1. Introduction
Machine learning system은 큰 dataset과 고용량의 모델, supervised learning 등을 통해 빠르게 발전해왔다. 이러한 방법으로 개발된 모델들은 데이터의 분포가 살짝만 바뀌어도 불안정하며 특정 Task에서만 좋은 성능을 발휘한다.
그래서 많은 Task에 적용 가능한 더 범용적인 모델을 개발할 필요가 있다.
→ 유지 보수나 리소스 측면에서 gerneral한 모델을 만드는 것이 좋다.
현재 기계학습체계를 개발하는 주된 방법은 목표 과제에 맞는 dataset을 찾아서, 이를 train, test 단계로 나누어 학습 후 IID(independet and identically distributed)로 성능을 측정하는 방법이다. 이는 좁은 범위의 과제에서는 매우 효과적이나 범용적인 이해를 필요로 하는 독해나 다양한 이미지 분류 시스템 등의 문제에서는 높은 성능을 내지 못했다.
Multitask learning은 일반 성능을 높이는 유망한 방법이지만 아직 초기 연구 단계이다. 최근의 machine learning system은 일반화를 위해서는 수십만 개 정도의 학습 샘플을 필요로 하는데 이는 multitask learning을 위해서는 그 몇 배가 필요하다는 것을 뜻한다.
가장 성능이 높은 언어처리 모델은 pre-training과 supervised fine-tuning의 결합으로 만들어졌다.
이러한 방법들은 여전히 supervise learning을 필요로 한다. 만약 supervise data가 최소한으로 또는 전혀 필요하지 않다면, commonsense reasoning이나 sentiment analysis과 같은 특정 과제들을 수행하는 데 큰 발전이 있을 것이다.
이 논문에서는 언어 모델이 어떤 parameter나 모델 구조의 변화 없이도 zero-shot setting 하에서 downstream task를 수행할 수 있음을 보인다. 이 접근법은 언어 모델이 zero-shot setting 하에서 넓은 범위의 과제를 수행할 수 있는 가능성을 보이며, 과제에 따라서는 state-of-the-art를 달성하였다.
2. Approach
GPT-2의 핵심 접근법은 language modeling이다. language modeling은 입력 , 으로 부터 unsupervised distribution을 예측한다.
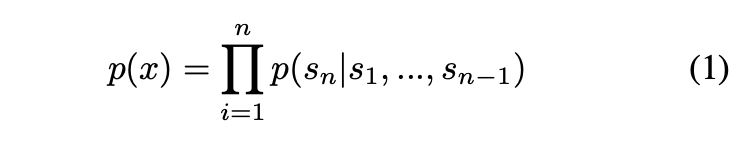
→ 언어는 순서를 가지고 있음으로써 조건부 확률을 통해 unsupervised distribution을 예측할 수 있다.
-
기존 single task를 수행하는 것은 확률분포 을 예측하는 것으로 표현됐다.
→ single task에서는 주어진 input에 대한 output이 정해져있다. -
다양한 task를 수행하는 모델에서는 하나의 input에 대해 task에 따라 다른 output이 나올 수 있다.
→ 이러한 경우 확률분포 를 예측하도록 모델링 해야한다.
예를들어 기계번역(영어 -> 프랑스어)을 학습하기 위해서는 (translate to french, english text, french text)를 input sequence로 넣어준다.
reading comprehension(QA)을 학습하기 위해서는 (answer the question, document, question, answer)와 같은 형태로 input sequence로 넣어준다.
언어모델은 supervised objective의 global minimum은 subset of the sequence단위에서 evaluated 되는 것을 제외하고는 unsupervised objective들의 global minimum과 같다. 따라서 supervision 없이 decaNLP(QA, machine translation, summarization, setiment analysis)의 task들을 학습가능하다.
2.1 Training Dataset
이전의 연구들에서는 single domain(ex. news article, fiction book)에 대해서만 모델을 학습하였다. 하지만 해당 연구에서는 task들에 대해 zero-shot learning을 가능하게 하기 위해 가능한 많은 양의 데이터를 다양한 domain에서 가져오고자 하였다.
