데이터베이스
1.Relational Database Design

Database Design어떤 테이블을 만들 것인가?각 테이블은 어떤 attribute를 가지게 할 것인가?목표: 불필요한 중복(redundancy)없이 필요한 정보를 모두 표현(저장)할 수 있는 schema. ⇒ 어떤 attribute를 갖는 어떤 table을 둘
2.Functional Dependency (1)

다음에 대한 이론을 고안하다.특정 릴레이션 R이 “좋은” 형태인지아닌지 결정하다.릴레이션 R이 “좋은”형태가 아닌 경우, 이것을 {R1, R2, … , Rn}의 릴레이션 집합으로 분해한다.이때, 각각의 릴레이션이 좋은 형태이다.decomposition이 lossless
3.Functional Dependency (2)
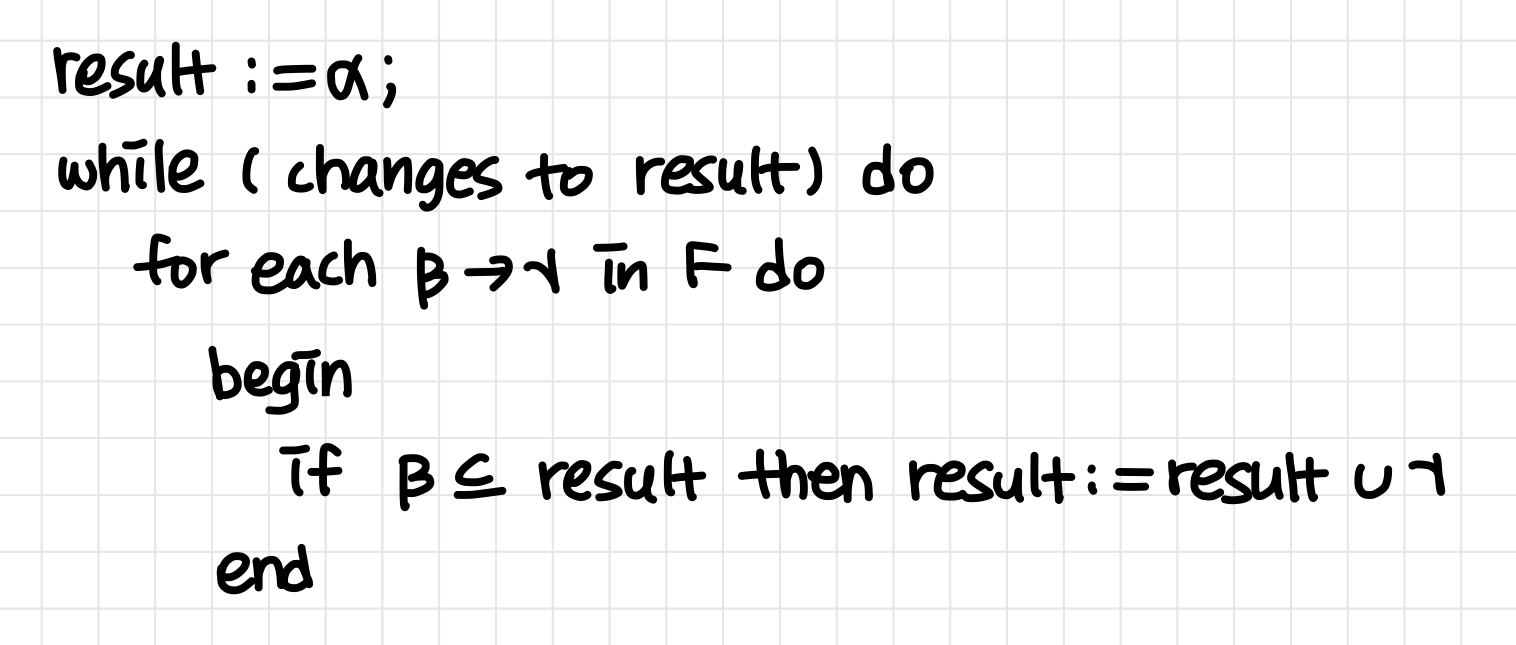
attribute α 의 집합이 주어졌을 때, F 아래 α를 함수적으로 결정되는 모든 attribute의 집합을 “closure of α under F” 라고 부른다.주어진 애트리뷰트 집합에 의해 결정되는 모든 애트리뷰트의 집합용도Super Key 테스트FD 테스트F+
4.Functional Dependency (3)
R = (R1, R2) 인 경우에, 스키마 R에서 모든 가능한 릴레이션 r이 필요하다.r = πR1(r) ⋈ πR2(r)만약 다음의 dependencies들 중 최소한 한 개가 F+에 존재한다면, R의 R1과 R2로의 decompositon(분해)은 lossless
5.Normal Form
