Key Idea
Is there a principled method to scale up ConvNets that can achieve better accuracy and efficiency?
이전 연구에서는 depth(layer), width(channel), image size 중 하나만 scaling을 하여 사용
해당 논문에서는 3가지를 모두 scaling → compound scaling 즉 depth, width, image size 사이의 관계를 표현
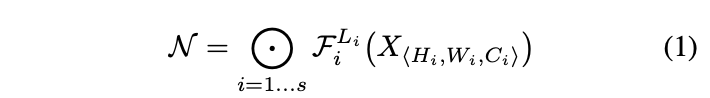
ConvNet은 위와 같은 수식으로 표현 가능
→ 는 input image, 에서 F는 conv 연산 L은 layer의 수를 의미
대부분의 ConvNet design은 best layer architecture()를 찾으려고 노력하는 반면에 model scaling은 정의된 에서 layer architecture는 고정시켜놓고 제한된 resource로 length, width, resolution을 확장시키는 것
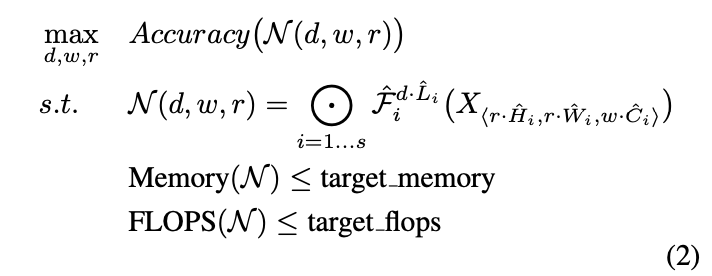
아래 제약조건을 만족하면서 d,w,r을 조절하여 acc를 최대화 하는 것
3.2 Scaling Dimension
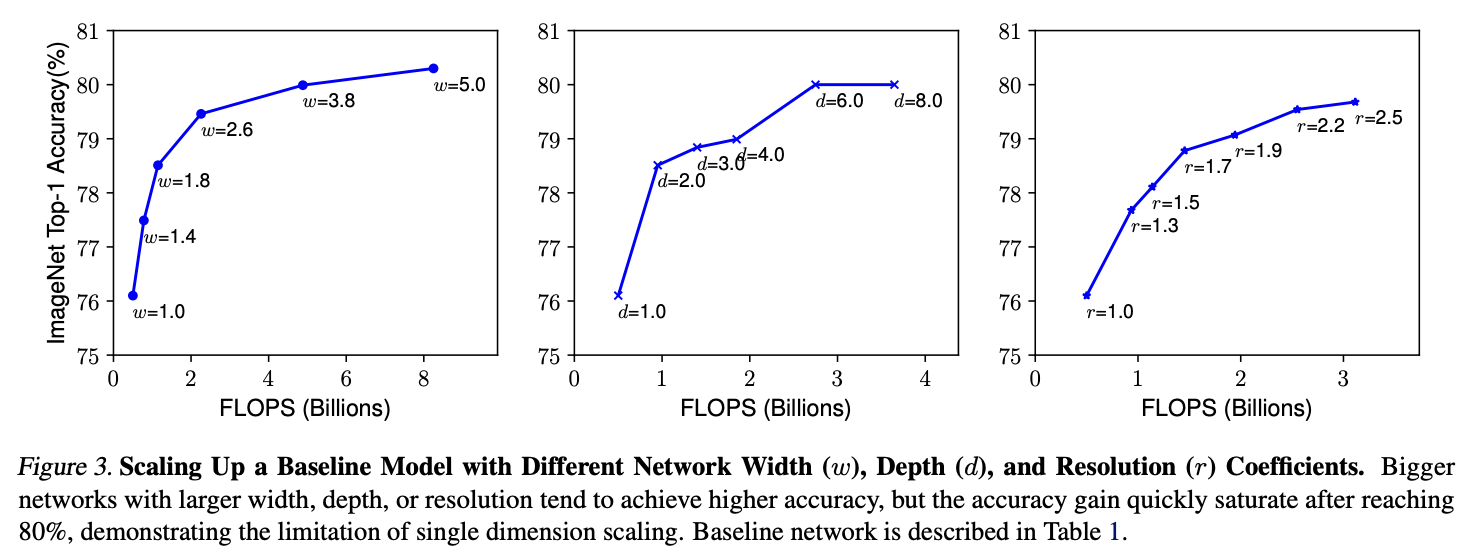
Depth
ConvNet 층이 깊어질 수록 복잡한 feature을 잘 잡아냄
→ but 층이 너무 깊어지면 vanishing gradient등의 문제 때문에 학습시키기가 어려워짐
skip-connection, batch normalization등의 technique이 이러한 문제를 완화해주지만 층이 너무 깊어지면 의미가 없어짐
위 Figure 중앙을 보면 depth = 8일 때 오히려 성능이 떨어짐
Width
Width가 커질 수록 더 세분화된 특징을 잡을 수 있고 훈련하기 쉬워짐
→but Width가 매우 커도 얕으면 feature를 잘 잡지 못함
Resolution