Common crawl과 같은 web scraping 데이터는 다양하고 무한에 가까운 텍스트를 뽑아낼 수 있다.
→ 해당 논문에서는 data quality issue와 학습 전 특정 task에 대한 정보가 들어가는 것을 방지하고자 새로운 Web Scraping 데이터를 만들었다. 해당 데이터는 Reddit에서 3karma 이상 받은 outbount link 데이터를 모두 scrap하여 사용하였다.
해당 데이터를 WebText라고 명명하였다.
WebText는 800만개가 넘는 문서가 포함된 총 40GB의 텍스트가 포함되어있다.
2.2 Input Representation
당시 language model(LM)은 lower-casting, tokenization, oov 등 preprocssing이 필요했다. 이러한 preprocessing은 모델링 할 수 있는 문자열을 제한한다.
유니코드(UTF-8)은 이 점을 완화할 수 있지만 byte-level 모델링은 word-level 모델링보다 성능이 떨어진다는 단점이 있다.
따라서 해당 논문에서는 이 문제를 해결하고자 Byte Pair Encoding(BPE)를 제안한다.
BPE는 character와 word의 중간지점이며 word-level 입력과 character-level 입력에 대해 보간할 수 있다.
유니코드 기반으로 BPE를 구현하면 130000이 넘는 base vocabulay가 필요하다. 이는 전형적인 BPE vacab 크기 32000~64000과 큰 차이가 난다. BPE를 byte-level에서 구현하면 base vocab size가 256밖에 되지 않는다.
하지만 BPE를 byte-level에서 적용하는 것은 sub-optimal하기 때문에 BPE가 (dog. dog! dog?)와 같은 변형 토큰을 저장하는 것을 막기 위해 BPE가 character category가 다르면 merge하지 않게 제한한다.
이러한 input representation을 사용하면 word-level LMs의 이점과 byte-level approach의 일반성을 결합하여 사용한다는 이점이 있다.
왜냐하면 이런 approach가 어떤 유니코드 문자열에도 확률을 할당할 수 있으므로 preprocessing과 관계없이 어떤 dataset에 대해서도 evaluate 할 수 있다.
2.3 Model
몇 가지 수정사항을 제외하고는 GPT-1 모델을 따른다.
수정사항
1. pre-activation residual network와 비슷하게 Layer normalization이 각 sub-block의 input으로 이동하였다.
2. 마지막 self-attention block 뒤에 layer normalization을 추가하였다.
3. residual layer의 깊이에 따라 intialization 다르게 해준다. 을 layer의 깊이라 했을 때 Residual layer의 weight에 을 곱해 scaling 해준다.
4. vocabulary size가 50,257로 늘어났으며 context size가 512 -> 1024 token으로 늘어났고 batch size 또한 512로 늘어났다.
3. Experiment

4개의 모델을 만들어 실험하였다.
가장 작은 모델은 기존 GPT1과 크기가 동일하고 두번째로 작은 모델은 BERT와 크기가 동일하다.
해당 모델 중 가장 큰 모델을 GPT-2라고 소개한다.
각 모델의 Learning rate는 WebText의 5%에 해당하는 held-out sample을 통해 수동으로 조정하였다.
모든 모델이 WebText에 underfit 되었으므로 많은 시간을 training에 투자하면 성능이 더 오를것으로 판단된다.
3.1 Language Modeling
zero-shot task 성능을 실험해보기 위해 다양한 task에서 성능을 평가한다. out-of-distribution에 대해 평가한다.
