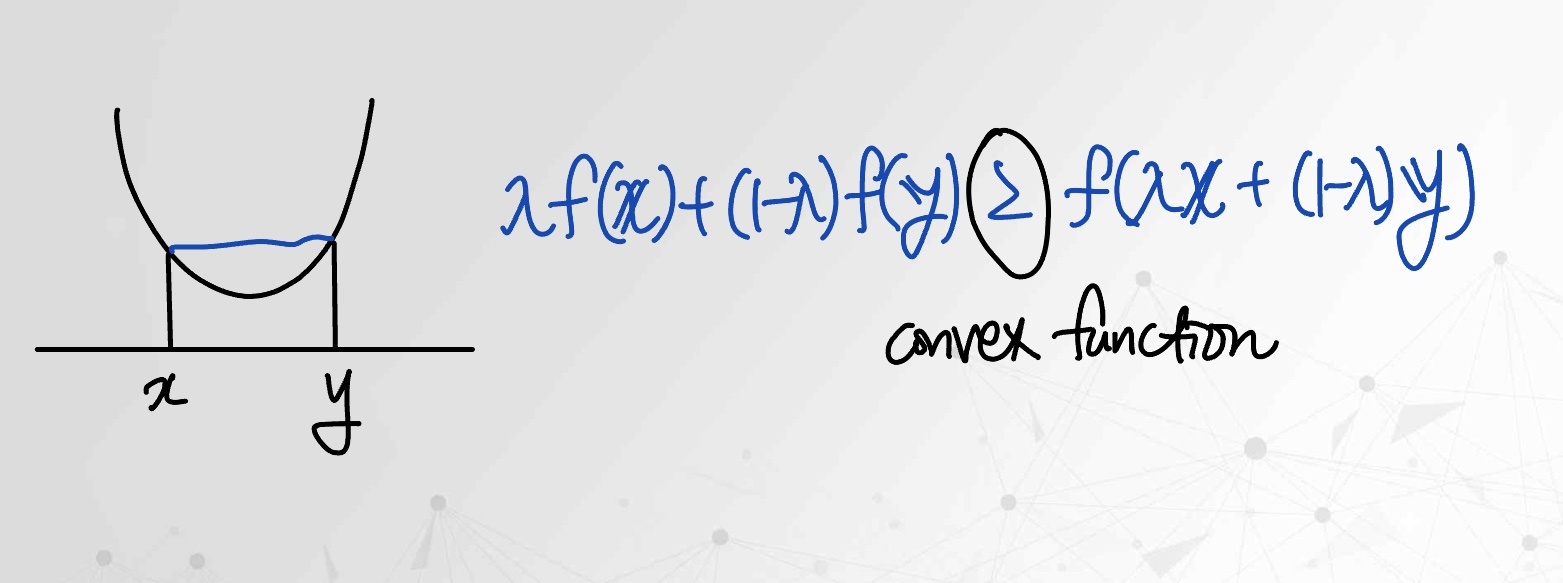
이는 두 점의 함수값을 직선으로 이은 값이 항상 실제 함수값보다 위에 놓인다는 의미다.
그래서 볼록 함수의 그래프는 U자 형태(그릇 모양)를 갖는다.
이 성질 덕분에 최적화 과정에서 “한 번 내려가기 시작하면 끝까지 내려가면 된다”는 안정성이 확보된다.
4. 라그랑지안 (Lagrangian): 목표와 제약을 하나의 식으로
제약이 있는 최적화 문제는 직접 다루기 어렵다.
이를 하나의 식으로 결합한 것이 라그랑지안(Lagrangian)이다.
- : 부등식 제약의 가중치(벌점 강도)
- : 등식 제약의 가중치(부호 제한 없음)
어떤 가 제약을 어기면 이 되어
항이 커지고, 라그랑지안 값이 불리해진다.
