Index
Index?
인덱스는 데이터에 효율적으로 접근할 수 있도록 하는 데이터 구조이다.
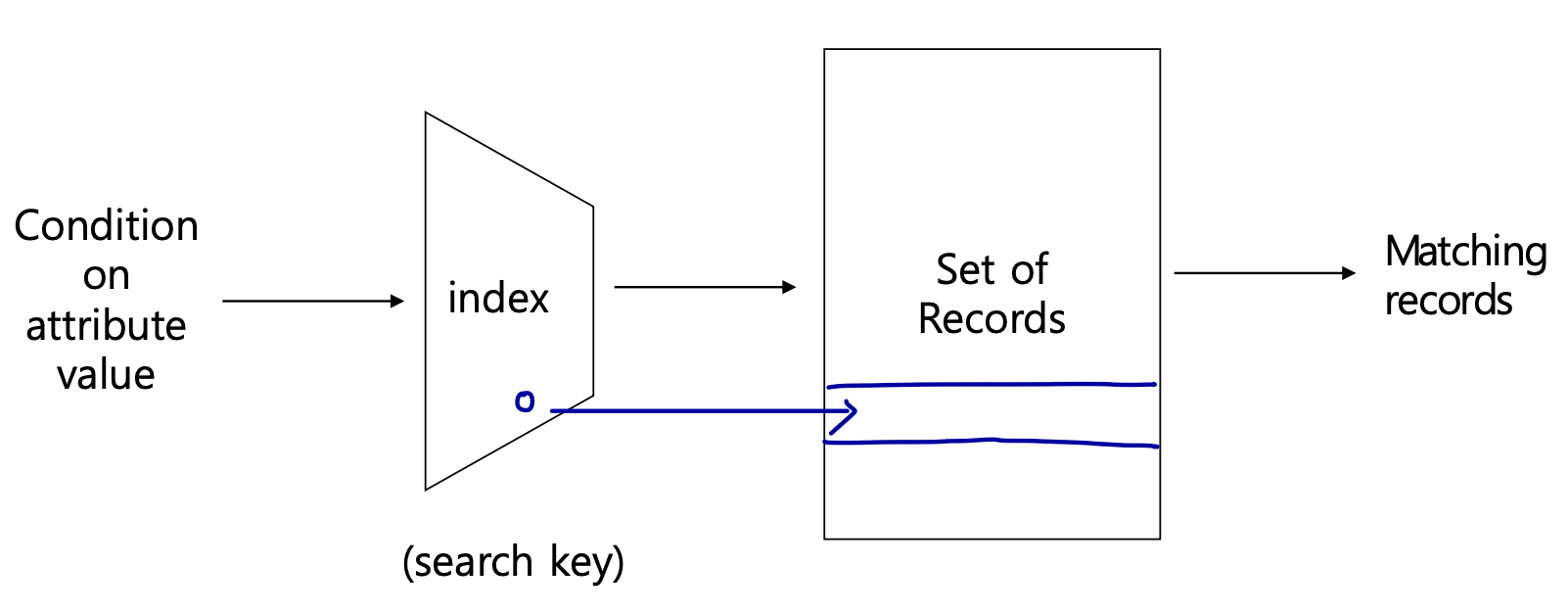
Index Definition in SQL
-
Craete an index
create index on ()
e.g.) create index inst-index on instructor(instructor_name)
PK인 경우, DBMS에서 index를 자동 생성한다.