정규화의 기본 목표는 테이블 간에 중복된 데이터를 허용하지 않는다는 것이다. 중복된 데이터를 허용하지 않음으로써 무결성(integrity)를 유지할 수 있으며, DB의 저장 용량 역시 줄일 수 있다.이러한 테이블을 분해하는 정규화 단계가 정의되어 있는데, 테이블을 어떻
6.BCNF & 3NF

만약 각각의 F+의 FD α → β 에 대해 (α ⊆ R, β ⊆ R) 다음 조건을 최소한 한개 만족한다면 relation schema R을 BCNF라고 한다.α → β is trivial (i.e., β ⊆ α )α가 R의 super keyTrivial 하지 않은 모
7.Indexing and Hashing
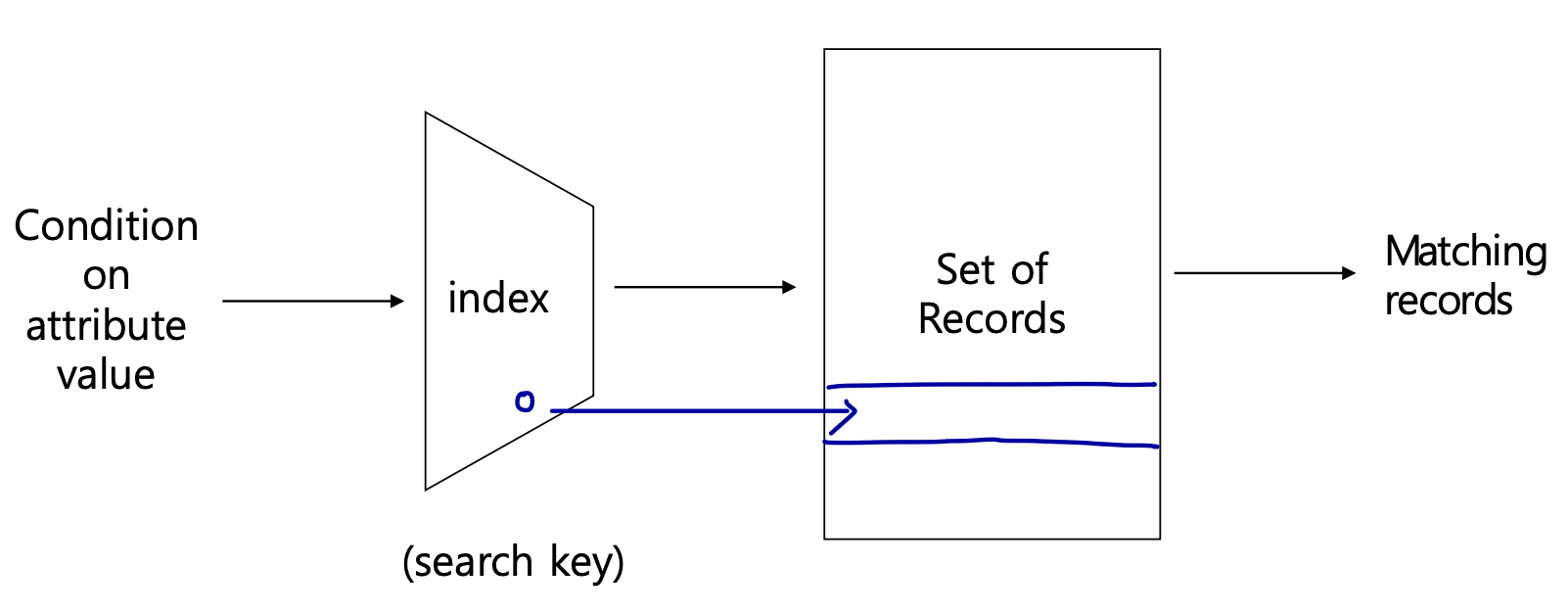