즉, 라그랑지안은 제약을 벌점항(penalty term)으로 바꿔 최적화를 다루기 쉬운 형태로 만드는 장치다.
5. 듀얼 함수 : 하한(lower bound) 만들기
라그랑지안을 정의한 뒤, 를 고정한 상태에서 에 대해 최소값을 취한 것이 듀얼 함수다.
여기서 중요한 성질이 하나 나온다.
이면
는 항상 프라이멀 최적값의 하한(lower bound)이다.
왜냐하면 모든 제약조건을 만족하는 모든 에 대해서
가 성립하고, 는 그중 최소값이기 때문이다.
6. 듀얼 문제 (Dual Problem)
하한을 만들었으면, 그 하한을 가장 크게 만드는 를 찾는다.
이 과정은 최적값을 직접 맞히는 방식이 아니라, 확실한 하한을 점점 끌어올려 최적값에 접근하는 전략이다.
7. 흐름 요약
-
대부분의 문제는 목표 + 제약 형태의 최적화 문제로 정리할 수 있다.
-
이 문제를 표준형(Standard Form)으로 표현하면, 목적함수와 제약조건을 명확히 분리할 수 있다.
-
목적함수와 제약이 모두 볼록(convex)하면, 로컬 최적해가 곧 전역 최적해가 되어 해의 안정성이 보장된다.
-
제약이 있는 문제는 라그랑지안(Lagrangian)을 통해 목표와 제약을 하나의 식으로 결합해 다룬다.
-
라그랑지안에서 결정변수 x를 먼저 최소화하면, 프라이멀 최적값의 하한(lower bound)을 주는 듀얼 함수가 정의된다. 이 하한을 최대화하는 문제가 듀얼 문제(Dual Problem)이며, 이를 통해 원래 문제의 최적값에 접근할 수 있다.
-
이러한 흐름 위에서 SVM은 분류 문제를 제약이 있는 볼록 최적화 문제로 정식화한 알고리즘으로 이해할 수 있다.
이제 SVM에 대해 본격적으로 알아보자.
SVM이란
SVM(Support Vector Machine)은 단순히 데이터를 분류하는 알고리즘이 아니라,
두 클래스 사이를 가장 안정적으로 나누는 결정 경계(decision boundary)를 찾는 방법이다.
이 안정성은 “얼마나 멀리 떨어뜨려 나누는가”, 즉 margin 개념에서 나온다.
1. Maximum Margin Classifier의 개념
데이터를 분리하는 직선(또는 초평면)은 여러 개 존재할 수 있다.
SVM은 그중에서 다음 기준을 만족하는 경계를 선택한다.
- 두 클래스 사이의 margin(경계로부터 가장 가까운 데이터까지의 거리)가 최대
- 노이즈나 작은 변동에 대해 강건(robust) 한 분류기
즉,
SVM = margin을 최대화하는 분류기
이때 margin을 결정하는 데이터는 전체가 아니라, 경계에 가장 가까이 위치한 일부 데이터뿐이다.
2. Support Vector란?
결정 경계에 가장 가까이 붙어 있는 데이터 포인트들을 Support Vector라고 부른다.
- 이 점들만이 경계의 위치와 방향을 결정
- 나머지 데이터는 경계에 직접적인 영향이 없음
그래서 이름이 Support Vector Machine이다.
“경계를 지지(support)하는 벡터들로 만들어진 분류기”라는 의미다.
3. Hard Margin vs Soft Margin
3-(1) Hard Margin SVM
- 모든 데이터가 margin 바깥에 위치하도록 강제
- 데이터가 선형적으로 완벽히 분리(linearly separable) 가능한 경우에만 사용 가능
- 이상치(outlier)에 매우 민감
수식적 조건:
3-(2) Soft Margin SVM
현실 데이터는 대부분 완벽히 분리되지 않는다. 이를 위해 slack variable을 도입한다.
