
본 포스트팅은 인하대학교 컴퓨터공학과 오픈소스sw개론 수업자료에 기반하고 있습니다. 개인적인 학습을 위한 정리여서 설명이 다소 미흡할 수 있으니, 간단히 참고하실 분들만 포스팅을 참고해주세요 😎
TenserFllow 란?
- 딥러닝(DL) 오픈소스
Tensors
-
텐서플로우에 들어가있는 배열 형태의 가장 기본적인 단위. 이때 tensor 안의 각 배열의 구성성분으로 여러가지 타입(int, float, ...)의 데이터들이 저장될 수 없다. 한 가지 타입으로만 구성됨
-
tensor 객체는 tf . Tensor 와 같이 생성가능
-
한번 생성한 tensor 의 값은 변경불가능.
Tensor 생성
-
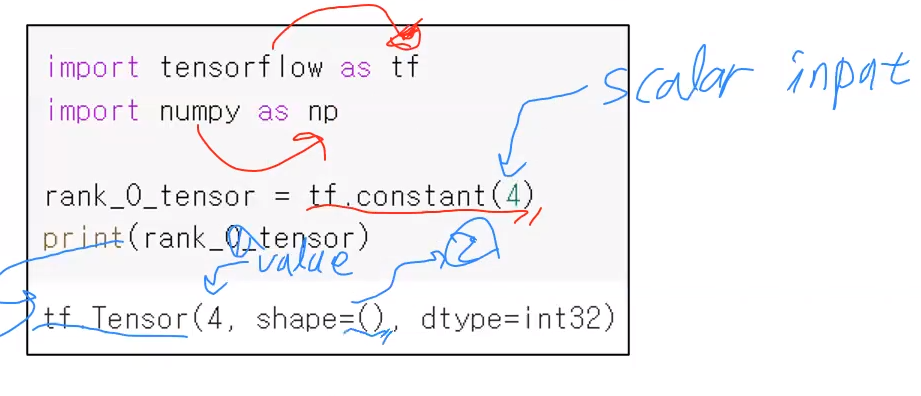
tf.constant(인풋 데이터) : tesntor 객체 생성하는 함수
- 생성된 객체는 "tf.Tensor(상세내용)" 과 같은 형태를 지닌다.
=> tensor 객체의 클래스는 "tf.Tensor()" 이다.
- 생성된 객체는 "tf.Tensor(상세내용)" 과 같은 형태를 지닌다.
-
tensor 객체 : tf.Tensor(value, shape = (), dtype = )
- tensor 객체는 아래의 3가지 속성을 보유하고 있다.
- value : 어떤 값을 가지고 있는가
- shape : 말그대로 tessor 배열의 모양새. 즉, 배열의 각 축에 대한 크기 정보를 표현한다. ex) 2x3x4 배열인 경우 shape = (2,3,4,) 와 같이 형성됨. 아래 예제의 경우 스칼라이므로 shape = ( ) 와 같은 형태로 크기 정보가 특별히 없다.
- dtype : 해당 tensor 객체의 배열이 보유한 데이터 타입
- rank 란 몇 차원에 해당하는가를 의미.
- ex) 해당 tensor 의 배열이 2차원인경우 rank 는 2이다.
1차원 tensor

-
shape=(3, ) : 현재 tensor 의 배열을 보면 축이 1개밖에 없다. shape 에 출력되는것은 각 축에 대한 크기 정보인데 축이 하나밖에 없어서 3을 출력하고 끝난다.
- 우리는 shape을 보고 해당 tesntor 가 1차원인데 크기가 3임을 알 수 있다.
2차원 tensor
- constant() 로 tensor 를 생성할때, dtype을 지정 가능하다.
- dtype 을 별도로 지정 안해주면 default 값은 인자로 넘겨받은 배열 데이터들의 타입에 의해 결정된다. (즉, 아래 예제의 경우는 별도롷 지정 안해줬다면 int32 이다.)

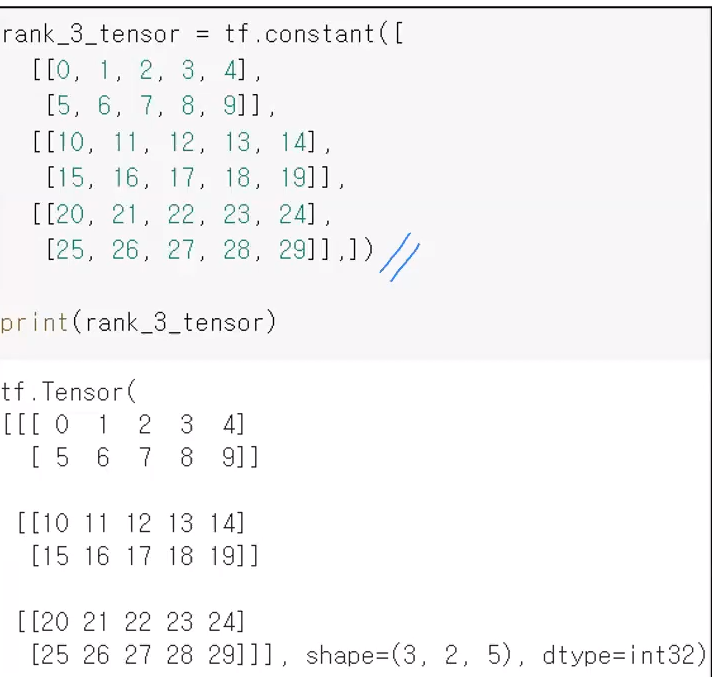
3차원 tensor
아래처럼 3x2x5 짜리 3차원 tensor 배열을 생성할 수 있다.
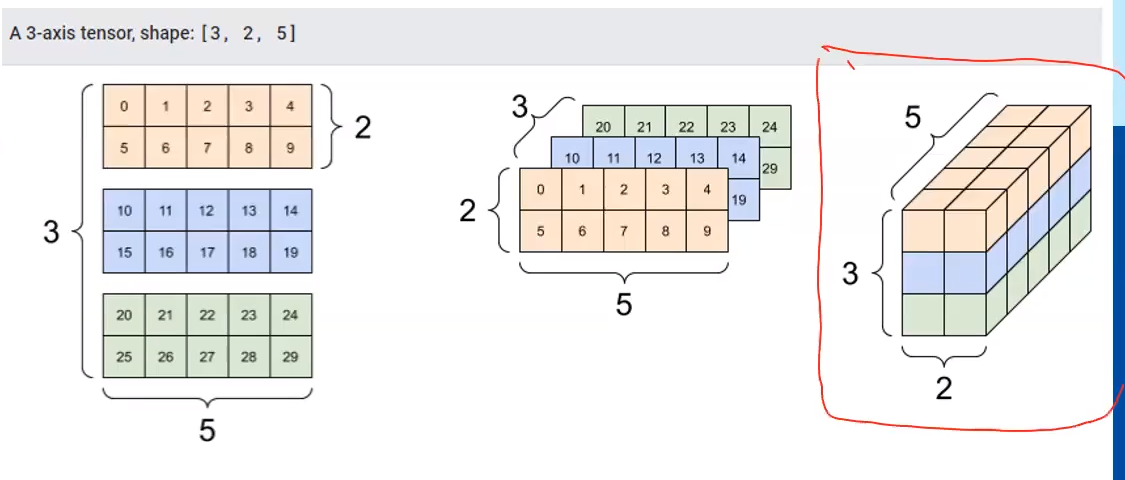
그림으로 표현해보자면 아래와 같다.
tf.Tensor 와 Numpy 의 배열간의 변환
아래와 같은 형태로, tensor 객체를 Numpy 배열로 변환 가능하다.
- np.array( tensor객체 )
- tensor객체.numpy()