resolution이 높으면 패턴을 잘 잡아냄 → 위 figure를 보면 resolution이 커질 수록 성능 증가율이 조금씩 감소함
r = 1(224x224) r = 2.5(560x560)
결론 → Depth, Width, Resolution이 높을 수록 좋지만 모델이 커질 수록 증가폭은 감소함
Compound Scaling
직관적으로 세가지의 요소가 독립적이지 않음 하나가 커지면 다른 것도 커지는게 성능면에서 좋음
→ 제한된 resource에서 최적의 비율을 찾아내야지~

위 Figure를 보면 해당 직관이 어느정도 맞다라는 것을 확인할 수 있음
→ 결론 더 나은 성능과 효율을 원하면 3가지를 적절하게 scaling 해야함
→ 이전에도 3가지 balance를 찾는 연구가 있었으나 manual tunning 했음 → 멍청이임
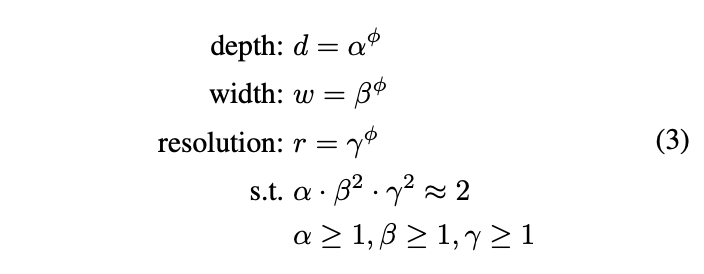
파이는 사용자의 resource, 는 찾아야하는 최적값이다.
- depth 2배 : FLOPS 2배