- 일부 데이터의 margin 침범 허용
- 노이즈와 이상치에 더 강건
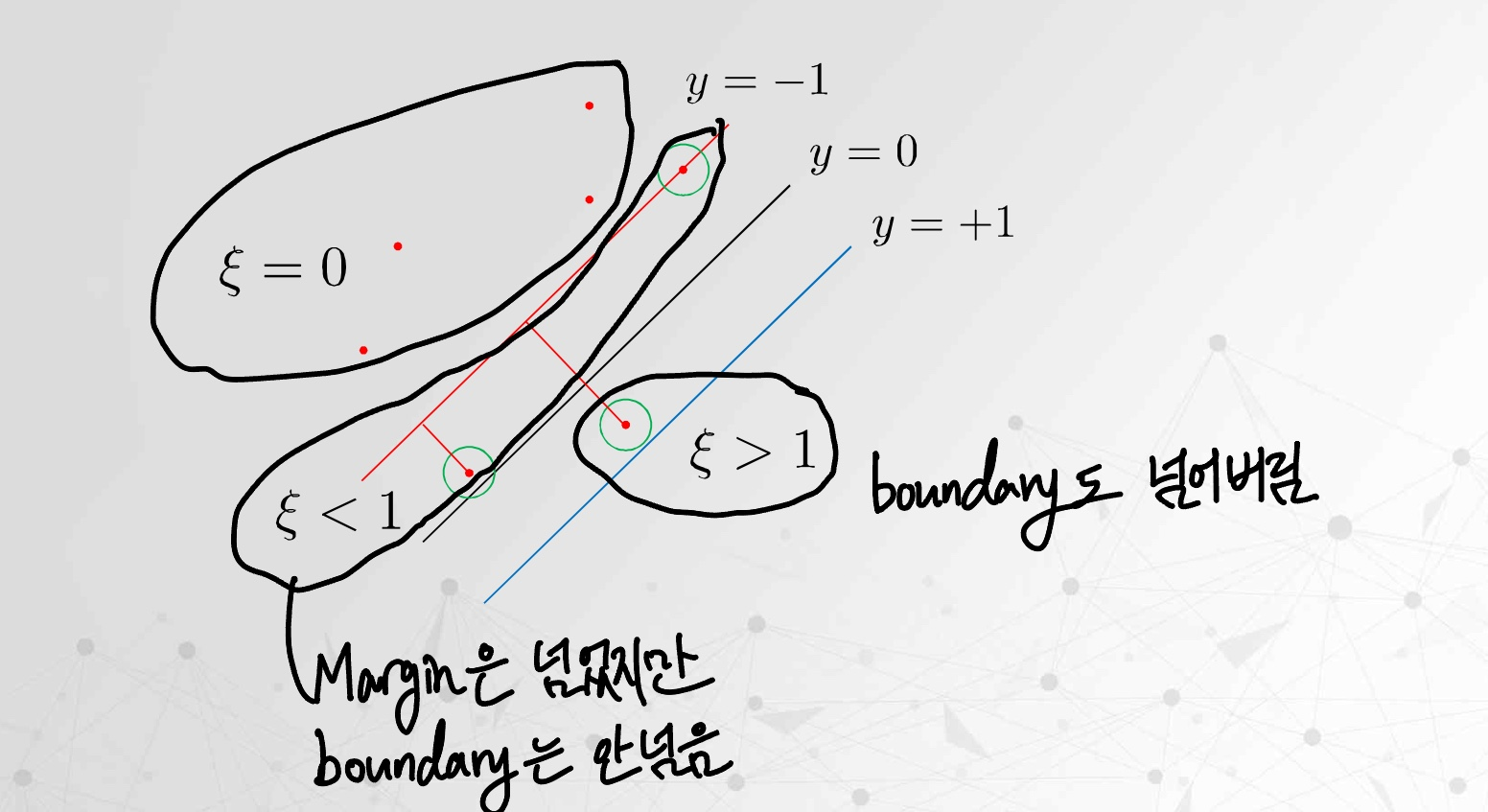
Slack Variable
각 데이터 포인트마다 하나의 slack variable 를 도입한다.