Tensor의 사칙연산 함수
numpy 에서 했던 사칙연산 함수처럼 tensor 에서도 사용 가능하다.
-
tf . add( tensor1, tensor2 ) 또는 tensor1 + tensor2
-
tf . multiply( tensor1, tensor2 ) 또는 tensor1 * tensor2
- element-wise 방식.
- 각 원소끼리만 곱합. 예를들어 1행 2열의 원소끼리 곱한 결과를 1행 2열에 표현
-
tf . matmul( tensor1, tensor2 ) 또는 tensor1 @ tensor2
- 행렬의 곱셈 (선형대수 수업떄 했던 방식)
- 선형대수때 배웠던 것처럼 A X B 와 B X A 행렬의 곱셈 결과는 다르다!!
- tf . divide( tensor1, tensor2 ) 또는 tensor1 / tensor2


zeros
- 모든 element 가 0인 tensor 배열 생성
- zeors 는 tensor 를 구성하는 데이터를 입력받는 것이 아니라, shape 을 입력받는다.

예를들어 위와같이 생성한경우 아래 그림처럼 3x2x4x5 짜리 4차원짜리 tensor 배열이 생성되는 것이다.
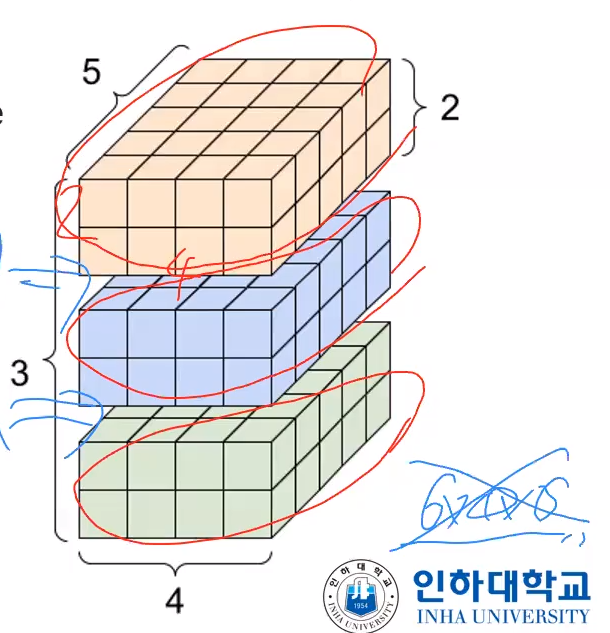
axis
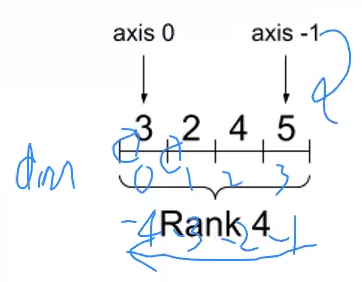
-
차원을 말할떄 axis 라는 축의 단위가 등장한다.
위의 경우 첫번쨰 축은 axis = 0, 2번쨰 축은 axis = 1, 그 다음으로 2, 3이 되는 것이다. -
이렇게 n번쨰 axis 를 말할때 마이너스 인덱싱도 가능하다. 즉 axis 3은 axis -1이 되기도 한다.
Tensor 의 다양한 속성을 조회하는 함수들
앞서 살펴본 value, shape, dtype 외에도 다양한 속성들이 존재한다. 이들을 조회하는 함수들이 있다
- ndim : number of dimensions => 몇차원인지
- shape : shape 은 리스트 형태이므로 인덱싱이 가능하다. ex) rank_4_tensor.shape[0]
- size : 총 element 의 개수