-
To drop an index
drop index
데이터의 insertion/deletion이 있으면 index도 update 됨 → 성능 저하
B+-Tree Index
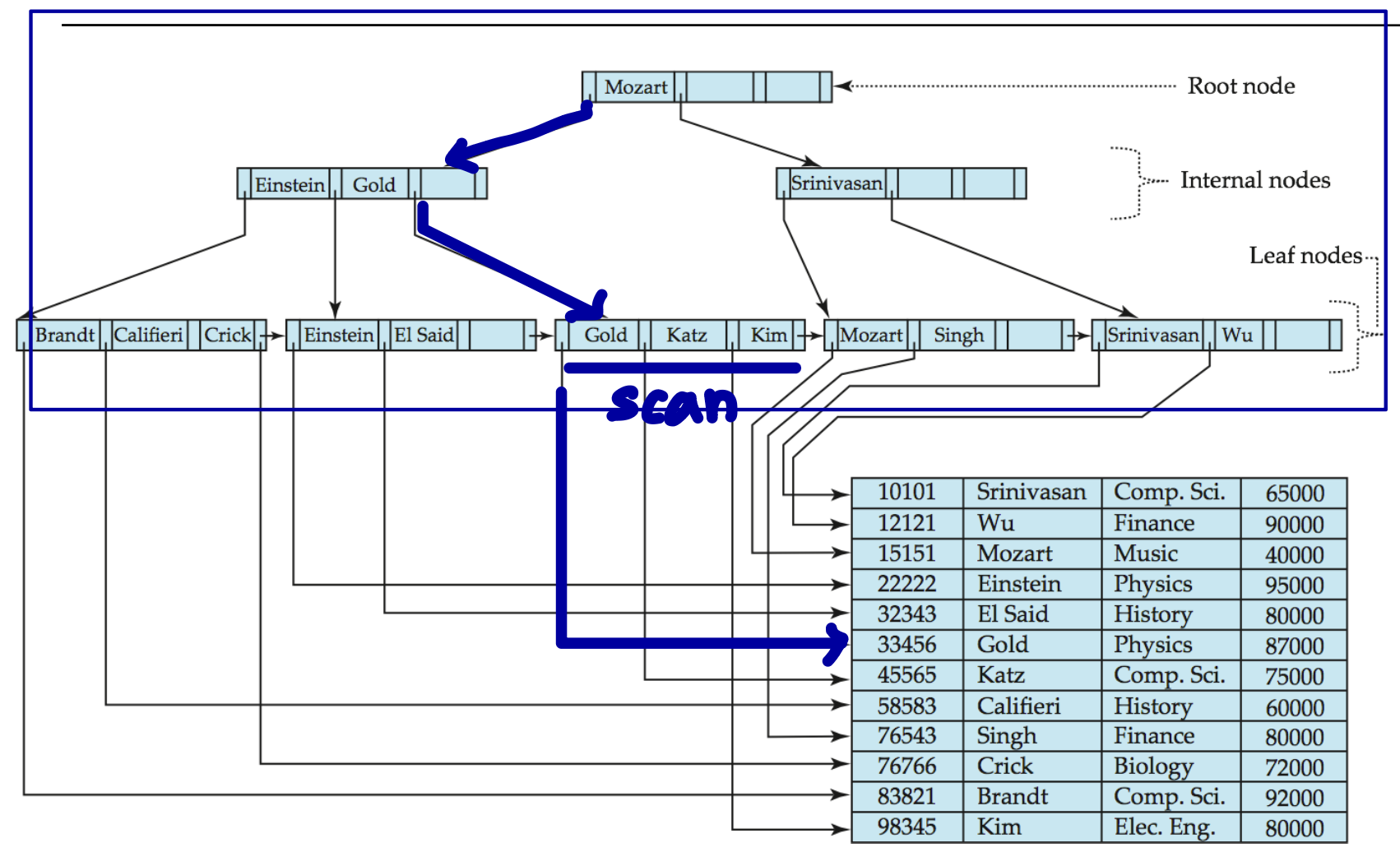
Example Query
Select ID, instructor_name, dept_name, salary
From Instructor
Where instructor_name =”Gold”;
- Instructor_name에 설정되어 있는 index를 활용하여 query를 execute할 수 있음
Hashing
Static Hashing
-
bucket은 하나 이상의 레코드를 포함하는 저장단위이다. (bucket은 일반적으로 disk block이다.)
-
해시 파일 구성에서 해시 함수를 사용하여 검색 키 값에서 직접 레코드의 버킷을 얻는다.
-
해시 함수 h는 모든 검색 키 값 집합 k에서 모든 버킷 주소 집합 B까지의 함수이다.
- 검색 키 Ki로 레코드를 삽입하기 위해 해당 레코드에 대한 버킷 주소를 제공하는 h(Ki)를 계산한다.
-
해시 함수는 엑세스, 삽입 및 삭제를 위해 레코드를 찾는 데 사용된다.
Static Hashing (Cont.)
-
검색 키 값이 다른 레코드는 동일한 버킷에 매핑될 수 있다. 따라서 레코드를 찾으려면 버킷 전체를 순차적으로 검색해야 한다.
-
해시 함수는 키 값에서 임의로 다른 위치를 반환한다.
(e.g. Smith와 Smythe는 다른 페이지에 있을 수 있음 → 유사하다고 비슷한 위치에 있지 않다.)
-
포인트 쿼리에 적합: 오버플로 체인이 없는 경우 하나의 디스크 엑세스로 수행된다.
-
모든 데이터를 스캔하는 쿼리는 성능이 좋지 않다.
Basic Concepts of Hashing
- 해시 인덱스는 해시 함수라고 하는 의사 난수화 함수를 기반으로 키-값 쌍을 저장한다.