인덱스는 데이터에 효율적으로 접근할 수 있도록 하는 데이터 구조이다. 스크린샷 2023-05-07 오후 4.49.25.pngCraete an index create index on () e.g.) create index inst-index on in
8.Query Processing (1)
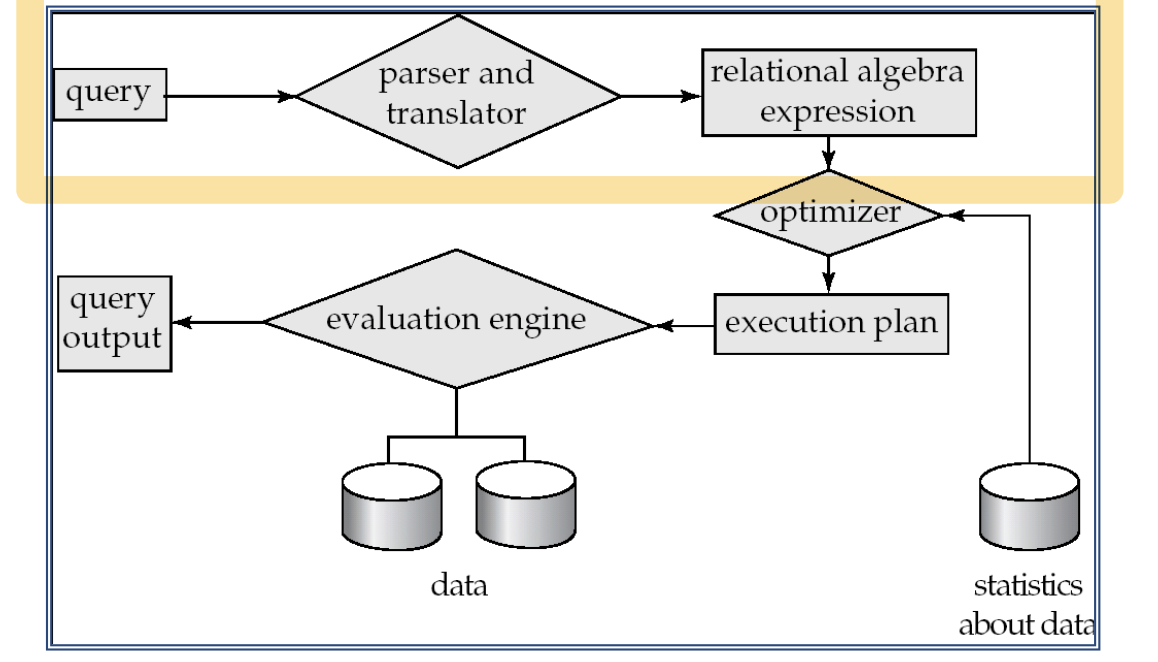
Selection: σHorizontal subsetProjection: πVertical subsetJoin: ⋈Two tables joined on a certain conditionParsing and translationOptimizationEvaluationP
9.Query Processing (2)
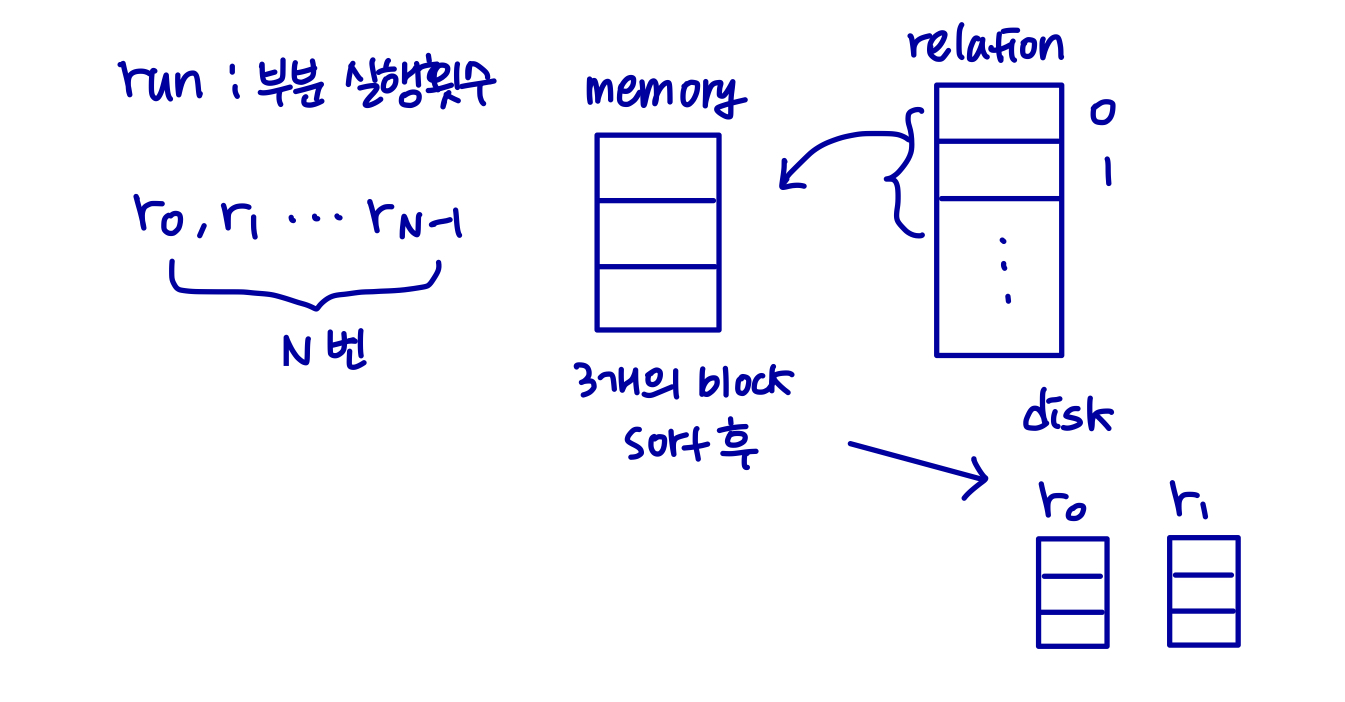