tensor 의 인덱싱하기
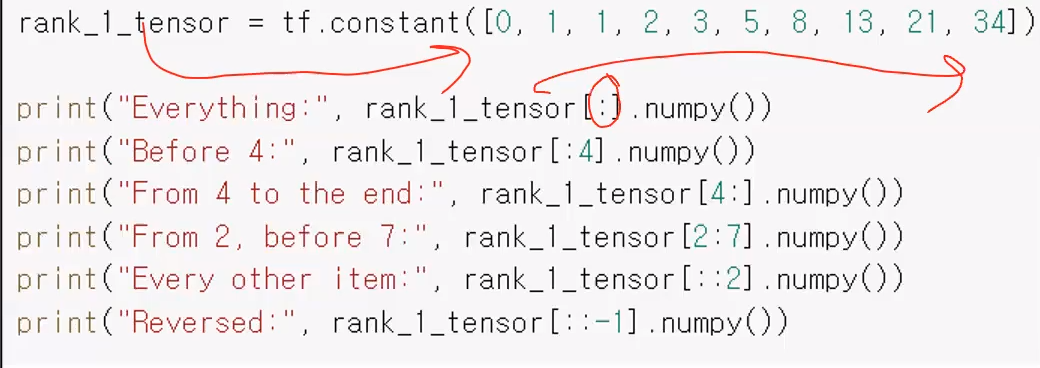
위와같은 1차원 tensor 에 대해 인덱싱을 해보자. 각 print 문에서 인덱싱한 결과를 numpy() 함수를 이용해 numpy 로 변환해서 출력하고 있다.
출력 결과는 아래와 같다.
다차원 tensor 인덱싱하기
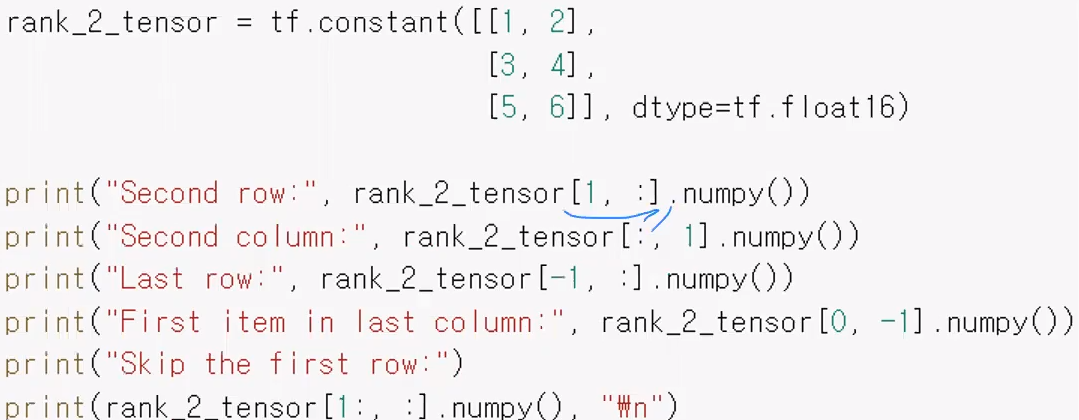
- rank_2_tensor[1, :].numpy() => 1행의 모든 데이터들을 조회
- rank_2_tensor[:, 1].numpy() => 1열의 모든 데이터들을 조회
- rank_2_tensor[-1, :].numpy() => 2행의 모든 데이터들을 조회
- rank_2_tensor[0, -1].numpy() => 0행 2열의 데이터를 조회
출력결과

reshape
- shape 모양을 바꾼다.
- 형태 : tf . reshape( tensor객체, 바꾸고자 하는 shape )
- tf.reshape(rank_2_tensor, [1,6]) : rank_2_tensor 객체의 모양을 1x6 으로 바꿈

reshape 할때 유의사항
- reshape 했을떄의 element 개수는 reshape 이전의 원본 배열과 element 개수가 동일해야 변형이 가능하다.
- 예를들어 아래 예시처럼 원소가 6개인 tensor 배열에 대해 원소가 8개인 [1,8] 로 변형하려는 경우였다면 에러가 발생한다.
-
shape의 크기를 명시할때 -1은 딱 한번만 사용 가능하다.
-
-1을 딱 한번만 사용하면 자동으로 알아서 적절한 shape 가 할당되도록 숫자가 할당된다.
-
tf.reshape(rank_2_tensor, [-1, 3])
=> -1이 등장했을때 TensorFlow는 자동으로 shape=(2,3) 을 보고 배열의 총 사이즈가 6임을 인지하고, 동일한 사이즈로 reshape 해주기 위해 TensorFlow가 알아서 자동으로 2로 변환해준다. -
tf.reshape(rank_2_tensor, [-1, -1, 2]) => -1 이 2개 이상할당되면 -1에 어떤 값이 할당되어야할지 자동으로 절대 계산해줄 수가 없다. 따라서 에러발생
-

cast 함수
- tf.cast() 함수를 통해 int32, float64 와 같은 타입을 변경 가능하다.

tf.Variables
tf.Tensor 와 유사하지만, tf.Tensor 와 달리 값들이 수정될 수 있다.
- tf.Variable() 생성자 안에다 tf.Tensor 객체를 넣어주면 해당 Tensor 객체를 Variable 객체로 변환해준다.

assign
-
tf.Variable() 안의 값들은 assign 함수를 통해 수정 가능하다.
-
형태 : variable객체.assign(새롭게 할당할 배열)
-
주의사항 : 새롭게 할당할 배열의 shape(형태) 와 기존 배열의 shape 가 똑같아야 한다.
- ex) 2x3 배열인데 5x3 으로 변경하는건 말이 안되니, 이렇게 변경하려고 하면 에러발생

만일 아래처럼 3x2 짜리 배열인데 2x2 의 shape 를 지닌 배열로 변경하려 했다면 에러가 발생할것이다.

gradient descent : 미분 게산
with tf.GradientTape() as tape : 미분을 진행할 함수를 등록하는 구문
- 미분을 수행할 함수를 이 구문안에 할당해줘야한다.
- 즉 여기서 미분하고자 하는 원본 함수 y를 정의해줘야한다.
- 이 구문에 정의된 함수 y는 x 의 어떤 연산들을 통해서 나오게 되는 결과인지 TessorFlow 가 관리하게 된다. 그리고 그 연산구조를 기반으로 미분을 할 수 있게 해준다.
=> 쉽게말해, 미분할 함수를 준비를 해주는 것이다.
우선 아래처럼 미분할 함수를 정의했다고 하자.
이떄 파라미터 변수 x 는 Tensorflow 의 tf.Variable 이다.