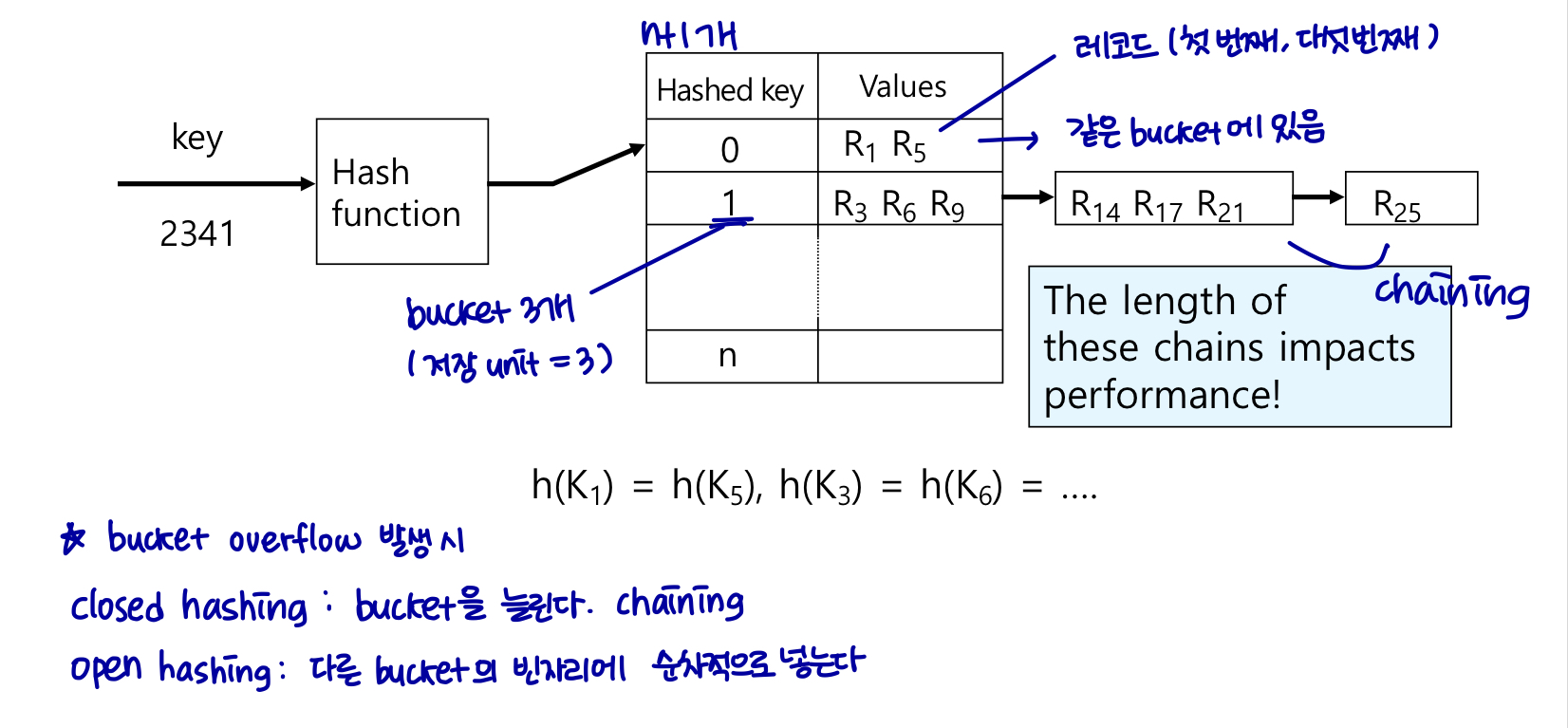
- h(K1) = h(K5) : 검색 키 K1, K5 의 레코드에 대한 버킷 주소가 같다.
Example of Hash File Organization
dept_name을 키로 사용하여 instructor 파일의 해시 파일 구성
-
10개의 버킷이 있다.
-
i 번째 문자의 이진 표현은 정수 i로 가정한다.
-
해시 함수는 모듈로 10 문자의 이진 표현 합계를 반환한다.
-
e.g. h(Music)=1, h(History)=2, h(Physics)=3, h(Elec. Eng.)=3
-
우연히 같은 학과가 아님에도 같은 bucket에 들어갈 수 있다.