정렬은 중요하다.SQL 쿼리는 정렬할 출력을 지정한다.입력 relation을 먼저 정렬하면 join을 효율적으로 구현할 수 있다.relation에 대한 인덱스를 구축한 다음 인덱스를 사용하여 정렬된 순서로 relation을 읽을 수 있다.relation을 논리적으로만
10.Query Processing(3)
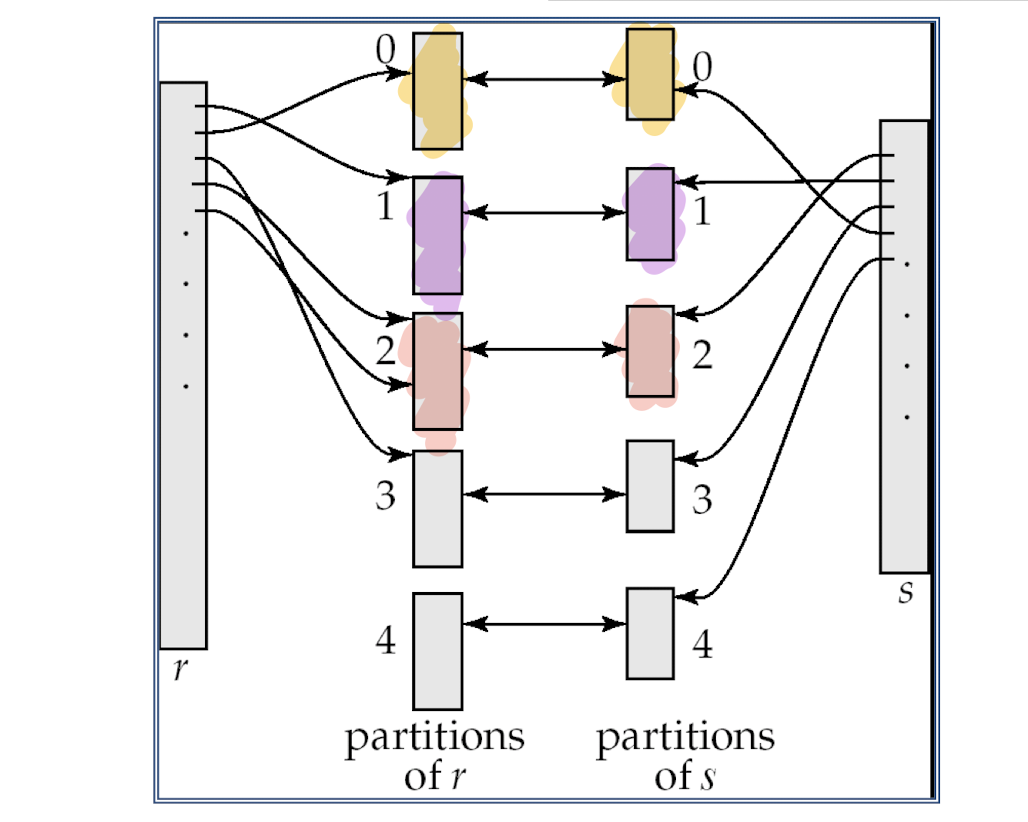
해시 함수 h는 두 relation의 튜플을 분할하는 데 사용된다.natural join과 equi-join에 적용 가능하다.h는 joinAttrs 값을 {0,1, … n}에 매핑한다. 여기서 joinAttrs는 natural join에 사용되는 r 과 s의 공통 at
11.Query Optimization