type.gradient(y, x) : 앞서 등록한 미분할 함수에 대한 도함수(y프라임) 을 리턴
- 즉 dy/dx 를 리턴해준다.
- 이떄 인자를 할당하는 순서가 있다. 첫번쨰 인자는 y이고, 두번쨰 인자는 x 이다.
g_x 에는 "x^2 + 2*x - 5" 를 미분한 결과인 "2*x + 2" 에 대해 x값인 1을 할당한 결과가 저장된다.
=> 앞서 정의한 tf.Variable에 저장된 값인 1.0의 값을 2*x + 2 식에 할당한 결과가 g_x에 저장되는 것이다.
Gradient descent 구하기 원리
- y = ax+ b 형태가 있을때 최적화 답을 구하고 싶다면 a와 b 값을 계속 달리하며 여러 step 을 반복함
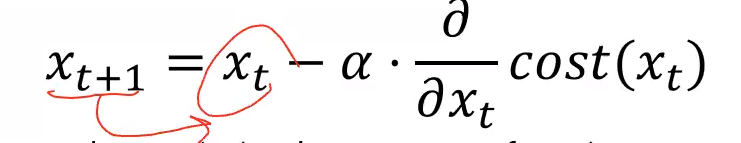
- Xt : current value
- Xt+1 : future value
Training ML/DL (gradient descendent)
- gradient descendent (경사 하강법) 을 사용하는 ML/DL 에 대한 Training 과정은 아래와 같다.
1) training data 를 수집하기 (Dataset 준비과정)
2) Model 을 정의하기 (아직 모델이 똑똑하지 않다. 그래서 학습을 시켜야함)
- Scikit learn 에서는 fit() 을 통해 학습시켰었다.
3) loss function(손실 함수) 을 정의하기
-
어떤 함수에 대해서 우리가 경사하강법( gradient descendent ) 을 사용해서 파라미터를 추척해 갈 것인지 loss function 을 정의해야한다.
-
loss function 이 바로 학습목표(training objecttive) 에 해당한다. (지난번에 지도.비지도 학습때 말했던 것)
=> 왜냐하면 이 값을 줄이려고 파라미터가 바뀌기 떄문이다.
=> loss function 을 다르게하면 곧 학습목표가 달라지는 것이므로, 학습방향이 달라져서 결과가 다르게 나온다. -
objective function, cost function 등으로도 불린다.
(4~5 과정은 gradient descendent 에 해당한다.)
4) training data 를 통해 loss value(현재의 함수값) 를 계산한다.
5) 미분값(gradients) 를 구하고 변수를 적용시킨다.
6) 수렴할 때 까지 4번, 5번 과정을 계속 반복한다.
- 한번 학습한다고 바로 학습이 완료되지 않는다. 수렴할때까지 반복한다.
- 수렴한다는게 의미와 기준이 애매한데, 이 수렴의 정도라는 것은 각 테스크와 상황에 따라 기준이 다른 것이다.
=> 보통은 미리 정의한 횟수만큼 반복한다. (이 정도했으면 수렴하겠지? 하고 미리 반복횟수를 정하고 반복시킨다.)
7) 학습이 끝났다면, model의 성능을 테스트한다.
선형 모델(Linear Model) 의 형태
선형 모델(linear model) : f(x) = W*x + b
=> W : weight(가중치), b:bias(편향)
선형회귀(Linear regression) 에서 텐서플로우의 API
- LOW-level API 들은 Core API 라고 불린다.
- High-level API 들은 Keras 라고 불린다.
low-level API
low-level API 를 활용해서 학습을 시키고 모델을 만들어내는 과정을 알아보자.
우선 아래와 같은 코드를 통해 Dataset 을 구성해보자.
1. Dataset presentation : 필요한 데이터 구성
전체코드

데이터를 구성하는 과정을 살펴보자.

-
TRUE_W, TRUE_B : 실제로 우리가 데이터를 생성할 떄 참조할 weight(가중치) 과 bias(편향) 값
=> 즉 y = 3x+2 와 같은 선형방정식을 가정하고 데이터를 준비해 놓는 것이다. -
NUM_EXAMPLES = 201 : dataset 의 크기는 201로 가정. 즉, 201개의 데이터를 생성할 것이다.

- x = tf.linespace(-2, 2, NUM_EXAMPLES) : -2~2 사이에서 총 201개의 데이터를 생성하고,
- x = tf.cast(x, tf.float32) : 생성한 데이터들을 float 타입으로 바꿔준다.
=> x 는 -2 에서 2 사이의 사이의 데이터 값을 201 가지는 tensor 이다.

- x로 부터 y값을 계산할 함수 f(x) 를 3x+2 형태로 정의

- noise = tf.random.normal(shape=[NNUM_EXAMPLES]) : 각 201개의 데이터들을 기존의 직선(3x+2)에서 멀어질 수 있도록 noise 를 발생시키는 것
noise 란 직선에서 벗어난 정도를 의미한다.
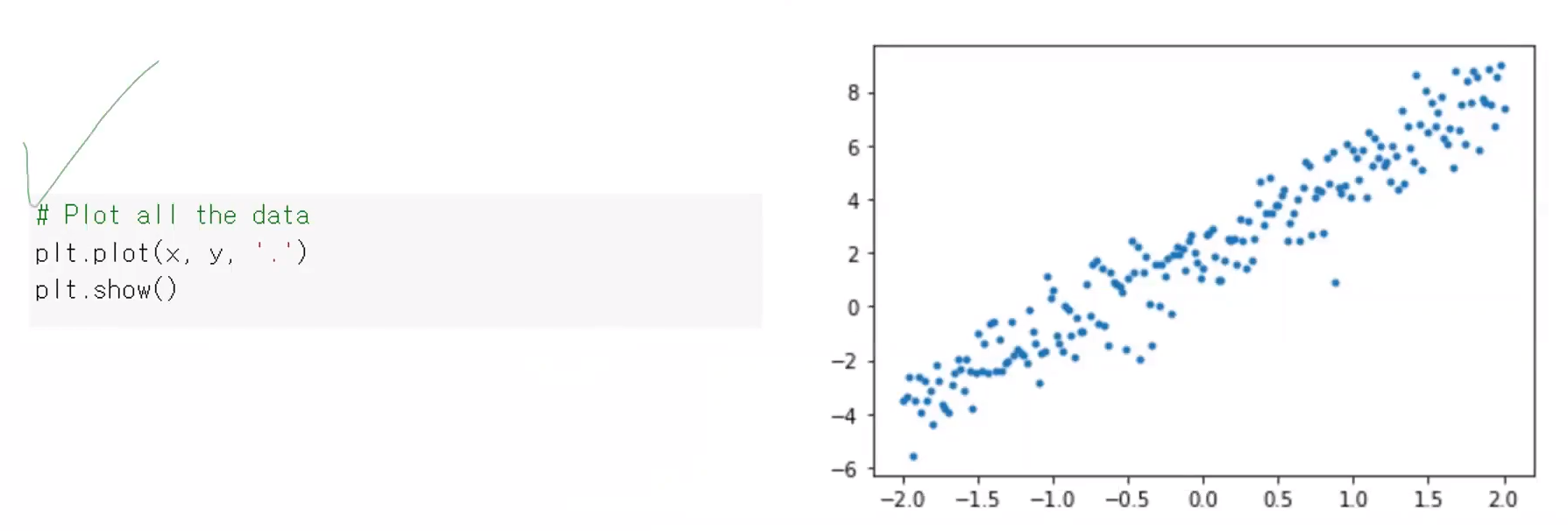
201개의 데이터들이 3x+2 형태로 나타나게 되면 학습(Training) 과정이 정말 쉽다, 그러나 실제로 관측되는 값들은 점 형태로 표현해봤을 떄, 점들이 많이 흩어져서 분포되어 있는 모습이 나온다. 예를들면 아래와 같은 형태이다.