-
Example of Hash File Organization
dept_name을 키로 사용하는 instructor 파일의 해시 파일 구성
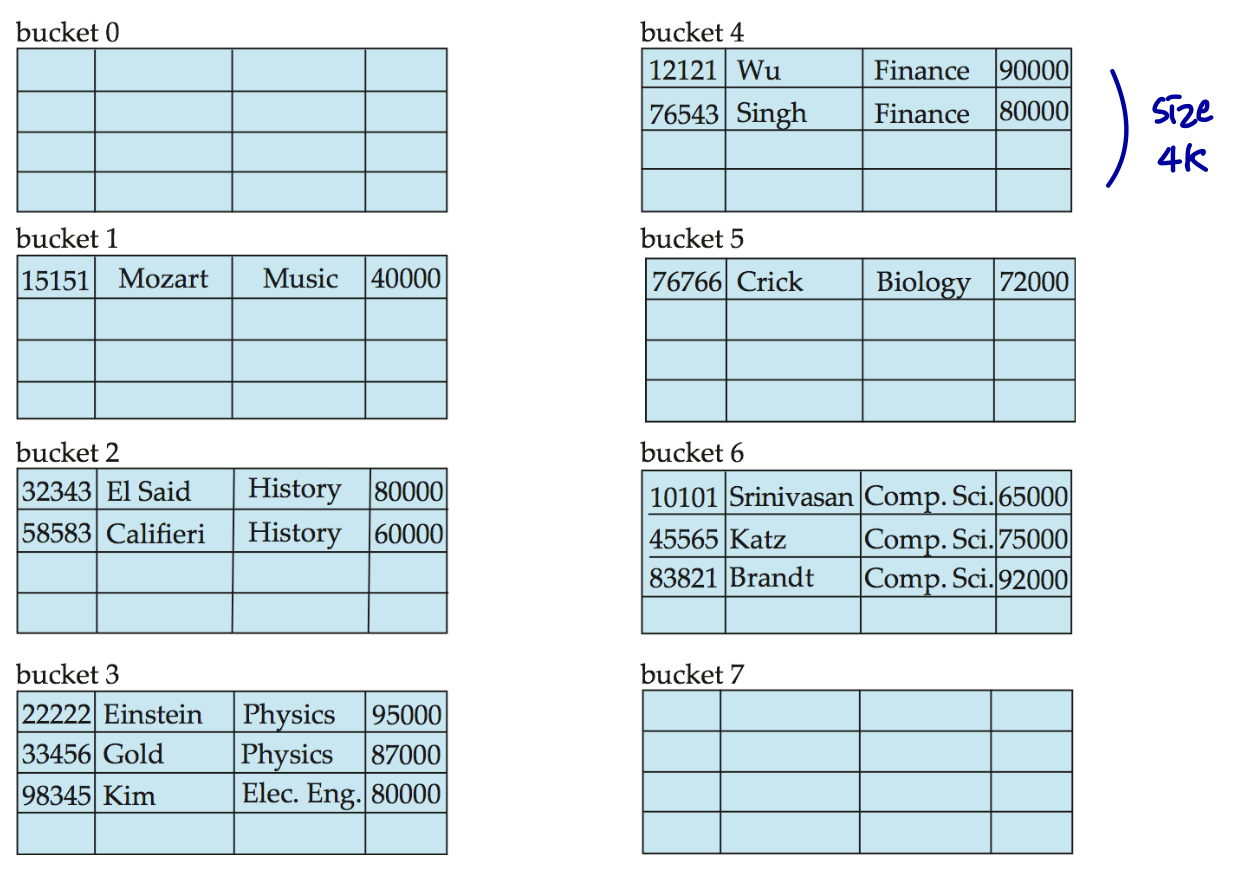
- 한 학과에만 교수님이 많을 경우 그 bucket에서만 overflow가 발생할 수 있다.
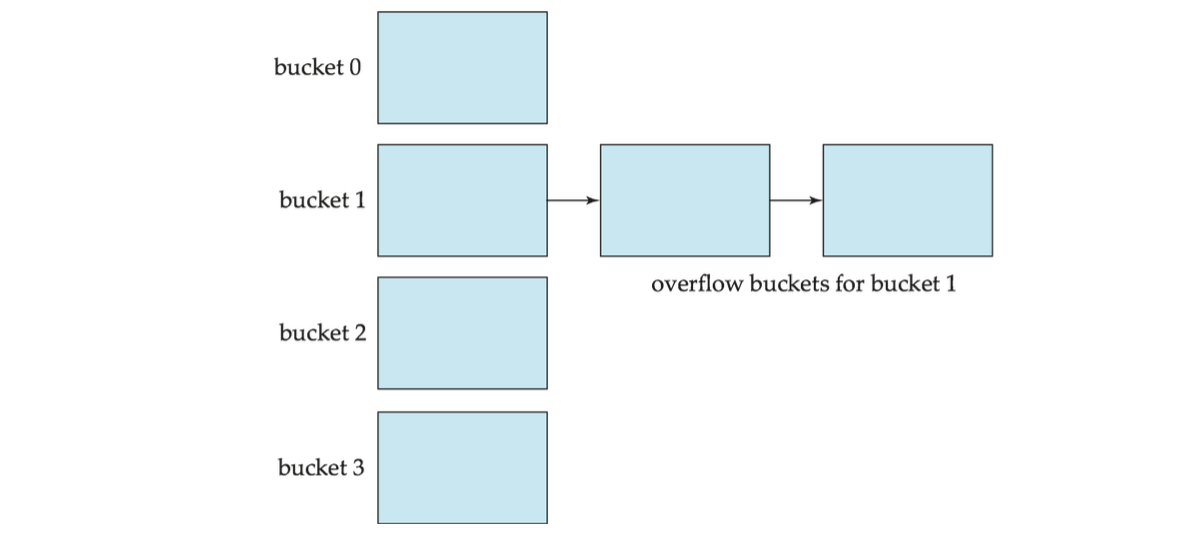
Handling of Bucket Overflows
-
bucket 오버플로우는 해당 사유들로 인해 일어날 수 있다.