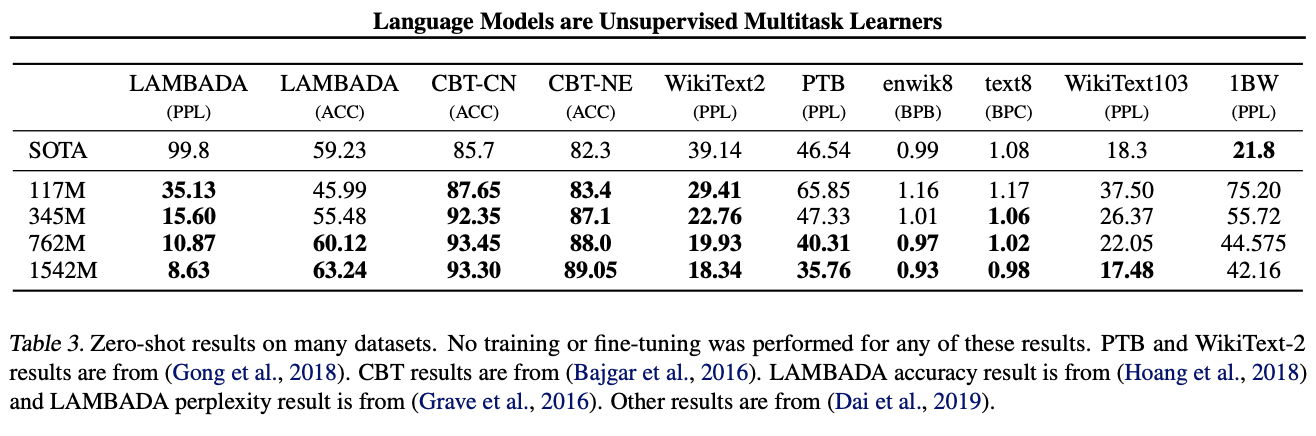
8개의 data set중 7개의 data set에 대해 SOTA를 달성하였다.
특히 long-term dependecies를 평가하는 LAMBADA, CBT에서 큰 성능 향상을 보였다.
3.2 Children’s Book Test
CBT는 명명된 개체, 명사, 동사, 전치사 등 다양한 범주의 단어에 대한 LM의 성능을 평가하기 위해 만들어진 dataset이다.
CBT dataset은 perplexity 대신 cloze test의 accuracy를 evaluation metric로 사용한다.
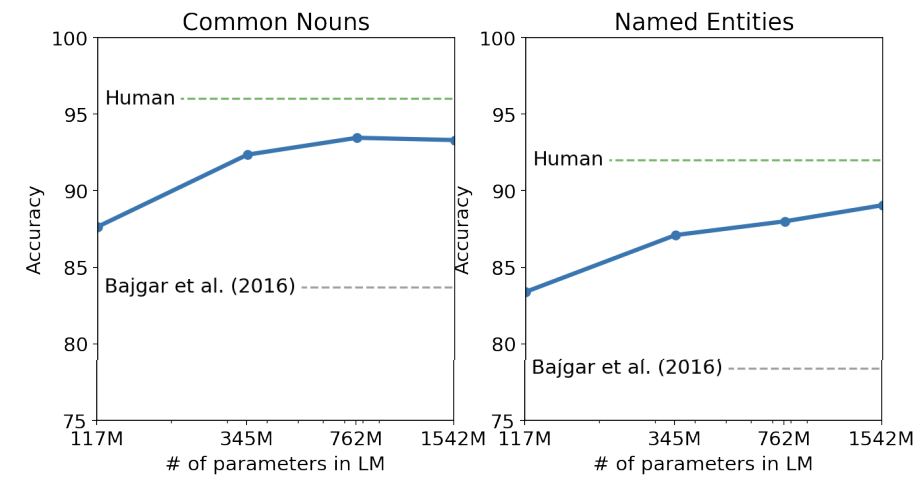
모델 사이즈가 커질수록 human performance와의 차이가 줄어듦을 볼 수 있다. 해당 실험에서 CBT test book 중 WebText와 겹치는 부분이 있어 해당 부분을 validation set에서 제외하고 실험을 하였다.
3.3 LAMBADA
LAMBADA dataset은 모델의 long-range dependencies를 평가하는 dataset이다.
token이 50개가 넘는 sentence에서 마지막 word를 예측하는 task이다.
