Practical considerations
-
딥러닝을 성공적으로 적용하는 것
- 알고리즘을 아는 것 이상이 필요하다.
-
또한 알아야 한다.
-
특정 응용 프로그램에서 골라야 할 알고리즘
-
실험으로 부터 얻은 피드백을 모니터하고 응답하는 것
-
-
신경망 훈련: 매우 중요 / 높은 비용 ⇒ 신중한 전술 필요
-
데이터를 더 모을 것인지 아닌지
-
모델 용량 증가 / 감소
-
정규화 추가 / 제거
-
최적화 개선
-
근사 추론 개선
-
디버그 소프트웨어 구현
-
Data preprocessing
-
벡터화
-
신경망의 모든 입력 및 대상은 부동 소수점 데이터의 텐서 또는 정수의 텐서여야 한다.
-
모든 데이터는 텐서로 처리해야 한다.
-
-
값 정규화
-
일반적으로 상대적으로 큰 값을 갖는 데이터를 신경망에 공급하는 것은 안전하지 않다.
-
값 정규화, 차원 축소
-
Data preprocessing (cont.)
-
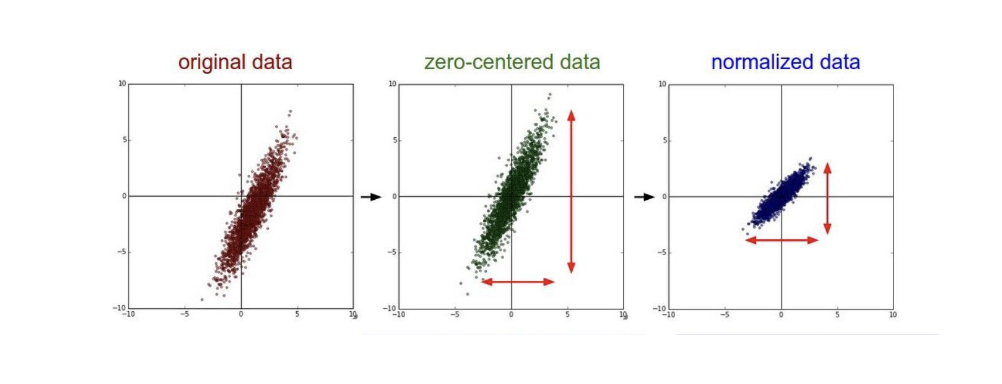
zero-centering
- mean substraction (데이터-평균)
-
normalization (g-transformation)
- mean subtraction + division by standard deviation
- 평균 0, 분산 1
-
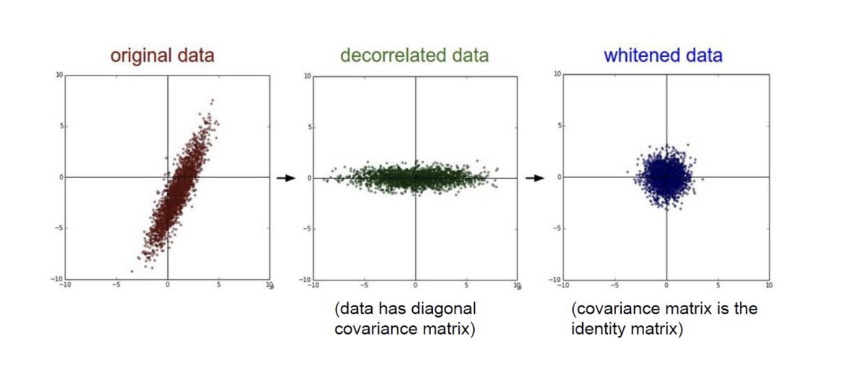
decorrelation
- PCA에서 지정한 방향으로 데이터 회전
-
whitening
- decorrelation + normalization
-
*image data: typically zero-centering only
- 이미지 자체 정보 손실 우려
Data preprocessing (cont.)