-
불충분한 buckets
-
레코드 분포의 왜곡. 이는 다음 두 가지 이유로 발생할 수 있다.
-
여러 레코드가 동일한 검색 키를 가짐
-
선택된 해시 함수는 키 값의 불균일한 분포를 생성한다. (특정 bucket에만 유독 많이 나오는 경우)
-
-
-
버킷 오버플로 가능성을 줄일 수는 있지만 제거할 수는 없다. 이는 오버플로 버킷을 사용하여 처리된다.
Handling of Bucket Overflows (Cont.)
-
오버플로우 체이닝 - 주어진 버킷의 오버플로 버킷은 링크드 리스트에서 함께 연결된다.
-
위의 체계를 closed hasing이라 부른다.
-
오버플로 버킷을 사용하지 않는 대안으로 open hasing이 있다. 하지만 이는 데이터베이스 애플리케이션에 적합하지 않다.
-
Open hasing: bucket이 full이면 다른 bucket에 insert (e.g.. linearly)
-
Hash Indices
해싱은 파일 구성뿐만 아니라 인덱스 구조 생성에도 사용할 수 있다.

해시 인덱스는 연관된 레코드 포인터와 함께 검색 키를 해시 파일 구조로 구성한다.
- 일반적으로 여러 포인터가 각 키와 연결될 수 있다.
엄밀히 말하면 해시 인덱스는 항상 보조 인덱스이다.
-
파일 자체가 해싱을 사용하여 구성된 경우 동일한 검색 키를 사용하는 별도의 기본 해시 인덱스가 필요하지 않다.
-
그러나 해시 인덱스라는 용어는 보조 인덱스 구조와 해시로 구성된 파일을 모두 지칭하는데 사용한다.
- prmary key index = primary index
Example of Hash Index
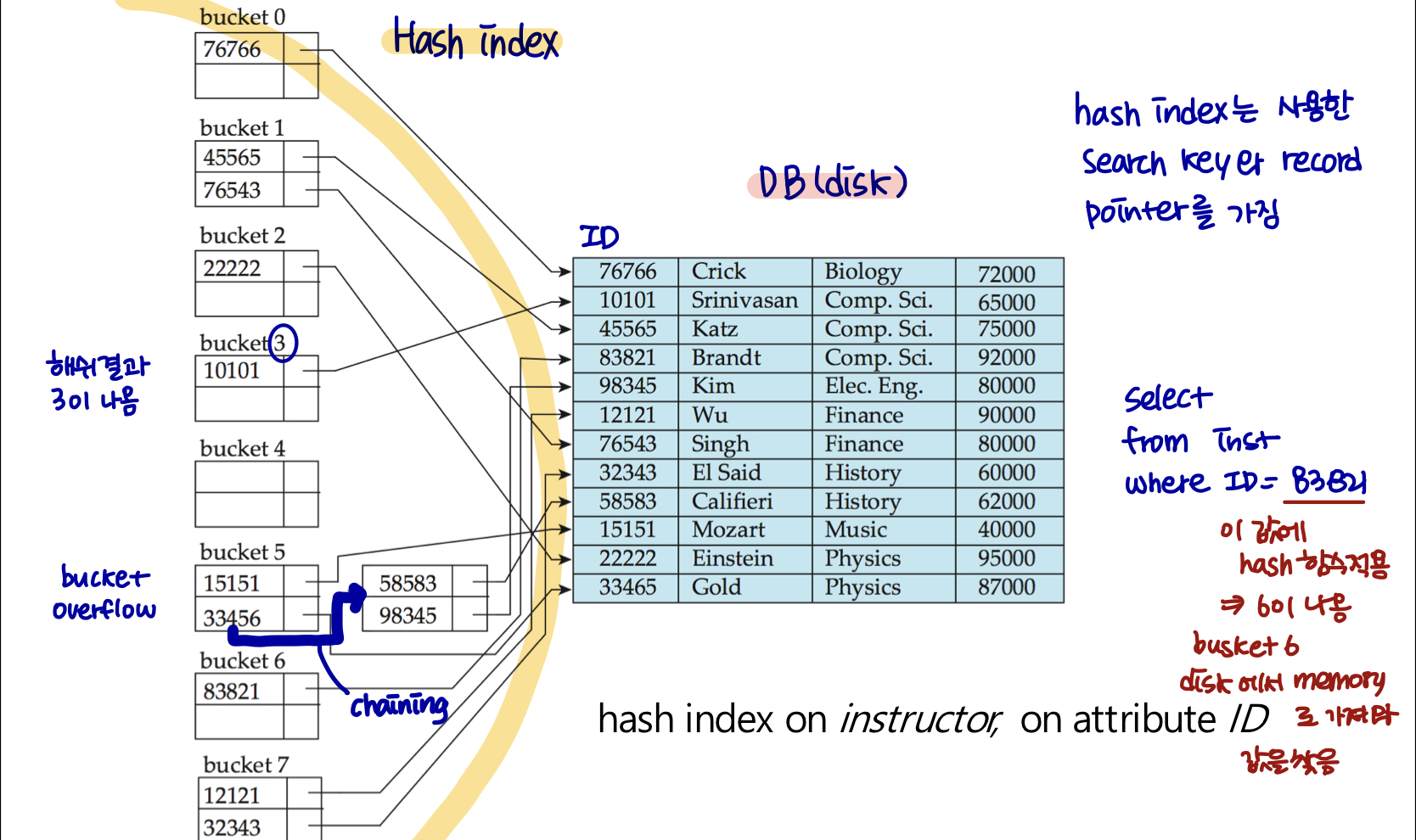
Select ID, instructor_name, dept_name, salary
From Instructor
Where ID = 83821;
라는 SQL 문이 있을 때 hash index가 작동되는 방식을 알아보자.