→ GPT-2는 해당 task에서 99.8 -> 8.6의 perplexity를 달성하였으며, accuracy를 19% -> 52.66%까지 향상시켰다.
추후에 GPT-2의 오류를 조사한 결과, 예측하는 것이 final word가 아니라 sentence의 valid continuation이라는 것을 알고 stop-word filte을 추가하여 accuracy를 63.24%까지 향상시켰다.
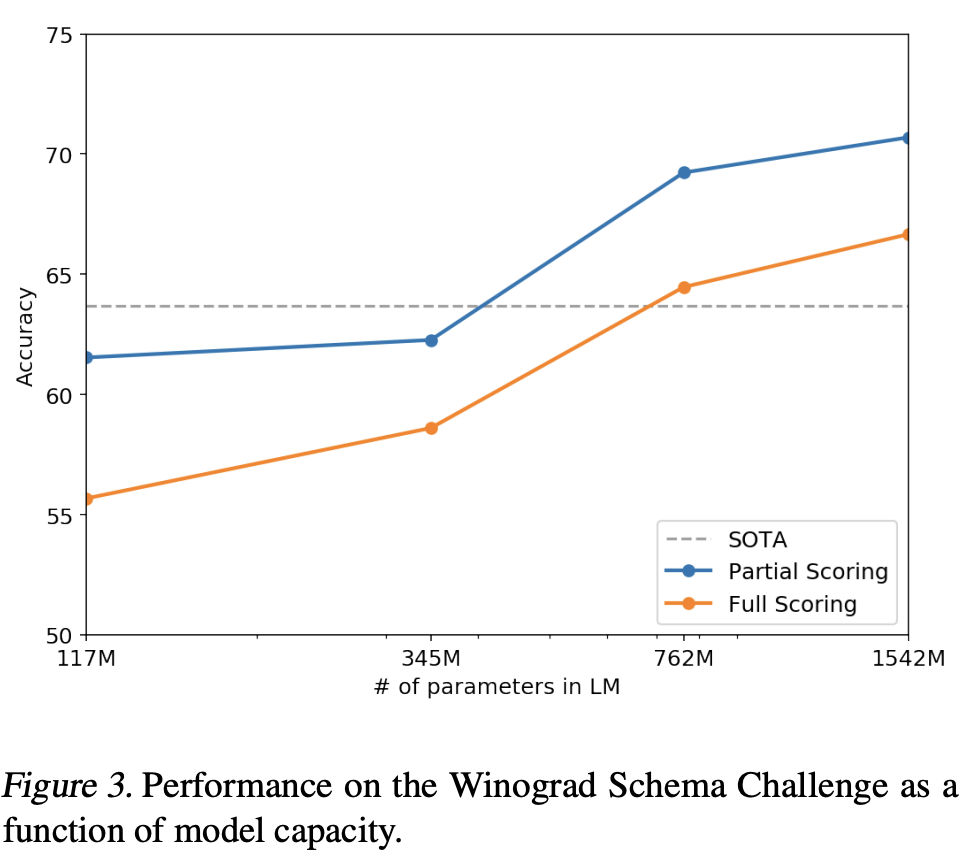
3.4 Winograd Schema Challenge
해당 실험은 text 속의 모호함을 얼마나 잘 처리하는지 평가한다.
→ commonsense reasoning
3.5 Reading Comprehension
Conversation Question Answering dataset (CoQA)은 7개의 다른 domain에서 온 document에서 질문과 답이 대화형식으로 들어있는 dataset이다.
zero-shot setting에서 F1-score 55를 달성하였다. fine-tuning을 한 BERT는 F1-score 89였다.