-
정규화의 중요성
-
importance of zero-centering
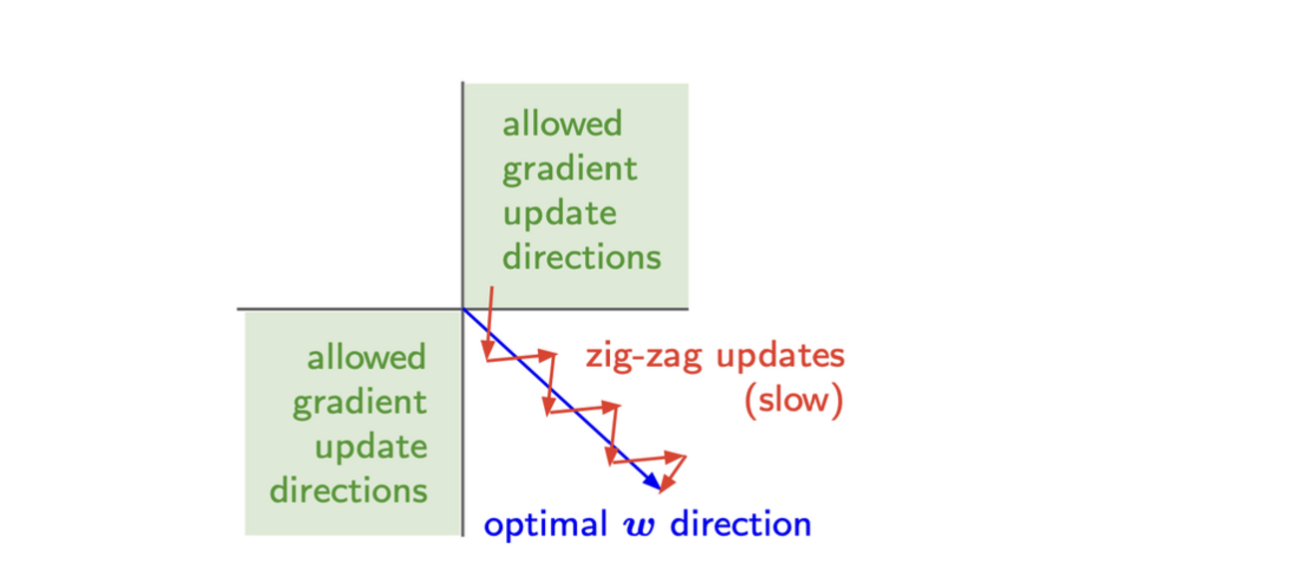
- 모두 양수 / 음수인 input → 학습경로 진동 유발 (zig-zag updates) → 수렴 느려짐
-
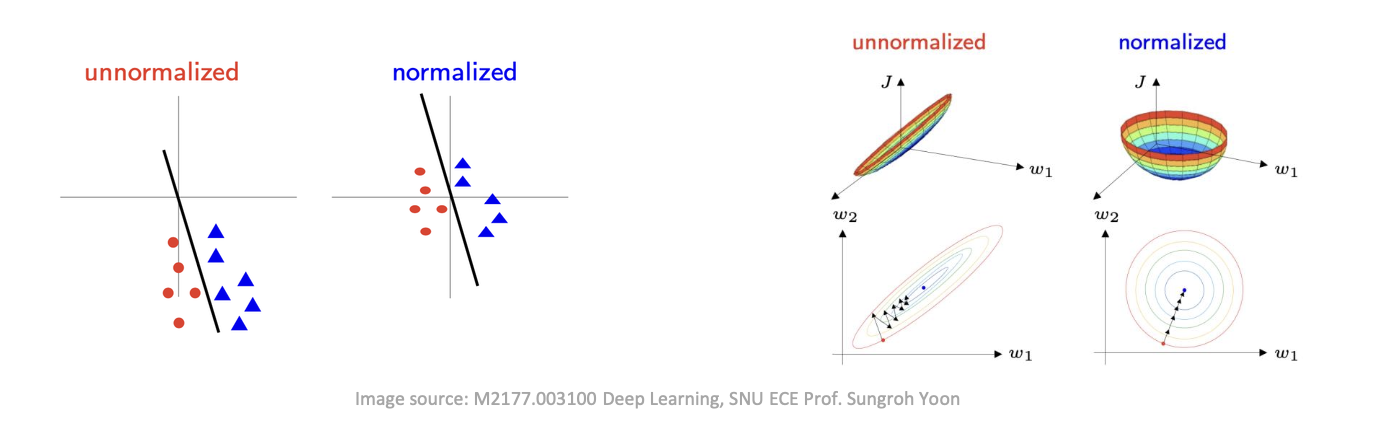
정규화의 중요성
- 최적화 하기 쉬움
-
-
주의점: training data에 대해서만 계산 → 개발, 테스트 데이터에 적용 (e.g. mean, std)
Data preprocessing (cont.)