- width 2배 : FLOPS 4배 — width는 총 2번 연산이 되기 때문 (출력레이어, 다음 입력 레이어)
- resolution 2배 : FLOPS 4배 — resolution은 이미지의 가로x세로를 의미하기 때문에 가로2배, 세로2배로 총 4배가 됨
→ 이해 잘 못했음
Architecture
model scaling은 layer operation 를 바꾸지 않기 때문에 애초에 baseline을 잘 만드는 것이 중요
따라서 최적화된 EfficientNet 개발 → 기존 ConvNet 사용, 정확도 FLOPS 최적화
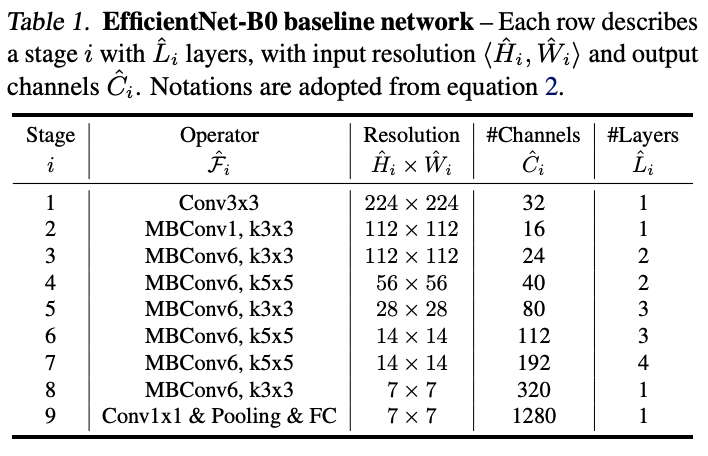
최적화를 진행할 때 대형 모델의 경우, 의 값을 직접 설정하면 더 좋은 성능을 얻을 수 있지만 많은 비용이 들어가기 때문에 아래와 같이 작은 baseline network 에서 알파, 베타, 감마 값을 계산한 다음(STEP1), 다른 모든 모델에 대해 동일한 스케일링 계수를 사용(STEP2)
- STEP1: 파이를 1로 고정 → resource가 두 배라고 가정하고 위 식 두 개를 이용해 Small grid search