분류 조건은 다음과 같이 표현된다.
의미는 다음과 같다.
-
→ 올바르게 분류 + margin 바깥 -
→ 올바르게 분류되었지만 margin 안쪽 -
→ 잘못 분류(misclassification)
4. Soft SVM의 최적화 문제
Soft SVM은 두 가지 목표를 동시에 고려한다.
- margin을 크게 만들고 싶다
- margin을 침범한 데이터는 벌점을 주고 싶다
이를 하나의 목적함수로 표현하면 다음과 같다.
- : margin 최대화 항
- : margin 침범에 대한 페널티
- C: 두 항의 균형을 조절하는 하이퍼파라미터
5. 하이퍼파라미터 C의 의미
-
C가 클수록
- slack 허용을 거의 하지 않음
- margin이 좁아짐
- training 데이터에 더 민감 (overfitting 위험)
-
C가 작을수록
- slack을 더 허용
- margin이 넓어짐
- 일반화 성능 증가 (underfitting 가능)
즉, C는
margin의 크기 vs 분류 오류 허용 정도의 trade-off를 조절하는 파라미터
다.
6. 듀얼 문제와 Support Vector의 등장
Soft SVM의 라그랑지안을 정리해 듀얼 문제로 변환하면, 최종적으로 결정 경계의 가중치 벡터는 다음과 같은 형태로 표현된다.
이 식이 의미하는 핵심은 다음과 같다.
- 모든 데이터가 아니라, 일부 데이터만이 결정 경계 를 구성한다
- 그 기준은 의 값이다
구체적으로,
- 인 데이터는 에 아무런 영향을 주지 않는다
- 인 데이터만이 의 합에 포함된다
이때 인 데이터들은 결정 경계와 가장 가까이 위치하거나, margin을 침범한 데이터들이다.
즉, 결정 경계를 실제로 결정하는 데이터는 전체 데이터가 아니라 경계 근처의 소수 데이터이며, 이들을 Support Vector라고 부른다.
이 특성 때문에 SVM은 불필요한 데이터의 영향을 자연스럽게 제거하고, 경계에 중요한 정보만을 이용해 분류기를 구성한다.
7. SVM 전체 흐름 요약
- 데이터를 나누는 수많은 경계 중
- margin을 최대화하는 경계를 선택
- 경계를 결정하는 것은 소수의 Support Vector
- Hard SVM → Soft SVM으로 현실 데이터 대응
한 줄 정리
SVM은 “경계에 가장 가까운 데이터”를 기준으로 두 클래스를 가장 안정적으로 나누는 분류기다.**
이제 iris 데이터셋을 활용한 SVM 분류 예제 코드를 살펴보자.
앞에서 SVM의 개념을 정리했다면, 이번 파트에서는 실제 코드가 그 개념을 어떻게 구현하는지 확인하는 단계다.
라이브러리 불러오기
SVM 모델 학습과 데이터 처리를 위해 필요한 라이브러리들을 불러온다.
이번 예제에서는 sklearn에서 제공하는 SVM 분류기를 사용한다.
# library
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn import metrics
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
import osIris 데이터셋 로드 및 학습/테스트 분리
sklearn에서 제공하는 iris 데이터셋을 불러오고,
train_test_split()을 사용해 학습용 데이터와 테스트용 데이터를 분리한다.