3.6 Summarization
CNN과 Daily Mail dataset
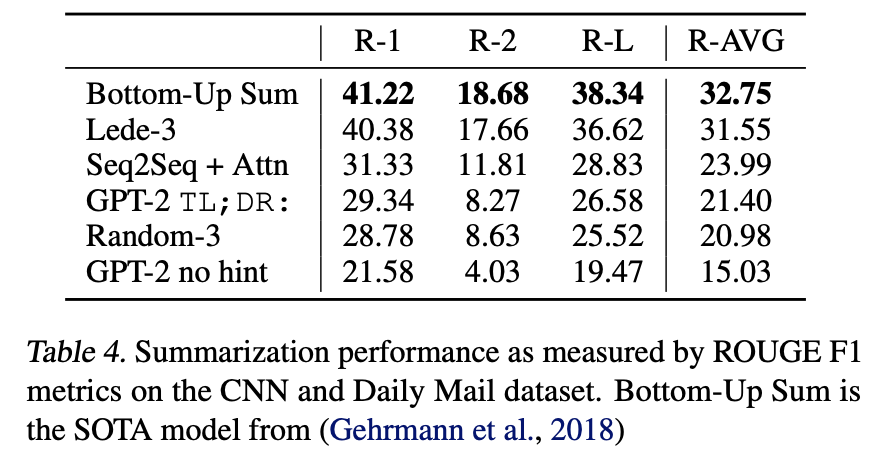
요약에서 좋은 성능을 내지 못했다.
3.7 Translation
WMT-14 English-French test set에 대해서 5BLEU를 달성하였고 WMT-14 French-English test set에 대해서 11.5BLEU를 달성하였다. 다른 기존 모델에 비해 낮은 성능을 보인다.
3.8 Question Answering
SQUAD와 같은 dataset에서 reading comprehension을 평가하기 위해 사용되는 metric(답변이 질문에 정확하게 일치하나?)로 평가 되었을 때 질문 4.1%를 정확하게 답변했다고 한다.
WebText LM중 가장 작은 모델은 1%도 넘지 못했다. GPT-2는 가장 작은 모델보다 5.3배 가량 정확하게 답변했다고 한다.