먼저 search key 값인 83821에 해쉬 함수를 적용한다. 그 값이 6이 나오면 bucket 6 주소로 이동해 해당 search key 인덱스에서의 record pointer를 따라 disk(DB)로 이동한다.
그 후 DB에서 값 들을 찾은 후 memory로 가져와 값을 출력한다.
Deficiencies of Static Hashing
시스템을 구현할 때 해시 함수를 선택해야 한다.
-
인덱싱되는 파일이 커지거나 줄어들면 나중에 쉽게 변경할 수 없다.
-
Big → 공간 낭비
-
Small → 많은 다른 검색 키 값들이 동일한 버킷에 있다. → 버킷 오버플로
파일이 커지면 성능이 저하된다!
버킷 수와 해시 함수를 동적으로 변경할 수 있을까?
- 정적 해싱의 문제점을 살펴본 후, 동적 해싱에 대해 살펴보자!
Deficiencies of Static Hashing (cont.)
정적 해싱에서 함수 h는 검색키 값을 버킷 주소의 고정 집합 B에 매핑한다. 데이터베이스는 시간이 지남에 따라 커지거나 줄어든다.
-
초기 버킷 수가 너무 적고 파일이 커지면 오버플로가 너무 많아 성능이 저하된다.
-
예상되는 성장을 위해 공간이 할당된 경우 초기에 상당한 양의 공간이 낭비된다. (버킷이 부족하게 채워짐)
-
데이터베이스가 축소되면 다시 공간이 낭비된다.
한 가지 해결책: 새로운 해시 함수로 파일을 주기적으로 재구성
- 높은 비용, 정상 작동 방해
더 나은 해결책: 버킷 수를 동적으로 수정
Dynamic Hashing
-
크기가 커지고 축소되는 데이터베이스에 적합
-
해시 함수를 동적으로 수정할 수 있다.
-
확장 가능한 해싱 - 동적 해싱의 한 형태
-
데이터베이스가 확장 및 축소됨에 따라 버킷을 분할 및 병합하여 데이터베이스 크기의 변화에 대처
-
공간 효율성은 유지된다.
-
재구성은 한 번에 하나의 버킷에서만 수행되기 때문에 결과적인 성능 오버헤드는 허용 가능할 정도로 낮다. (지협적으로 일어나기 때문에 성능 오버헤드 x)
-
-
Dynamic hasing = Extendable hasing . 통용
Extendable Hashing
-
넓은 범위에 걸쳐 값을 생성하는 해시 함수를 선택한다. 일반적으로 b=32인 b비트 정수이다.
- 2^32 = 4,294,967,296 (← bucket의 수. maximum)
-
각 해시 값에 대한 버킷을 생성하지 말고 요청 시 레코드가 파일에 삽입될 때 버킷을 생성해야 한다.
- 언제든지 해시 함수의 prefix만을 사용하여 버킷 주소 테이블(BAT)로 인덱싱할 수 있다.
-
prefix의 길이는 i 비트, 0 ≤ i ≤ 32 로 설정한다.
-
버킷 주소 테이블(BAT)의 사이즈 = 2^i. (i=0으로 초기설정)
-
데이터베이스의 확장 및 축소에 따라 i의 값이 커지거나 작아진다.
-
-
버킷 주소 테이블의 여러 항목이 버킷을 가리킬 수 있다. (즉, 여러 개의 항목이 하나의 버킷을 가리킬 수 있다.)