# sklearn에서 제공하는 iris 데이터 호출
iris = datasets.load_iris()
# train / test 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(
iris.data,
iris.target,
test_size=0.2,
random_state=42
)iris.data: 꽃의 길이/너비 4개 특성(feature)iris.target: 클래스 레이블
(0=setosa,1=versicolor,2=virginica)random_state=42: 실행할 때마다 동일한 분할 결과를 얻기 위함
SVM 모델 생성
선형 커널(linear kernel)을 사용하는 SVM 모델을 생성한다.
model = svm.SVC(kernel='linear', C=1.0, gamma=0.5)각 하이퍼파라미터의 의미는 다음과 같다.
kernel='linear'
→ 선형 결정 경계를 사용해 데이터를 분류C=1.0
→ 오분류에 대한 패널티 조절
→ 값이 클수록 마진이 작아지고 과적합 위험 증가
→ 값이 작을수록 마진이 커지고 일반화 성능 향상gamma=0.5
→ RBF 커널에서 사용하는 파라미터
→ 선형 커널에서는 직접적인 영향 없음
모델 학습
학습 데이터를 사용하여 SVM 분류기의 결정 경계를 학습한다.
model.fit(X_train, y_train)SVM은 모든 데이터를 사용하는 것이 아니라, 결정 경계에 중요한 일부 데이터만을 이용해 경계를 학습한다.
테스트 데이터 예측 및 정확도 평가
학습된 모델을 사용해 테스트 데이터에 대한 예측을 수행하고,
정확도를 계산한다.
predictions = model.predict(X_test)
score = metrics.accuracy_score(y_test, predictions)
print("정확도: {0:0.3f}".format(score))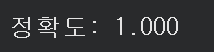
또한 실제 정답과 예측 결과를 직접 출력해 비교할 수 있다.
print(y_test)
print(predictions)
Iris 데이터 시각화 및 SVM 분류 (확장)
앞선 예제에서는 iris 데이터 전체를 바로 SVM에 적용했다.
이번 단계에서는 데이터를 DataFrame 형태로 다루면서,
각 클래스의 분포를 시각적으로 확인한 뒤 SVM 분류를 수행한다.
Iris 데이터의 Feature 확인
iris 데이터셋은 총 4개의 feature로 구성되어 있다.
#iris = datasets.load_iris()
iris.feature_names출력 결과는 다음과 같다.
- sepal length (cm)
- sepal width (cm)
- petal length (cm)
- petal width (cm)
Pandas DataFrame 생성
iris 데이터를 Pandas DataFrame으로 변환해 다루기 쉽게 만든다.
df = pd.DataFrame(iris.data, columns=iris.feature_names)
# 데이터 프레임을 만들어줌각 행은 하나의 꽃 샘플을 의미하며,
각 열은 꽃의 길이/너비에 해당하는 feature다.
Target 컬럼 추가
각 데이터가 어떤 품종인지 나타내는 target 컬럼을 추가한다.
df['target'] = iris.target
# 'target' feature를 만들어줌iris 데이터에서 target 값은 다음을 의미한다.
iris.target_names- 0 : setosa
- 1 : versicolor
- 2 : virginica
클래스 이름 컬럼 추가
숫자 레이블 대신, 실제 꽃 이름을 컬럼으로 추가한다.
df['flower_name'] = df.target.apply(lambda x: iris.target_names[x])이제 DataFrame에는 다음 정보가 포함된다.
- 4개의 feature
- 정수 레이블(target)
- 문자열 레이블(flower_name)
클래스별 데이터 분리
각 품종별로 데이터를 분리한다.
df0 = df[df.target==0]
df1 = df[df.target==1]
df2 = df[df.target==2]이렇게 분리하면 시각화나 분석 시 클래스별 비교가 쉬워진다.