- STEP2: 상수로 고정 → 계산식 3번 따라 baseline network scale up
Experiment
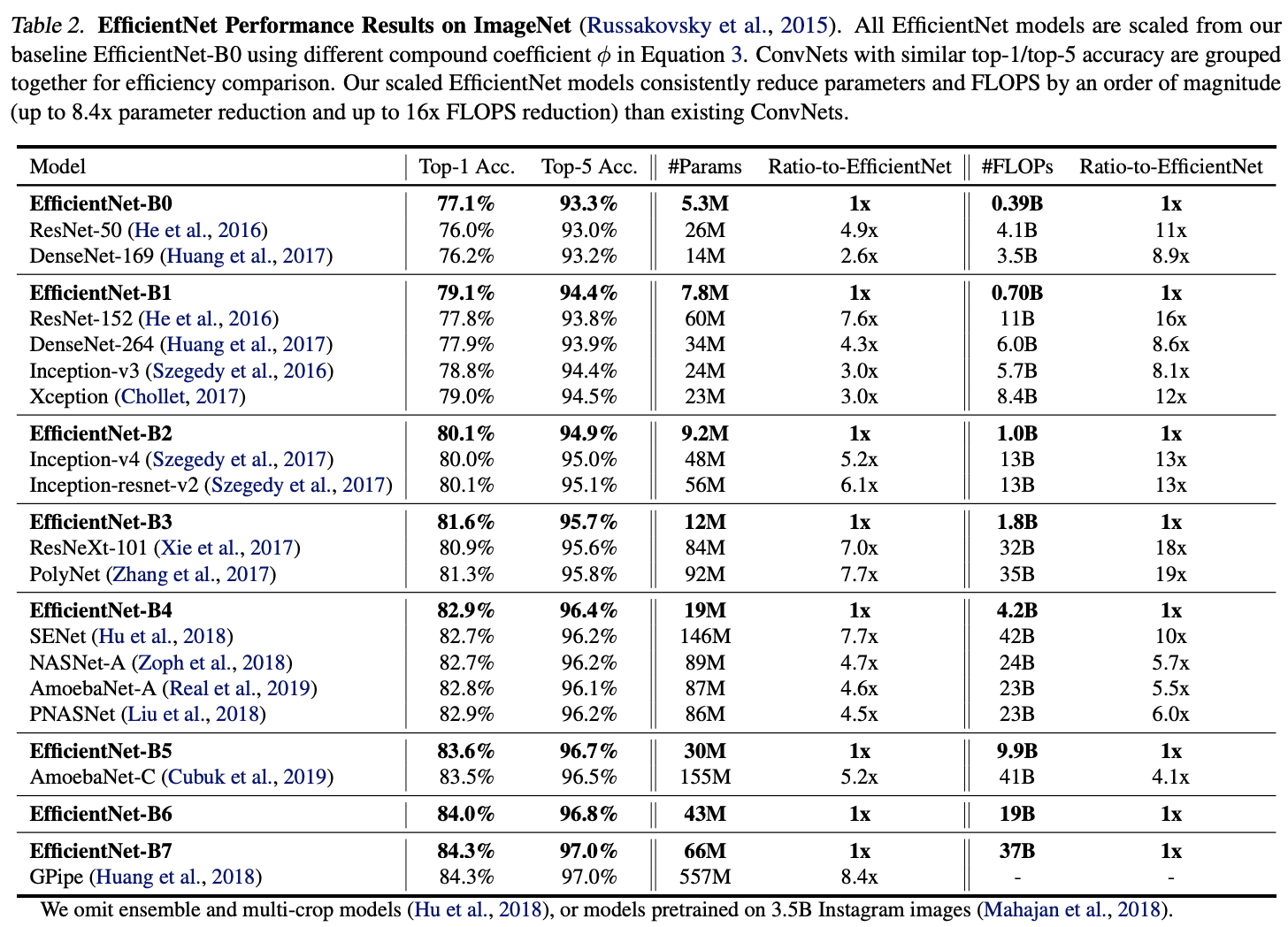
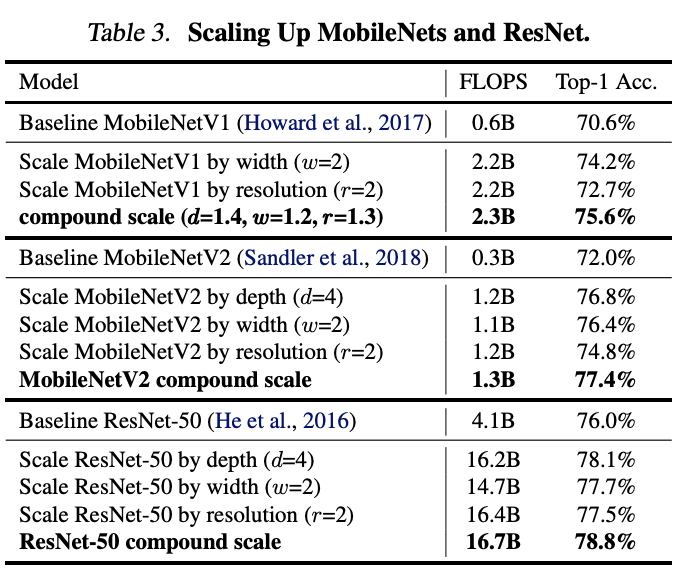

Discussion
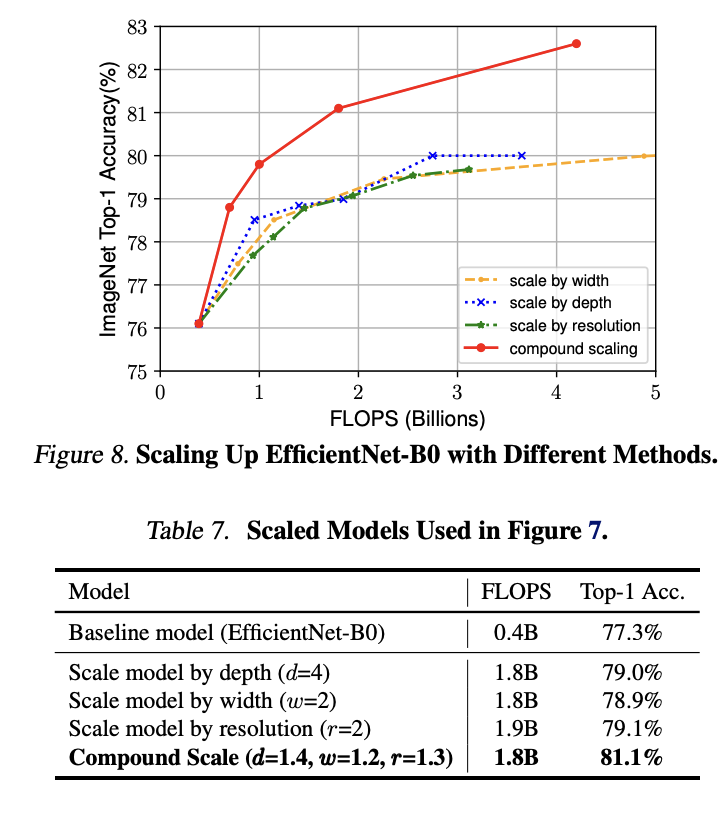
비슷한 FLOPS에서 하나만 scaling 하는 것보다 compound scale 하는 것이 좋음
Result
기본 ConvNet을 어떤 목표 리소스 제약에도 더 원칙적인 방식으로 scale up할 수 있으며, 모델 efficiency 유지 가능
compound scaling하여, mobile-size의 EfficientNet 모델을 효과적으로 확장 가능
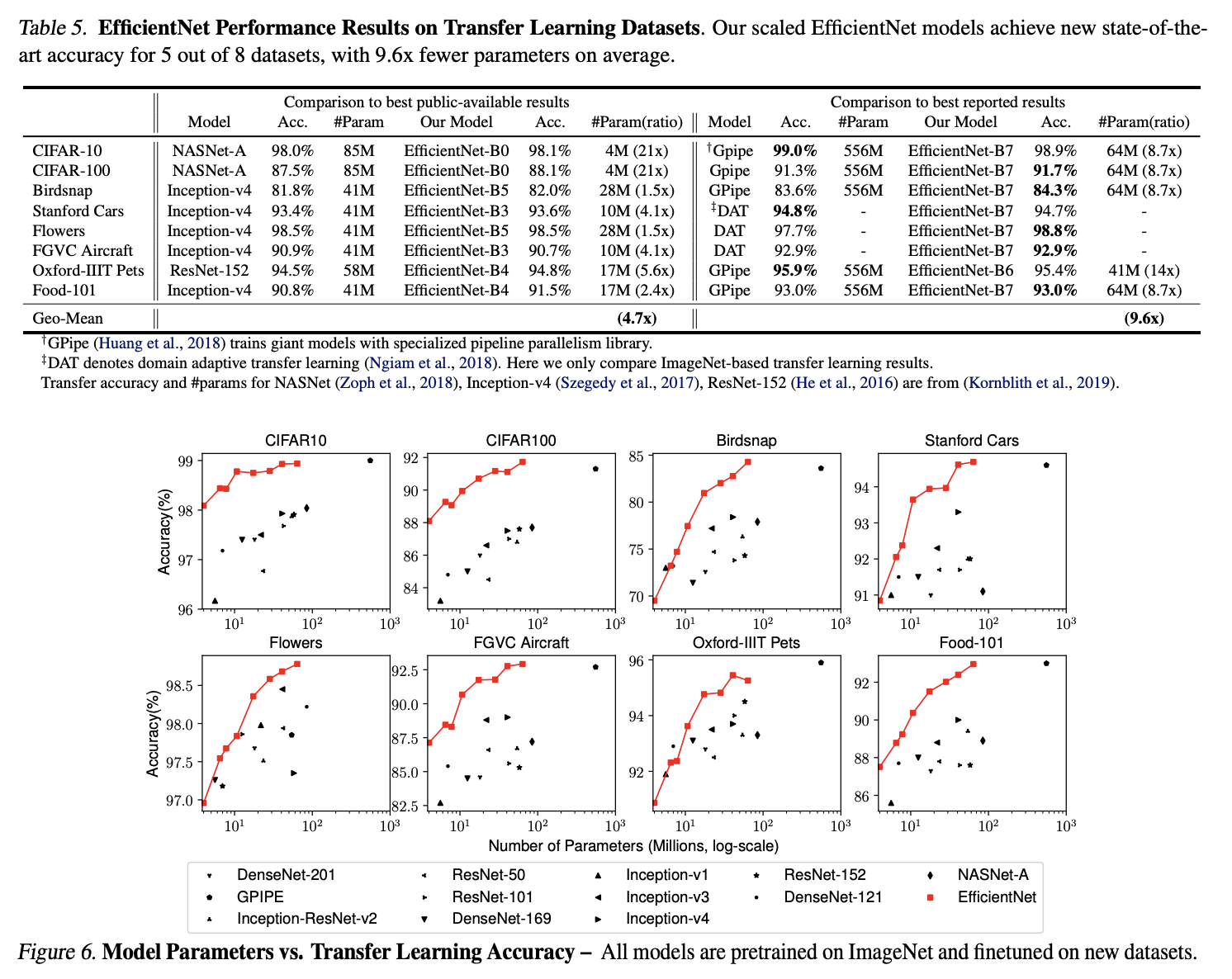
파라미터 및 FLOPS 수를 줄이면서도 state-of-art 달성