-
그러므로 실제 버킷의 수는 2^i 보다 작다.
-
버킷 수는 버킷 병합 및 분할로 인해 동적으로 변경된다.
-
-
버킷 j를 가리키는 버킷 주소 테이블(BAT) 항목의 수는 2^(i-ij) 이다.
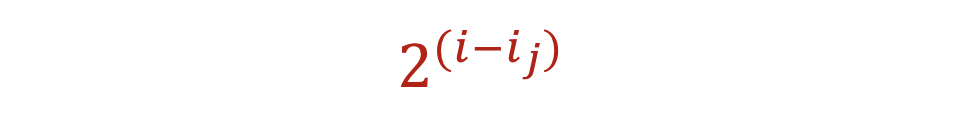
그림과 함께 더 살펴보자.
General Extendable Hash Structure
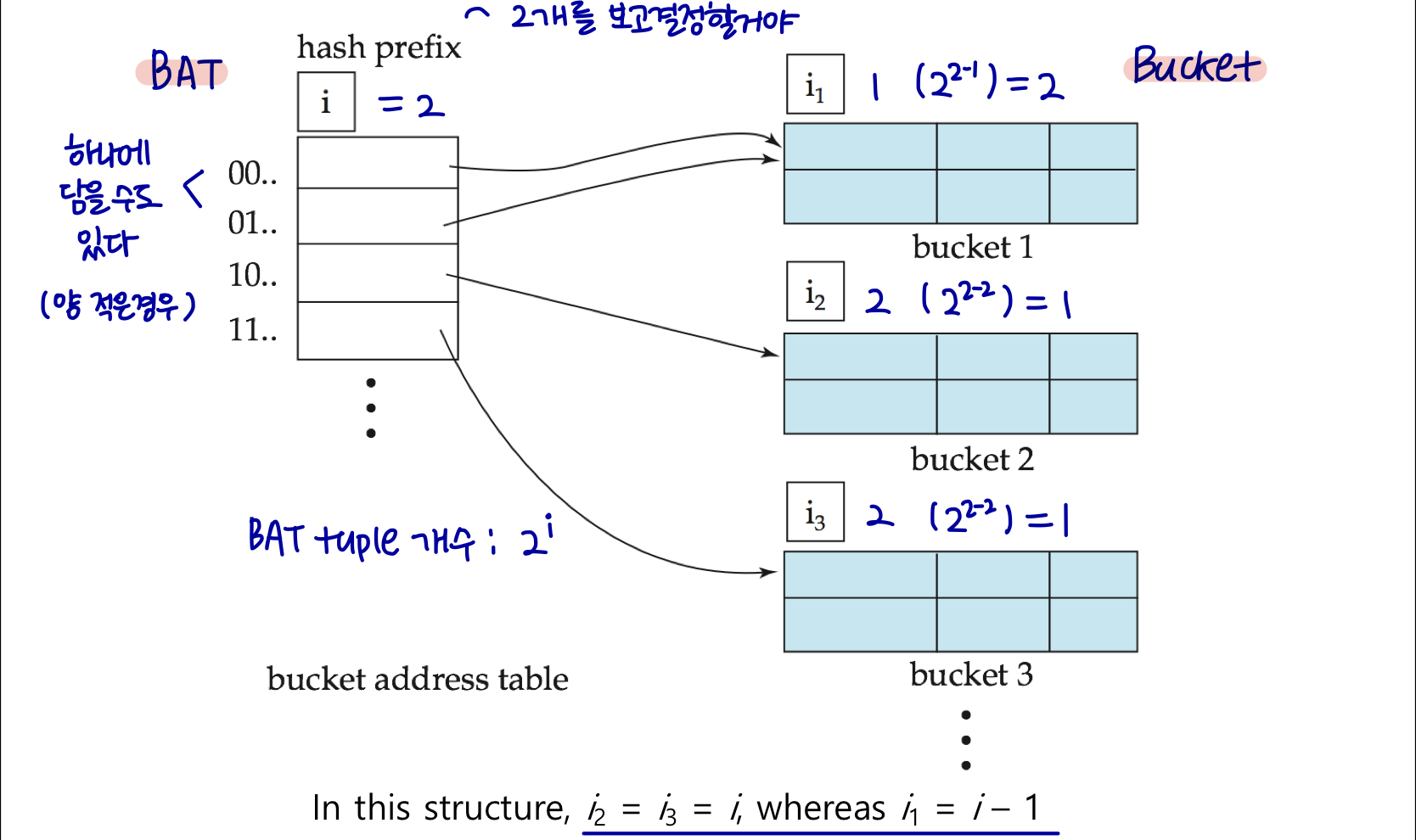
Insertion Algorithm Sketch

만약 bucket에 공간이 있으면 bucket에 레코드를 삽입한다.