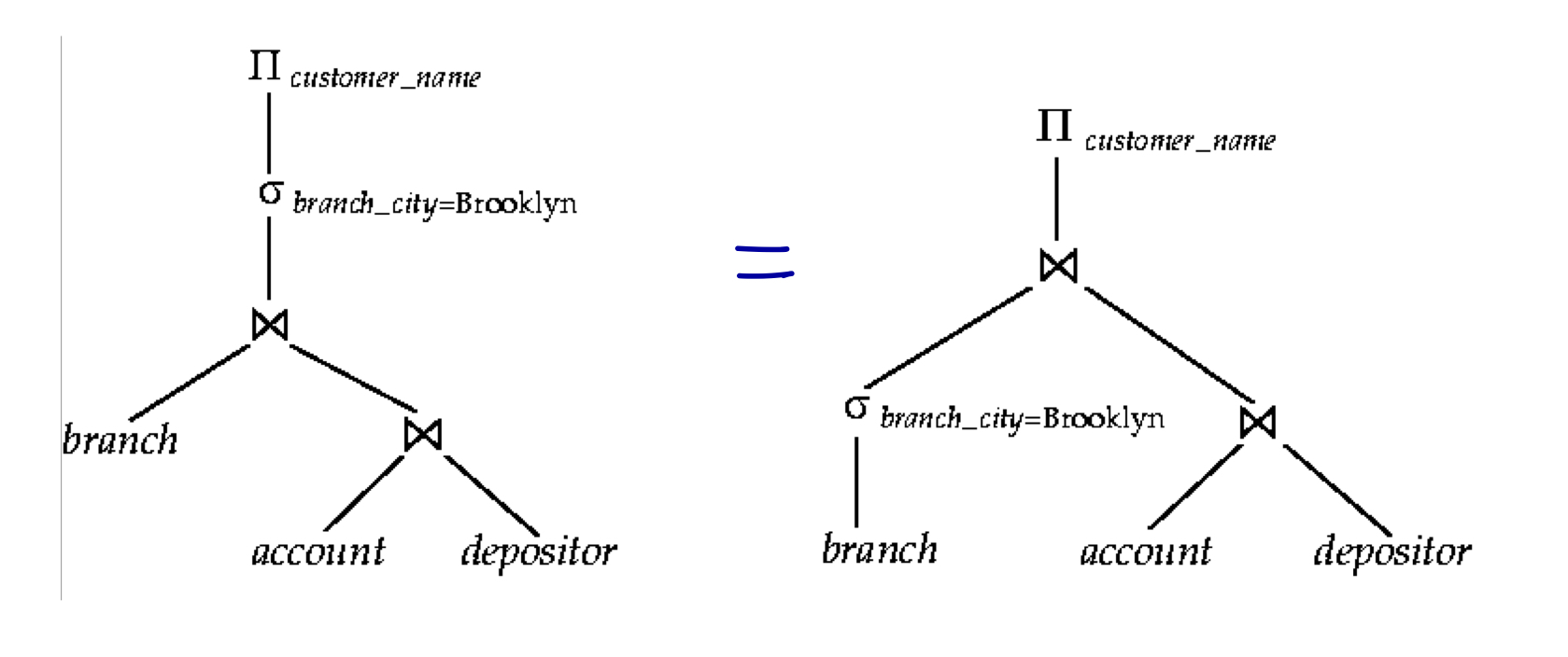
주어진 쿼리를 평가하는 다른 방법동등한 표현작업마다 다른 알고리즘평가 계획 (실행 계획)은 각 작업에서 사용되는 알고리즘과 작업 실행이 조정되는 방식을 정확히 정의한다.쿼리에 대한 평가 계획 간의 비용 차이가 엄청 날 수 있다.e.g.) 경우에 따라 seconds vs
12.Query Optimization (2)
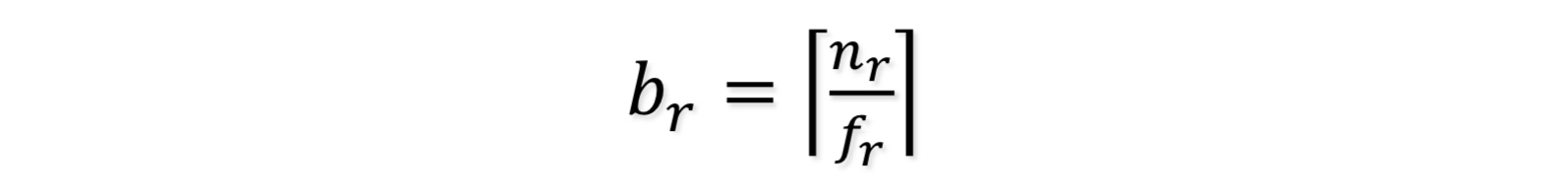
$n_r$: relation r의 튜플 수$b_r$: r의 튜플을 포함하는 블록 수$l_r$: r의 튜플의 사이즈$f_r$: r의 차단 인자 - 즉, 하나의 블록에 맞는 r의 튜플의 개수이다.V(A, r): r에 나타나는 속성 A의 개별 값의 수; $π\_A(r)$ 의