Sepal Feature 시각화
sepal length와 sepal width를 기준으로 두 클래스의 분포를 확인한다.
plt.scatter(df0['sepal length (cm)'], df0['sepal width (cm)'], color='green', marker='+')
plt.scatter(df1['sepal length (cm)'], df1['sepal width (cm)'], color='blue', marker='+')
plt.xlabel('sepal length (cm)')
plt.ylabel('sepal width (cm)')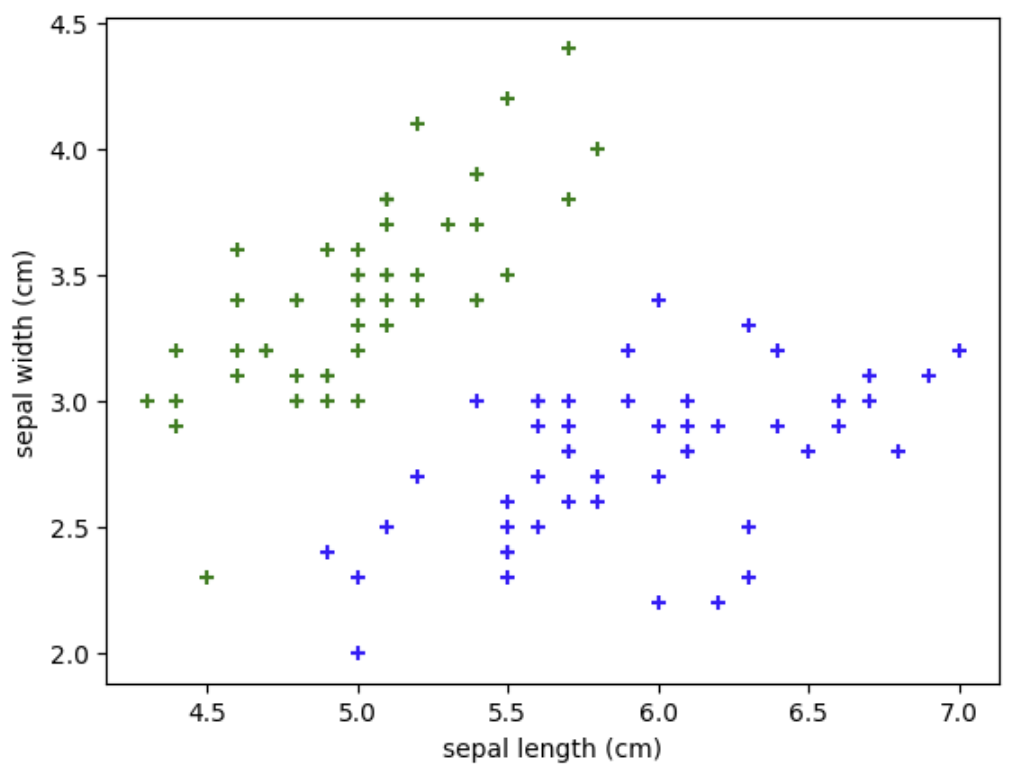
이 시각화를 통해
setosa와 versicolor가 어느 정도 선형적으로 구분되는지 직관적으로 확인할 수 있다.
Petal Feature 시각화
이번에는 petal length와 petal width를 기준으로 시각화한다.