-
Feature engineering
-
딥 러닝이 대부분의 Feature engineering의 필요성을 제거하더라도 Feature engineering에 대해 걱정할 필요가 없다는 의미는 아니다.
- 좋은 feature 를 사용하면 더 적은 리소스와 훨씬 적은 데이터로 문제를 해결할 수 있다.
-
Weight initialization
-
최종 가중치에 대한 합리적인 가정
-
대략 절반은 양수, 절반은 음수
-
가중치 0: 예상에서의 “최선의 추측”
-
-
모두 0으로 초기화
-
모든 뉴런은 동일한 출력/기울기/가중치 업데이트를 계산한다.
-
뉴런 사이의 비대칭 원인 없음
- 약간의 분산이 있는 제로 평균 가우시안을 사용하여 가중치를 초기화한다
-
Weight initialization (cont.)
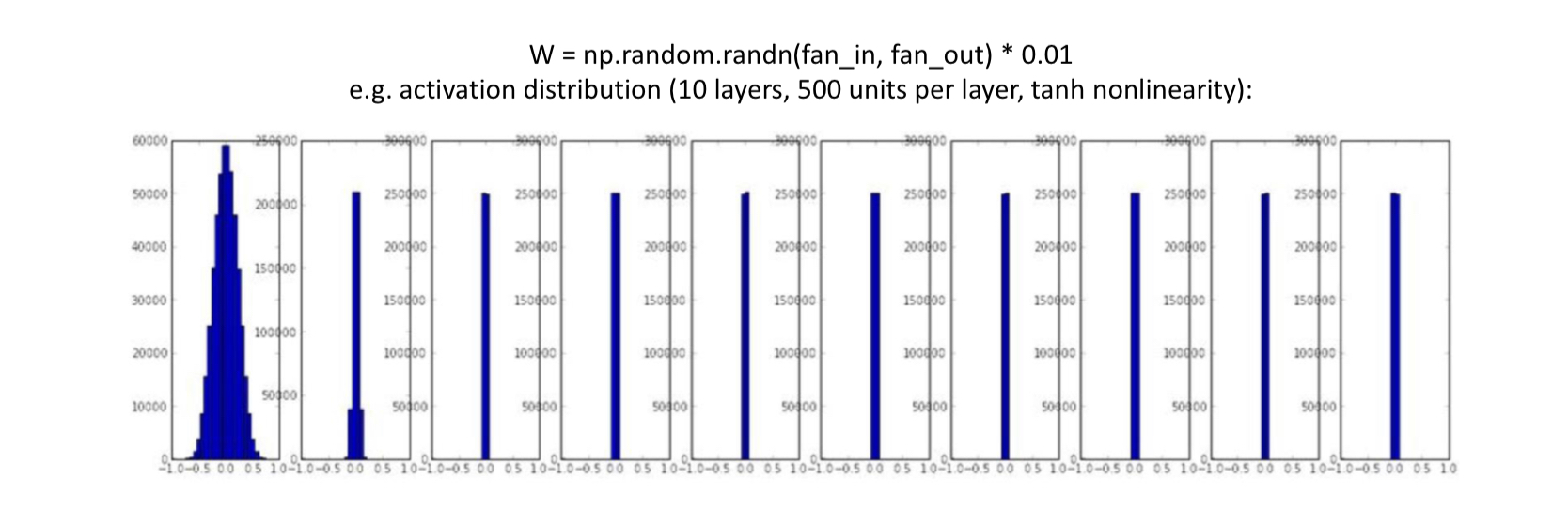
작은 난수로 초기화
-
소규모 네트워크에서는 잘 작동하지만 더 깊은 네트워크에서는 문제가 있음
-
모든 활성화가 빠르게 0이 됨→그라디언트 소멸
-
어떤 input을 넣던 간에 결과가 다 0이 되어버려서 학습에 의미가 없다. (activation이 0이 됨)
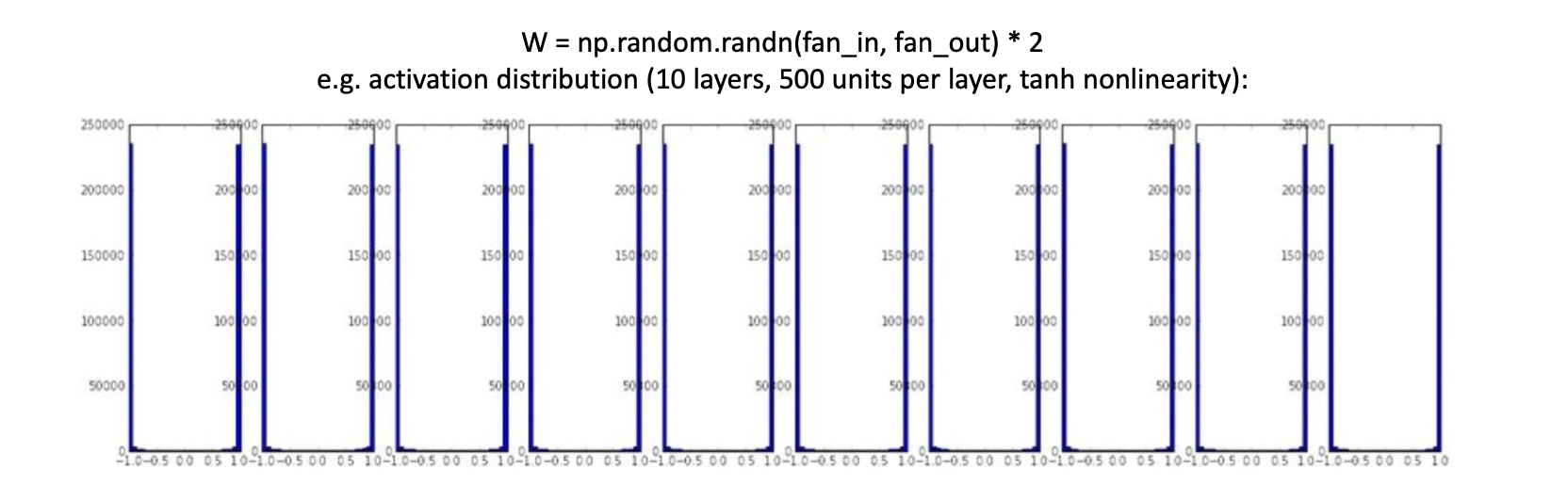
큰 난수로 초기화
- 거의 모든 뉴런이 -1 또는 1로 완전히 포화된다. 그라디언트는 모두 0이된다.
y 가 너무 크거나 작으면 안된다 → 가중치 값은 데이터 개수에 반비례해야한다.
- 즉, 가중치는 데이터 개수에 비례하게 작아져야한다. 그래야 밀접한 scale을 찾을 수 있다.