=> 해당 직선를 따라서 가는 각 점들은 noise (직선에서 벗어나는 정도. 수치) 가 있다. noise 를 발생시켜보려고 위와 같은 함수를 사용한 것이다.

- y = f(x) + noise : 우리가 원하는 주어진 x값에 대한 관측값을 계산할 수 있다.
그리고 matpolib 모듈의 plt.plot 으로 201개의 데이터들을 출력을 해보면 아래와 같다.
2. Model 정의하기
앞서 Dataset 을 구성했다면, 이제는 Model 을 정의해야한다.
클래스 형태로써 Model 을 정의하자.
- tf.Module : 텐서플로우에서 가장 기초가 되는 뉴런 네트워크 Model 클래스
=> 이 클래스를 상속받도록 한다.
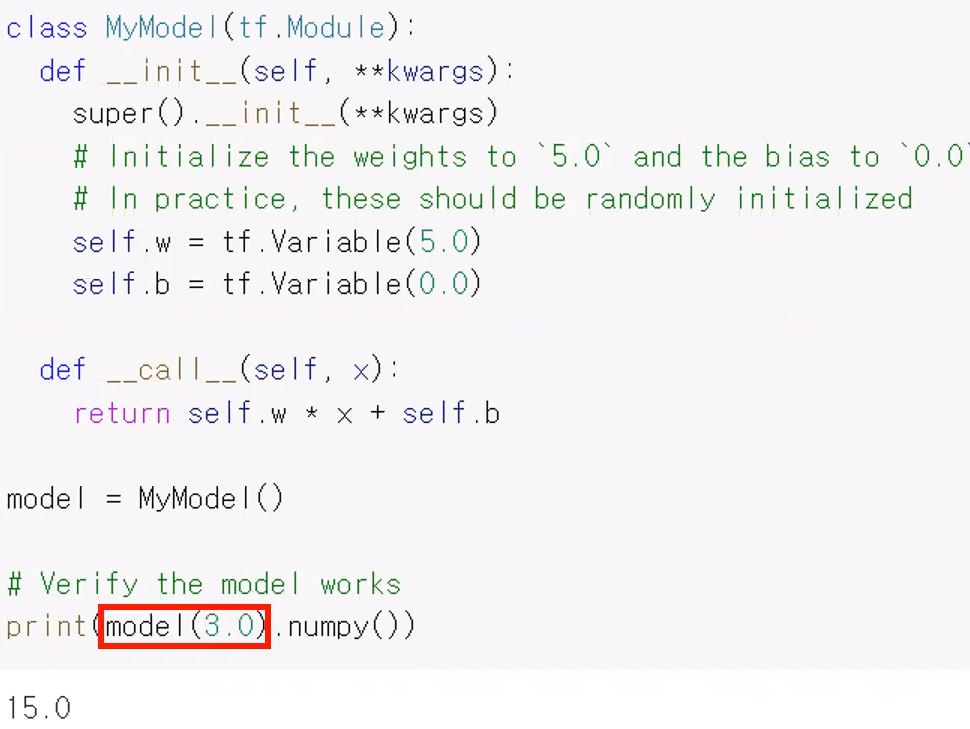
코드 해설

생성자(init) 를 보면 super() 를 통해 부모 클래스(tf.Module 의 생성자를 호출한다.
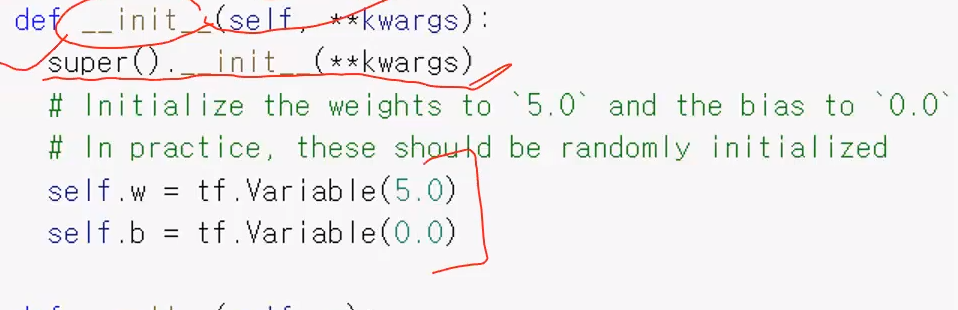
- self.w = tf.Variable(5.0)
- self.b = tf.Variable(0.0)
=> 파라미터를 선언한 부분. weight(가중치) 와 bias(편향) 값을 가지고있다. weight 은 5.0으로 주고, bias 는 0.0 으로 주었다.

- _ _call__ 메소드 : 해당 클래스의 오브젝트 이름이 호출되었을 때, call 메소드를 호출한다.
(즉 tf.Module 을 상속받은 클래스의 객체가 호출될 떄 call 함수가 호출된다 )
=> 아래처럼 tf.Module 을 상속받은 클래스 Mymodel의 객체인 model 에 대해, model(3.0) 과 같이 호출했는데, 이는 곧 "model._ _call__(3.0)" 과 같이 호출한 것과 동일하다.

