Lossless-join Decomposition Revisited
-
R = (R1, R2) 인 경우에, 스키마 R에서 모든 가능한 릴레이션 r이 필요하다.
- r = πR1(r) ⋈ πR2(r)
-
만약 다음의 dependencies들 중 최소한 한 개가 F+에 존재한다면,
R의 R1과 R2로의 decompositon(분해)은 lossless join 이다.
- R1 ∩ R2 → R1
- R1 ∩ R2 → R2
-
위의 functional dependencies는 lossless join decomposition을 위한 충분 조건이다;
dependencies는 모든 제약조건이 functional dependencies인 경우에만 필요조건이다.
Example
-
R = (A, B, C)
-
F = {A → B, B → C}
- 두 가지 다른 방식으로 분해 될 수 있다.
-
R1 = (A, B), R2 = (B, C)
-
Lossless-join decomposition: R1 ∩ R2 = {B} and B → BC
-
Dependency preserving
-
-
R2 = (A, B), R2 = (A, C)
-
Lossless-join decomposition: R1 ∩ R2 = {A} and A → AB
-
Not dependency preserving
- (R1 ⋈ R2 의 계산 없이, B → C를 확인할 수 없다.)
-
Lossless-join Decomposition Revisited (cont.)
-
{R1, R2} is a lossless decomposition if
1) R1 ∩ R2 → R1 or
2) R1 ∩ R2 → R2
- 즉, 분해한 두 개의 schema 중 하나가 다른 하나의 super key를 포함하면 연관 관계의 손실이 없다.
Dependency Preservation
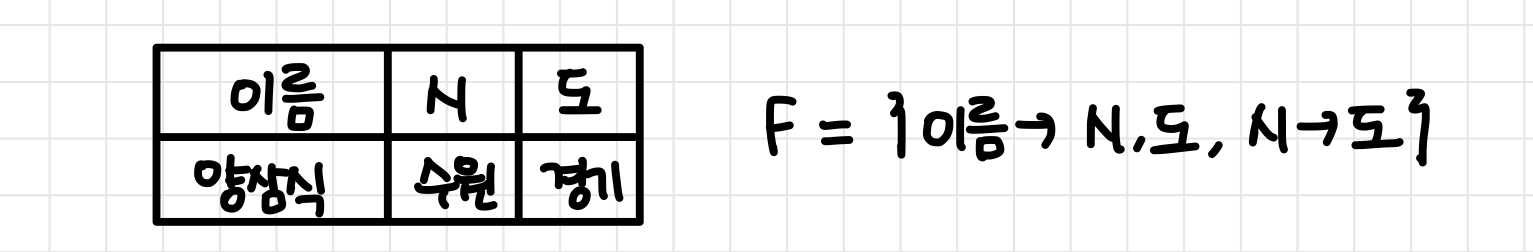
다음과 같은 가정이 있다.
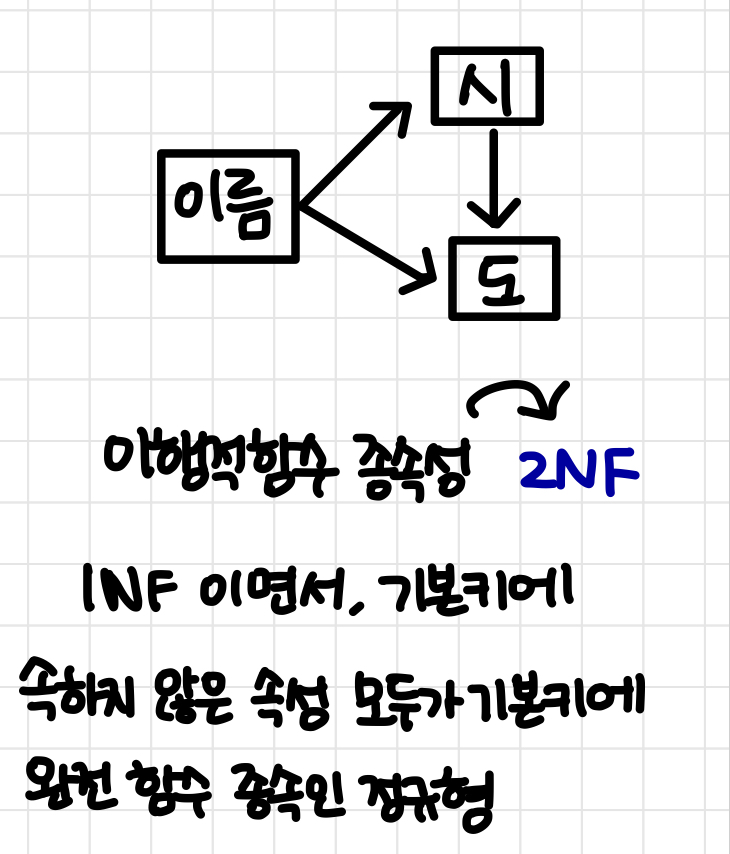
FD를 보면 이행적 함수 종속성이 있음을 알 수 있다. (이름 → 시, 시 → 도 ⇒ 이름 → 도)
1NF 이면서 기본키에 속하지 않은 속성 모두가 기본키에 완전 함수 종속이므로 2NF이다.
- R1 = {이름, 시} R2 = {시, 도} 로 나눈 경우

- R1 = {이름, 시} R2 = {이름, 도} 로 나눈 경우

Dependency Preservation (cont.)
-
정의
-
F: R의 FD의 집합
-
{R1, … , Rn}: R의 decomposition
-
Fi: F에서 Ri로의 제한
⇒ 오직 Ri의 애트리뷰트만을 포함하는 F+에서의 모든 FD의 집합
-
-
정의
-
F’ = F1 U … U Fn 이라고 하자. 만약 F+ = F’+이면,
decomposition은 dependency-preserving 하다. -
즉, 각각의 Ri에서 검증되는 FD 만으로 원래의 FD를 보장
-
-
SQL은 super keys 이외의 functional dependency를 구체화하는 직접적인 방안을 제공하지 않는다.
-
만약 decomposition이 함수 종속성이 보장되지 않는 경우, functional dependency를 위반하는 update가 있는지 확인하려면, 비용이 드는 join 연산을 필요로 할 수 있다.
Goal for decomposition
-
functional dependency F의 집합과 함께 relation schema R을 우리가 원하는 R1, R2, … , Rn으로 decompose 할 때의 목표
1. Lossless
2. No redundancy
3. Dependency preservation
보완할 부분이 있으면 댓글 남겨주세요. :)