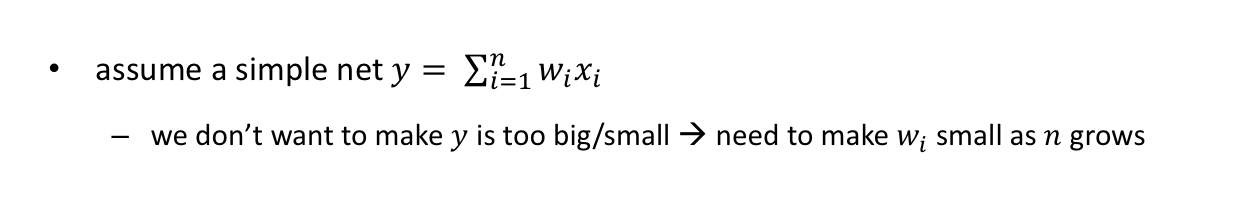
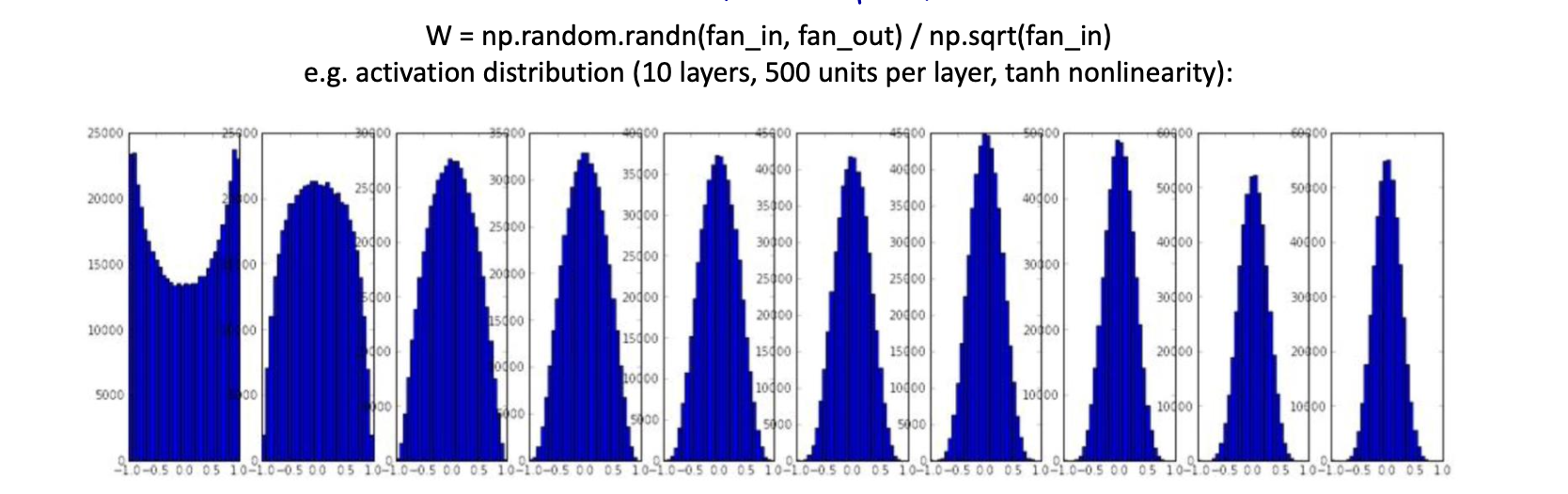
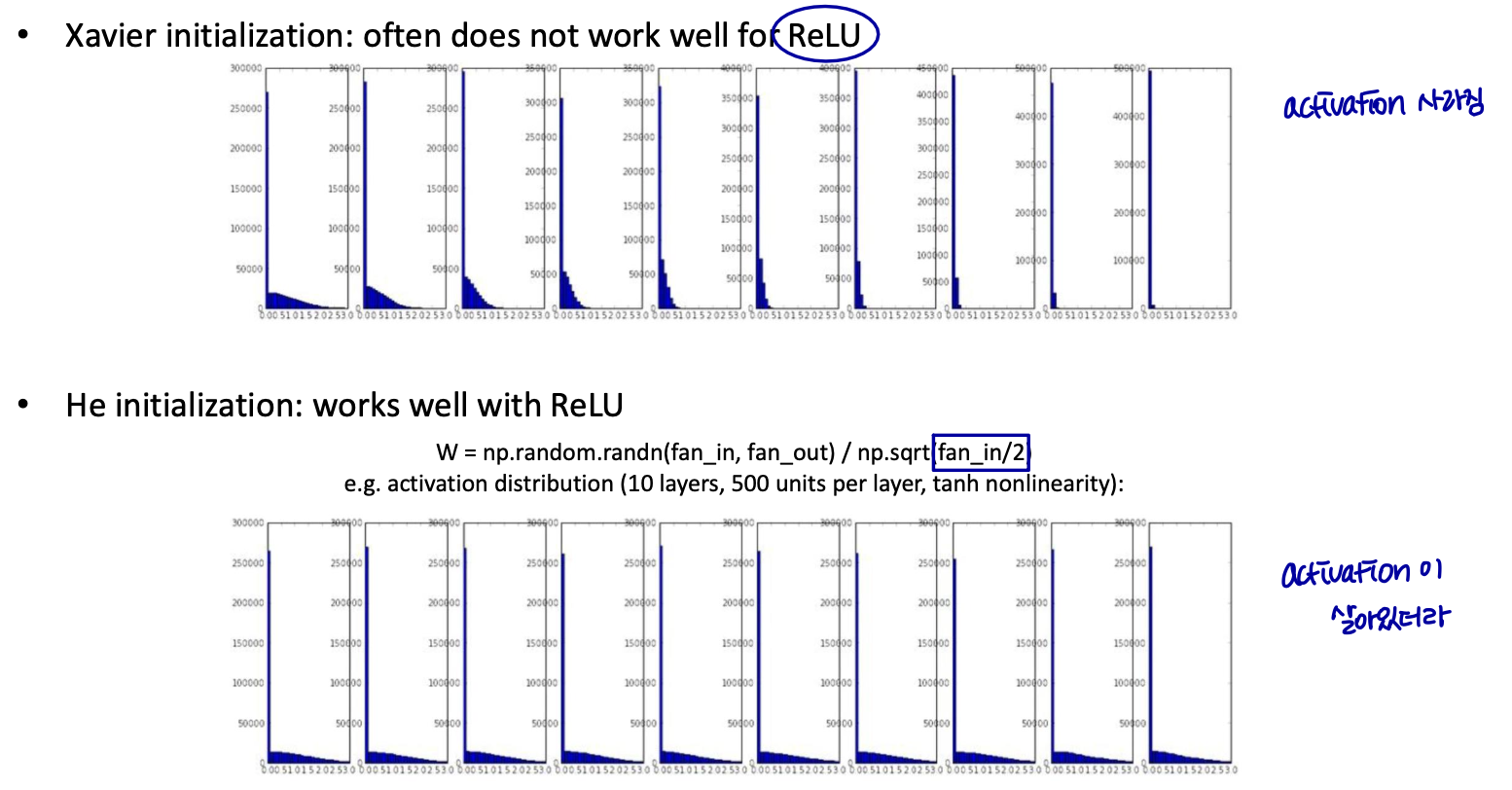
Xavier 초기화
- 시그모이드형 비선형성을 위한 합리적인 선택
Weight initialization (cont.)
Parameters vs hyperparameters
-
Parameters (= model parameters)
- 훈련으로 학습된 것 → 신경망의 가중치와 편향
-
hyperparameters (= meta-parameters, free parameters)
-
훈련 중에 "유동성있는" 것 → learning rate, # layers, # hidden units, minibatch size
-
알고리즘 동작/실행 시간 및 메모리/모델 품질에 영향을 미침
-
정식: 하이퍼파라미터 튜닝 = 모델 선택
-
-
튜닝 우선순위
-
learning rate
-
momentum, # hidden units, minibatch size
-
layers, learning rate decay
-
How to choose hyperparameters
-
두 가지 기본 접근법:
-
수동 튜닝
-
다음을 이해할 필요가 있다.
-
하이퍼파라미터가 수행하는 작업 및
-
ML 모델이 좋은 일반화를 달성하는 방법
-
-
-
자동 선택: 메타 학습, autoML
-
위의 아이디어를 이해할 필요성을 줄인다. (하이퍼파라미터에 대한 이해)
-
하지만 종종 계산 비용이 훨씬 더 많이 든다.