이런 task에서 model capacity가 큰 영향을 끼친다고 주장한다.
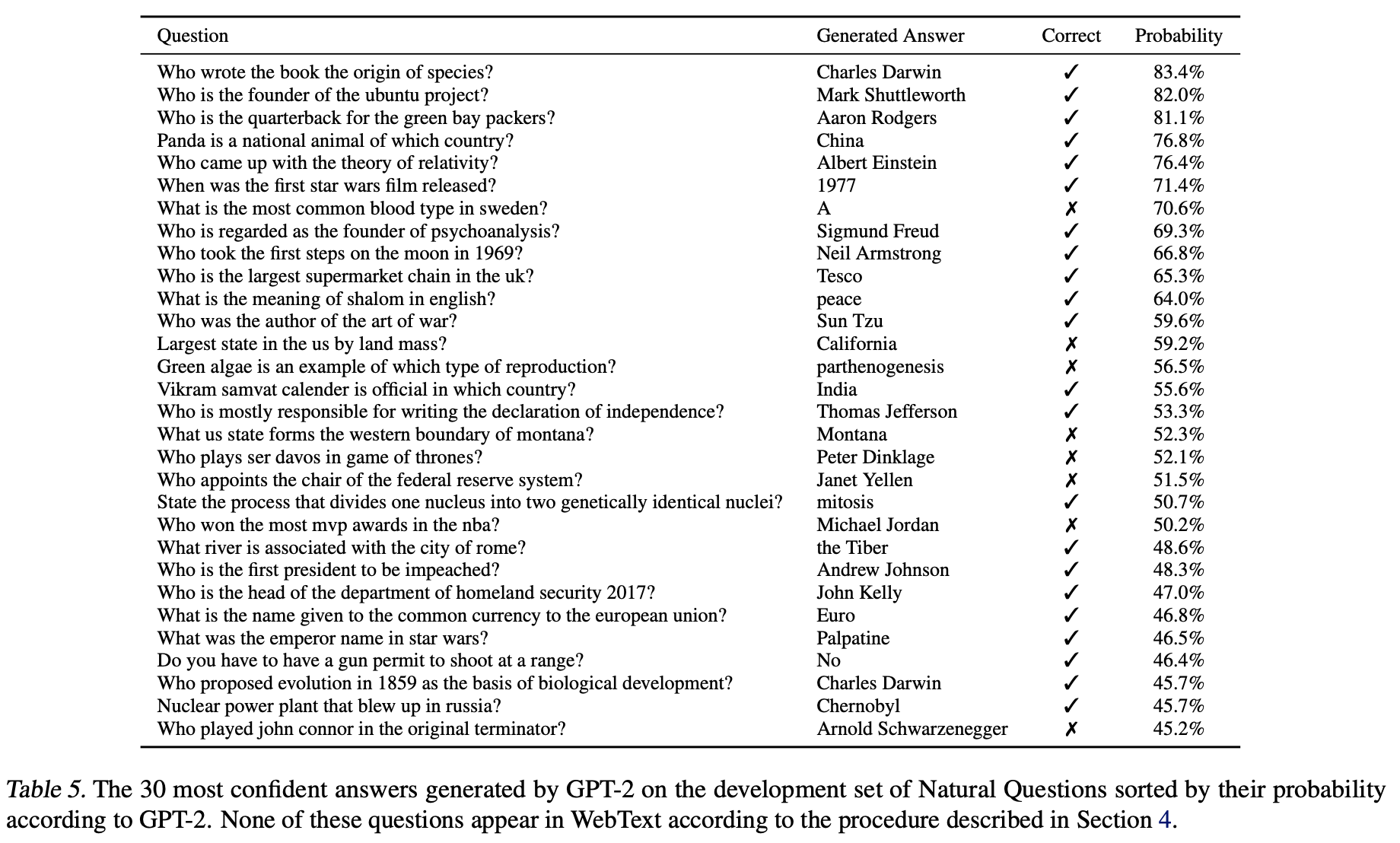
GPT-2는 가장 신뢰도가 높은 답변 1%에 대해 평균 63% 정도의 정확도를 보였다.
아래의 표는 해당 답변의 일부이다.
4. Generalization vs Memorization
WebText는 데이터 양이 방대하므로 기존의 dataset과 overlap이 될 가능성이 존재한다. 이러한 경우엔 생성하는 것이 아닌 dataset에서 기억하는 내용을 그대로 출력하는 것으로 여겨질 수 있다.
아래 표는 벤치마크 dataset과 overlap된 정도를 보여준다.
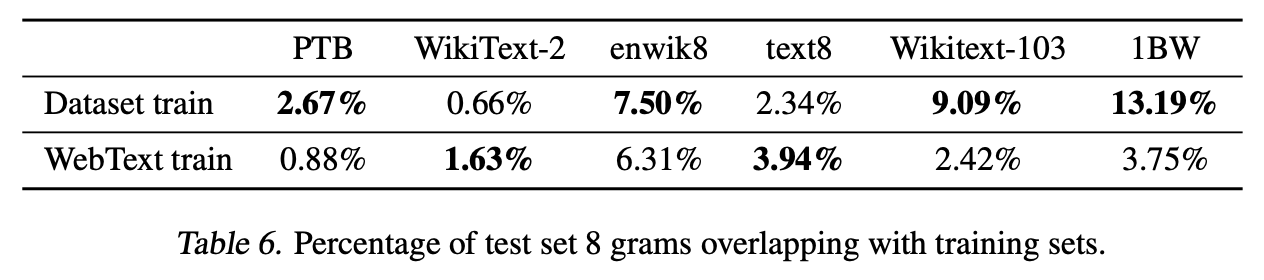
약간의 overlap이 있어 영향이 있을 수도 있지만, 기존 벤치마크 dataset의 train, test set이 overlap 되는 정도에 비해서는 크지 않다.