아무튼 print(model(3.0).numpy()) 의 출력결과는 5x3 + 0 = 15 가 된다.
loss function 정의하기
- model 을 정의했다면 이어서 해당 model 에 학습목표를 주입하기 위해 loss function 을 정의해야한다.
MSE
-
loss function 의 종류는 정말 다양한데, 이번 강의에서는 MSE(mean squared error) 라는 loss function 을 사용한다.
-
예를들어 output 에서 label 을 뺀 값을 제곱하고 평균을 계산하는 함수이다. 즉 (output - label)^2 에 대해 평균을 구하는 것이다.
=> 지금 이 경우는 201개의 데이터에 대해 모두 합한후 그 결과를 201로 나누는것이다.
텐서플로우로 MSE 함숨를 구현해보면 아래와 같다. output(target_y) 에서 label(=predicted_y) 를 빼주고, sqaure() 로 제곱을 해준다음 reduce_mean() 으로 평균을 구해준다.

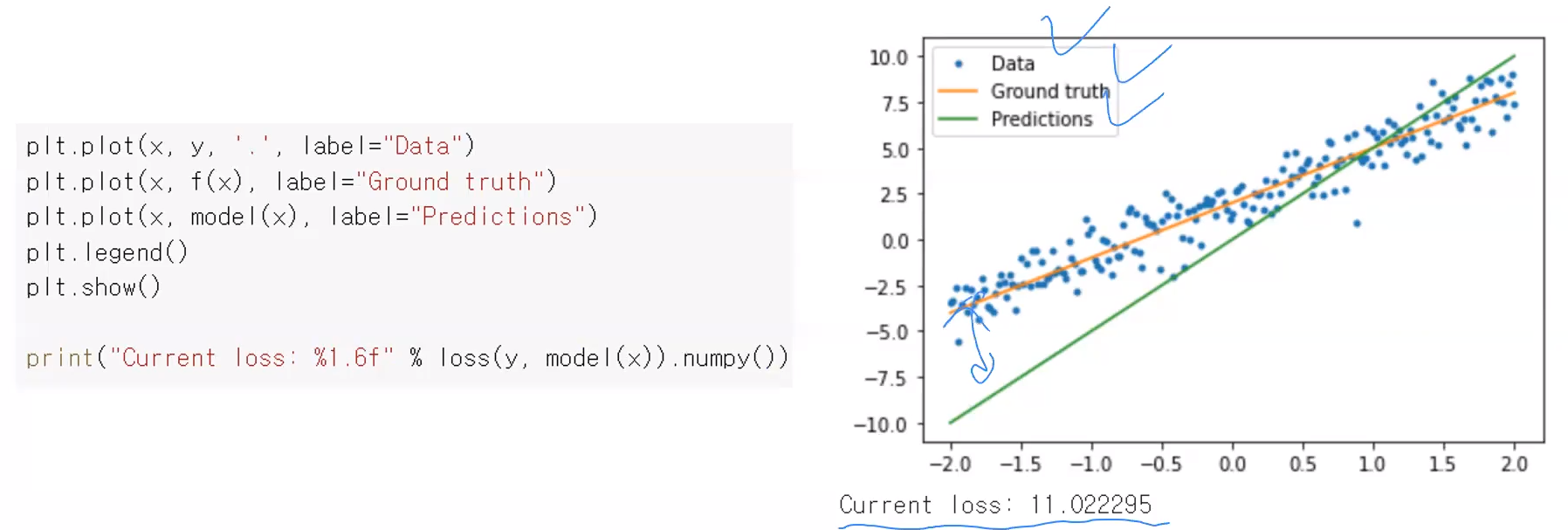
다음 과정으로는 아까 데이터들의 point 를 표시했던것에 이어서, 데이터와 실제 Model 와 우리의 직선이 나타내고 잇는 직선, 그리고 loss 값까지 나타내보는 것이다.
그래프를 보면 현재 우리가 나타내는 Model의 직선(초록색 직선)이 주황색 직선(실제 Model 이 표현하는 직선) 이 많이 빗나가고 있음을 볼 수 있다. 주황색 직선에 맞춰주기 위해 계속 변화를 시켜나갈 것이다.
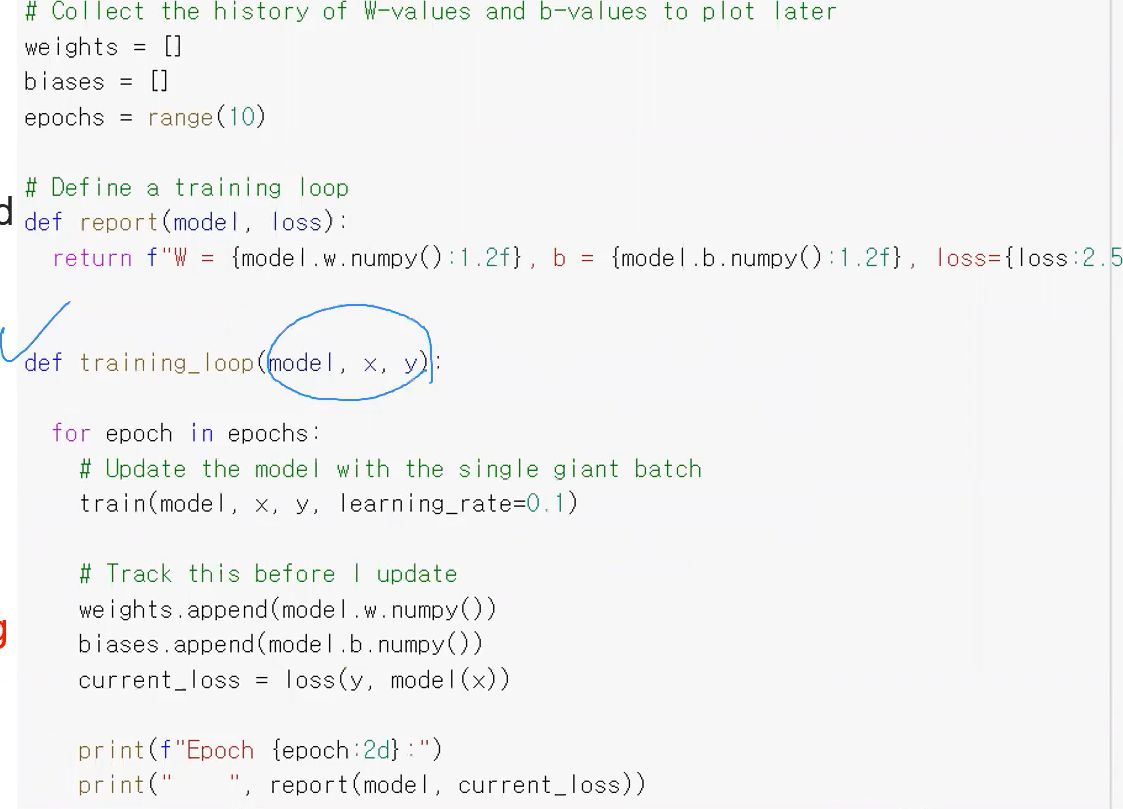
전형적인 graident descent(경사 하강법) 에서의 Training(학습) 반복문 구조
- 앞서 언급했듯이, graident descent(경사 하강법)은 원하는 주황색 직선에 model이 수렴하기 전까지 계속 반복이 필요하다.
(for문 조져야함)
전형적인 graident descent(경사 하강법) 에서의 Training(학습) 반복문 구조는 아래와 같은 4가지 과젇들을 포함한다.
- 1) Model 에 입력을 넣어주어서 예측값을 계산한다.
- Model 에 입력을 넣어줘서 현재 Model 입장에서 변화값은 무엇이라 생각하니? 라고 묻는것
- 2) loss value 값을 계산한다
- 3) gradient tape 를 활용해서 gradient 값을 계산한다
- 4) gradient 값, 즉 미분값이 잘 나왔다면 그 값을 기반으로 변수들의 값을 바꿔준다.
=> 이 1~4 과정을 반복문을 도는 것이다.
우리는 지금부터 살펴볼 예제에서 위 과정들을 한번에 수행해주는 for문이 포함된 train 함수를 정의해보고, 이 함수안에서 traning function 을 호출하는 방식으로 학습을 시킬것이다.