-
Manually tuning hyperparameters
-
기본 전략
-
하이퍼파라미터 값 집합 플러그인
-
가장 좋은 것을 고르기 위해 교차 검증
-
-
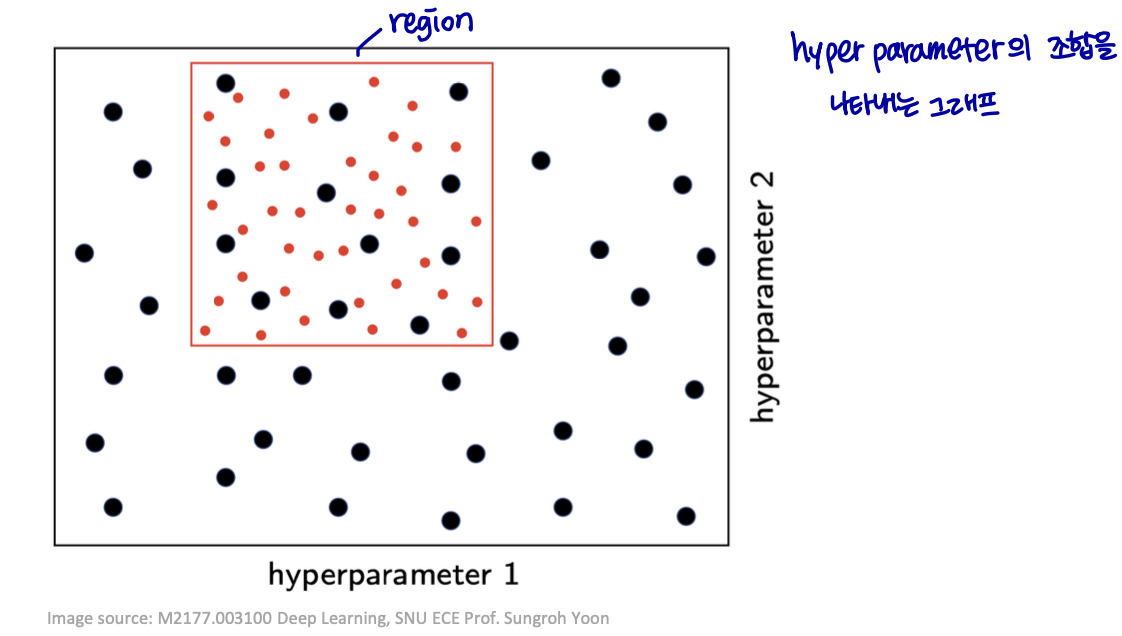
문제점 → 검색 공간: enormous
-
알려진 휴리스틱
-
대략적인 표본 추출 (크게 크게 될 것 같은 것 위주로 골라보는..)
-
그리드 search 대신 랜덤 샘플링
-
표본 추출에 적절한 분포 사용
-
각 휴리스틱에 대해 살펴보자.
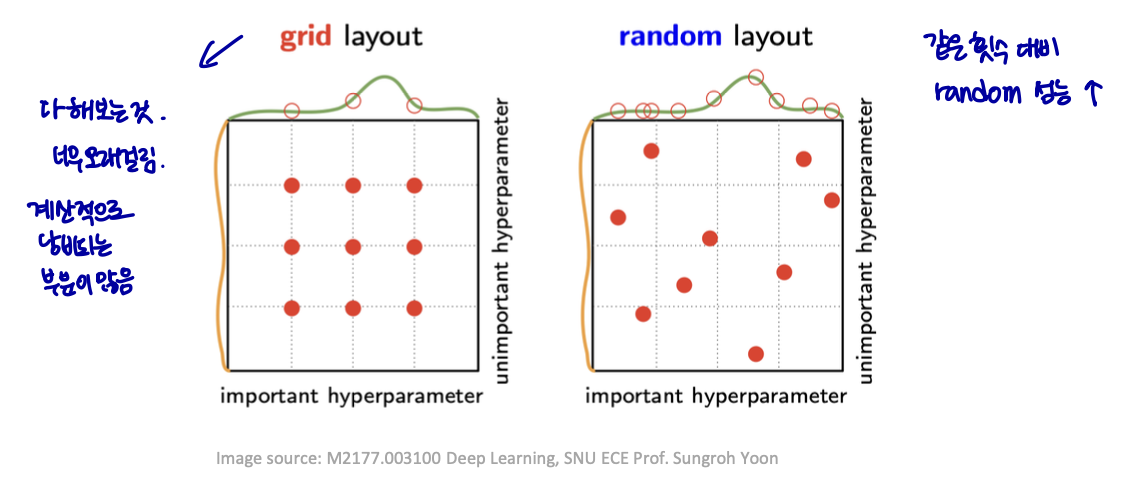
Coarse-to-fine sampling scheme
단계적 교차 검증
-
넓은 영역에서 대략적으로 표본 추출(각각 몇 개의 에포크만 측정)
-
그리고 더 작은 영역에 초점을 맞추고 내부에서 더 촘촘하게 표본을 추출
Random sampling over grid search
그리드 검색
- 계산 낭비 → 낭비되는 양: 비중요 하이퍼 파라미터의 수에서 기하급수적으로 증가
무작위 검색: 보다 풍부한 탐색을 가능하게 함 (실질적으로 더 효율적)