plt.scatter(df0['petal length (cm)'], df0['petal width (cm)'], color='green', marker='+')
plt.scatter(df1['petal length (cm)'], df1['petal width (cm)'], color='blue', marker='+')
plt.xlabel('petal length (cm)')
plt.ylabel('petal width (cm)')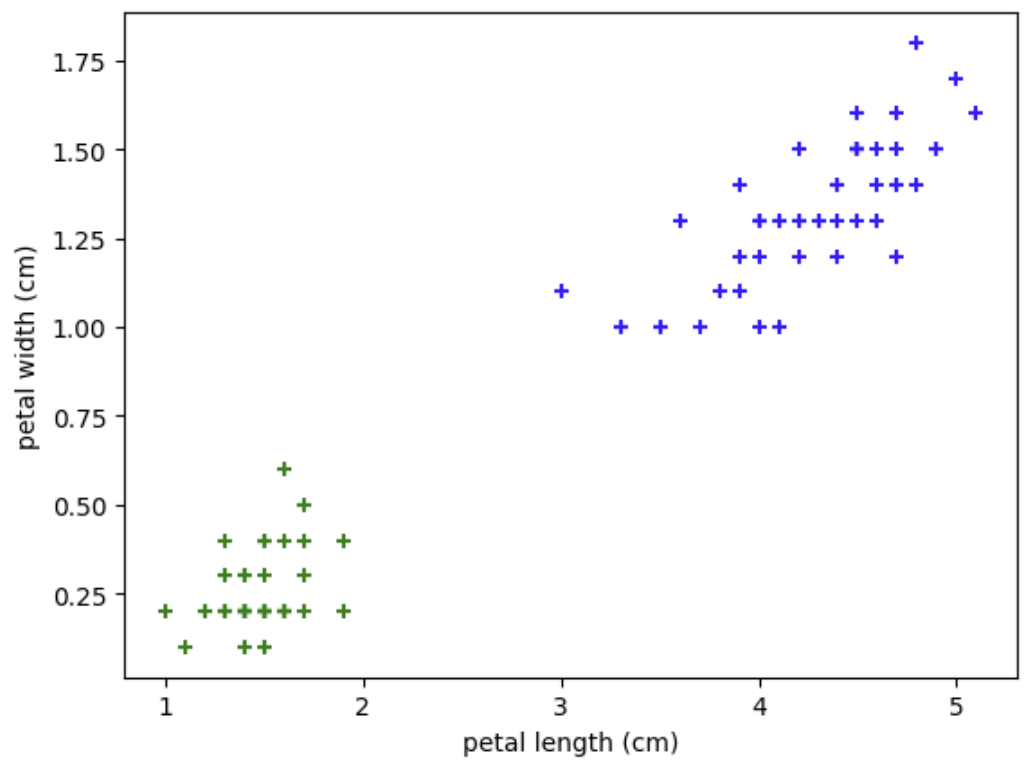
petal feature는 sepal feature보다 클래스 분리가 더 명확하게 나타나는 경향이 있다.
이 때문에 iris 데이터셋에서는 petal feature가 분류에 특히 중요하다.
Feature / Label 분리
모델 학습을 위해 feature(X)와 label(y)를 분리한다.
X = df.drop(['target', 'flower_name'], axis='columns')
y = df.target # 정수 레이블 0/1/2- X : 4개의 수치형 feature
- y : 꽃의 품종을 나타내는 클래스 레이블
학습 데이터 / 테스트 데이터 분리
전체 데이터 중 일부를 테스트 데이터로 분리한다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)SVM 모델 생성 및 학습
SVM 분류 모델을 생성하고 학습을 진행한다.
model = SVC(C=10)- C 값이 클수록:
- 오분류를 거의 허용하지 않음
- 마진이 작아짐
- 과적합 위험 증가
- C 값이 작을수록:
- 오분류를 어느 정도 허용
- 마진이 커짐
- 일반화 성능 향상
model.fit(X_train, y_train)
# 훈련 데이터로 결정 경계 학습모델 정확도 평가
학습된 모델을 테스트 데이터에 적용해 정확도를 계산한다.
accuracy = model.score(X_test, y_test)
print(f'모델 정확도: {accuracy:.2f}')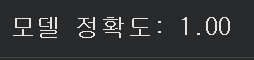
정리
- Iris 데이터셋은 비교적 선형 분리가 잘 되는 데이터셋이다.
- SVM은 결정 경계에 중요한 데이터(Support Vector)만을 활용해 효율적으로 분류 경계를 학습한다.
- iris 데이터는 SVM의 특성을 확인하기에 매우 좋은 예제다.
- feature 시각화를 통해 데이터 분포와 분리 가능성을 직관적으로 파악할 수 있다.
- C 값 조절을 통해 하드 마진 / 소프트 마진의 차이를 실험해볼 수 있다.
- SVM은 데이터의 분포 구조를 기반으로 결정 경계를 학습하는 강력한 분류기다.