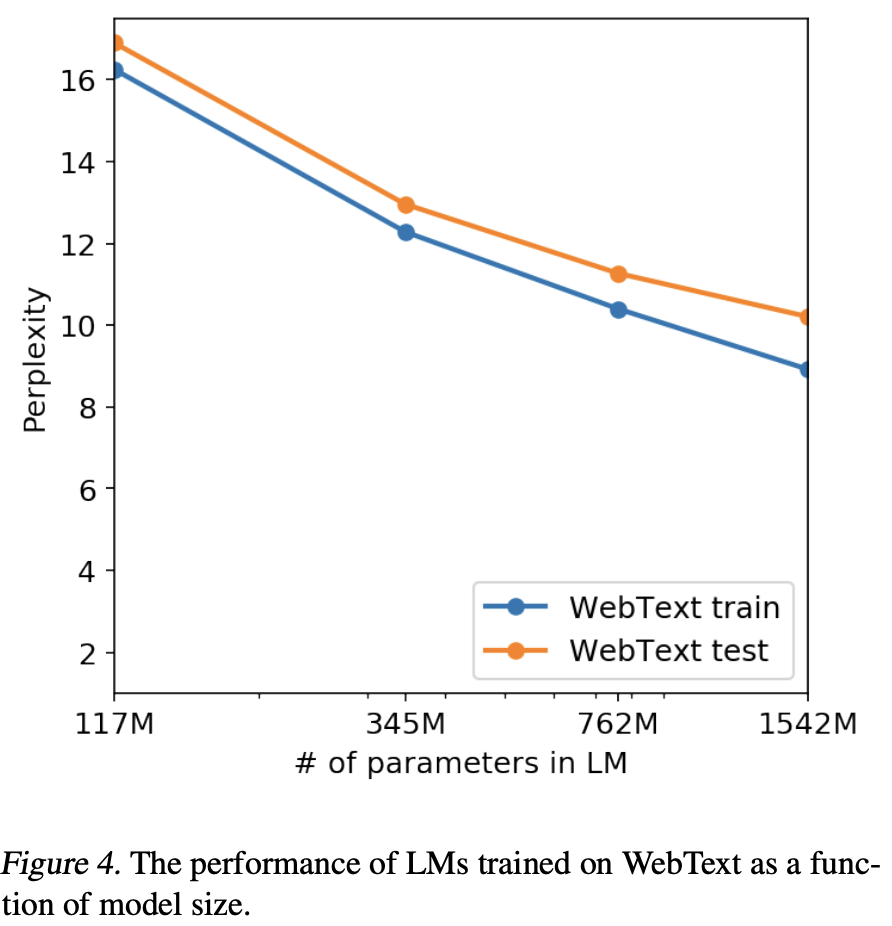
아래의 그래프에서 train set과 test set의 성능은 거의 비슷하며, 또한 모델 크기에 따라서 동시에 성능이 증가하고 있음을 보여준다.
아래 그래프를 보면 train, test에서의 성능이 거의 비슷하다.
이것은 Memorization을 통한 성능 개선이 아니었다고 말할 수 있다.
또한 모델의 크기가 커짐에 따라 성능이 계속 증가하고 있다. 이는 WebText dataset에 대해 underfitting 되어 있다고 볼 수 있다.
6. Discussion
해당 논문은 unsupervise task learning이 추가적으로 연구할 거리가 있음을 보여준다.
GPT-2는 reading comprehension 등에서는 좋은 성능을 보여줬지만 summarization 등에서는 기존 모델보다 좋지 못한 성능을 보여줬다.
decaNLP와 GLUE에 fine-tuning을 해볼 계획이라고 한다.
7. Conclusion
GPT-2는 방대한 텍스트 데이터를 학습하여 특정 작업에 대한 별도의 훈련 없이도 다양한 작업에서 우수한 성능을 발휘할 수 있었다. 이는 모 이러한 모델은 제로샷 학습에서도 높은 성과를 거두며, 특정 언어 모델링 데이터셋 중 7개에서 최고 수준의 성능을 보였다.
하지만 특정 작업에 대한 성능을 더 향상시키기 위해서는 해당 작업에 특화된 데이터로 모델을 미세 조정하는 것이 필요하다.