- model : 훈련시킬 모델
- x : 모델에 넣어줄 입력값
- y : label (loss value 계산을 위해 필요)
- learning_rate : graident descent 를 할떄 매번 어느정도로 값을 바꿔갈 것인가 수치

=> 우선 gradient 를 하고자하는 함수를 등록해주었다.
이떄 model(x) 에서 output, 즉 예측값을 계산해낸다. 그러고 아까 정의한 loss 함수를 통해 loss value 를 계산해주는 것이다. (1,2번 과정 수행)

앞서 gradient 를 구하고 싶은 loss value 값에 대해 with tf.GradientTape() 구문에서 선언이 끝났다면, 이제 현재 loss value 에 대한 미분값(gradient) 를 계산해주면 하면된다. 이를 t.gradient 에서 해주고있다.
t.gradient(current_loss, [model.x, model.b]) : current_loss (현 loss value) 에 대해 미분을 하는데, model 의 w (weight)와 b (bias)에 대한 미분을 둘다 하는 것이다.
=> 이렇게 우리가 원하는 목표값을 계산하기 위해 여러개의 값에 대해서 미분을 하고싶다면, 이처럼 리스트 형태로 여러 값들을 파라미터로 넘겨주면 된다.
리스트로 넘겨준 값 순서에 따라서 차례대로 dw, db 에 미분된 값이 저장된다.

마지막으로 model 의 w(weight) 와 b(bias) 를 update 해주면 된다.
이떄 Variable 의 내장함수 assign_sub 란, 기존에 Variable 이 저장하고 있던 값에서 함수의 인자값으로 넘져준 변수의 값만큼을 빼주는 것이다.
=> model.w.assign_sub(learning_rate * dw) : 즉, model 의 Variable 인 w 에서 learning x dw 값을 뺴주고 그 결과값을 다시 model.w 에 저장해주는 것이다. ( w = w - learning_rate x dw 가 수행된다.)
이로써 경사하강법을 수행하는 코드가 다 완성이 된것이다. 이제 이를 원하는 만큼 계속 반복해서 훈련시키면 될것이다.
학습시키기
앞서 만든 train 함수를 활용해서 이제 실제로 training 을 시키면된다.

- epochs : 미리 정한 훈련 반복횟수. 전체 dataset 을 가지고 학습을 시킬때, 보통 epochs 라는 표현을 대중적으로 사용한다.
- ephocs 이 10이라는 것은, 곧 training set 을 가지고 훈련(학습)을 10회 반복했다는 것이다.
=> for 문을 10번 돌면서 매 반복마다 앞서 정의한 train 함수를 호출한다.


- 현재 model 의 각종 값들의 상태를 앞서 정의한 리스트들에다가 기록을 해두는 것이다.
마지막으로 logging 하는 과정이다. for문의 매 반복이 한번 끝날때마다 해당 model 의 값들이 어떻게 되어있는 상태이다라고 간단히 print 하는것

사실상 for문 돌때 이렇게만 구성되어 있어도 당연히 학습이 잘 되긴하는데, 학습이 진행되면서 model 이 어떻게 변화되고 있는지 상태를 확인해보려고 앞선 print 문 같은 것들을 넣어놓은 것이다.
출력결과