- 거의 모든 시도에서 영향력 있는 모든 하이퍼 파라미터의 고유한 값을 테스트
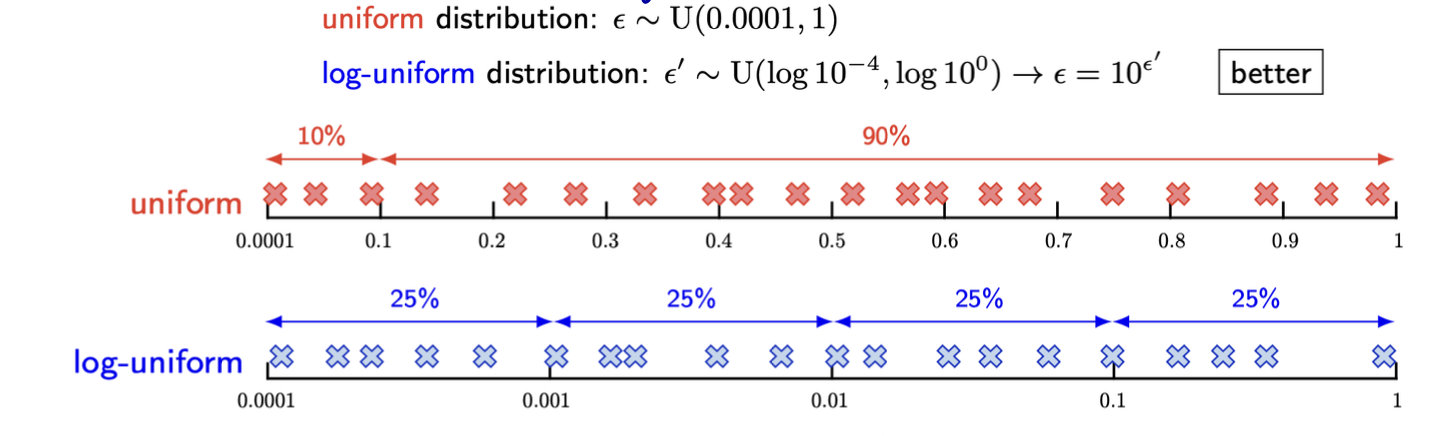
Appropriate distribution for sampling
이진/병렬 하이퍼파라미터 (PMF)
- 베르누이 / 멀티누이 분포로부터의 샘플
양의 실수 값 하이퍼 파라미터
-
로그 척도의 균일한 분포에서 표본 추출
-
[0.0001, 1]의 범위에서 ε를 샘플링하는 두 가지 방법
Recycling models/algorithms
만약 task가 광범위하게 연구된 다른 과제와 유사한 경우
- 해당 작업에서 가장 잘 수행되는 것으로 알려진 모델 / 알고리즘 카피
해당 task에서 훈련된 모델을 카피하고 싶을 수 있음
- e.g.) CNN의 기능을 다른 작업에서 사용
전이 학습 및 영역 적응
-
한 설정에서 학습한 내용 (“source domain”)
-
다른 설정 (“target domain”)
representation 이전의 아이디어를 일반화한다.
- supervised task ↔ unsupervised task