-
학습이 진행됨에 따라 loss value 값이 계속 감소하는 모습을 볼 수 있다. 즉, 우리가 원하는 loss 를 추려나가고 있다.
-
또한 맨 마지막에 학습된 값 w, b 를 확인해보면 w 와 b가 각각 3, 2 라는 값에 거의 근사하도록 값이 변한것을 확인할 수 있다.
matplotlib 으로 다시 결과 출력해보기
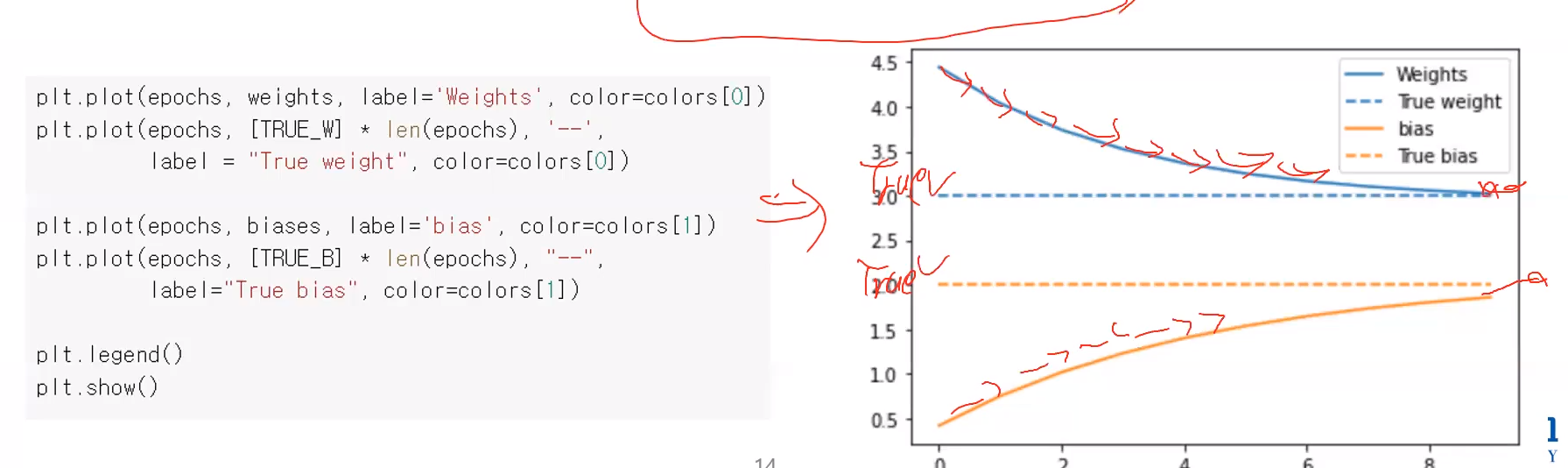
matplotlib 의 plot 함수로 다시 시각적으로 학습 결과를 확인해보자. 위 코드는 학습에 계속 진행됨에따른 w 와 b 의 값을 보여주고 있다.
학습에 진행됨에따라 w 와 b 가 실제값(3, 2) 로 거의 근사하는 모습을 볼 수 있다.
결국 우리가 원하는대로 loss 를 최소화하는 모습이다.
=> 만일 for문을 엄청 더 조져서 w와 b 값이 정확하게 3, 2가 되었다면 오차가 0이기 떄문에, loss value 가 0이 될것이다.
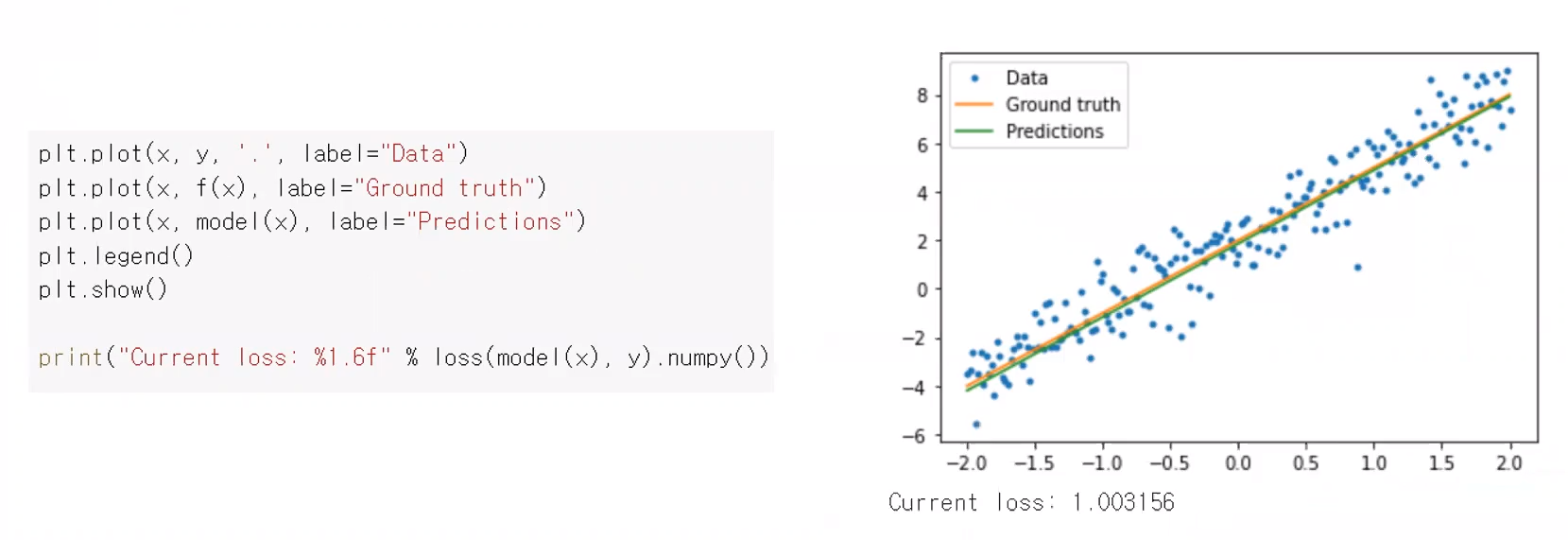
또한 학습된 model을 data 그래프와 같이 그래프로써 출력해보면 두 직선이 거의 차이가 나지 않는 모습을 볼 수 있다. 게다가 loss value 초기에는 11정도나 되었는데, 1로 줄어든 모습을 볼 수있다.
Keras API 활용
- 앞선 방법은 low-level 이고, Keras API 를 활용하면 high-level 로써 linear regrssion(선형 회귀)를 손쉽게 코드를 짤 수 있다.


-
모델을 정의하는 부분이다. 이떄 keras.Sequential() 은 다양한 element 를 순서대로 쌓은 모델이다. Sequential() 안에 들어오는 파라미터의 각 요소들이 들어온 순서대로 모델을 구성하는 것이다.
-
Dense() :y =ax+b 에 대한 아웃풋을 units 옵션에 지정된 개수만큼 생성해내는것
- units : 출력값 개수