만약 bucket이 가득 차 있으면 bucket 분할 및 레코드 재분배
-
Spliting
-
만약 i = ij 라면, BAT 사이즈 증가 (bucket address table)
- i를 증가시켜 BAT의 크기를 두 배로 늘림 (4개 수용 → 8개 수용 .. hash prefix 증가)
- 새 버킷을 할당하고 버킷 j에서 검색 레코드를 다시 해시한다.
-
만약 i > ij 라면, BAT의 크기를 늘리지 않고 버킷을 분할한다.
- 새 버킷을 할당하고 BAT에서 포인터를 조정한다.
- 버킷 j의 각 레코드를 다시 해시한다.
-
Insertion Example
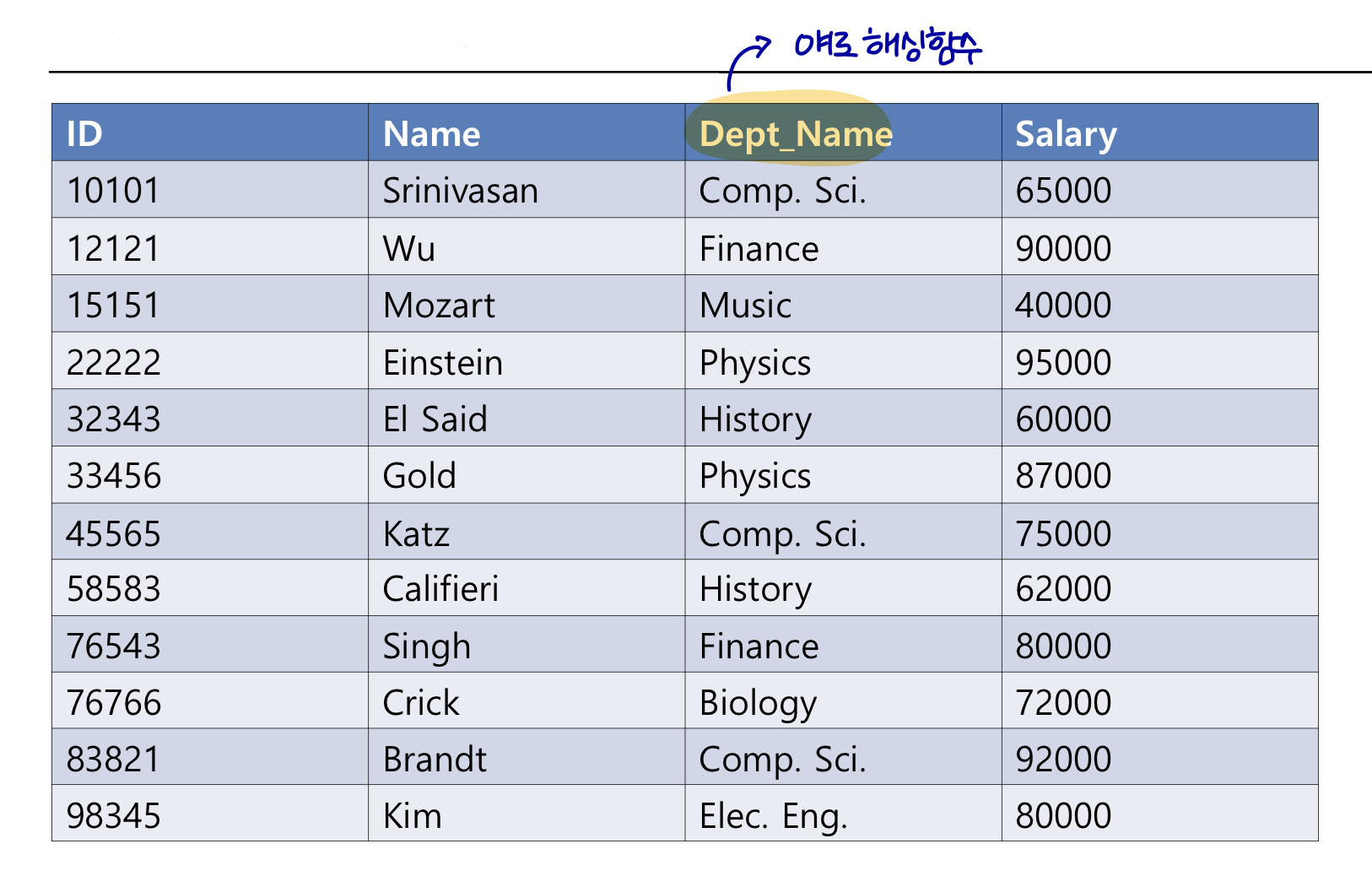
각 레코드에 관해 dept_name으로 해싱함수를 적용한 결과는 다음과 같다.

우선 hash prefix가 0인 상태에서 bucket에 레코드를 삽입한다.
(위의 테이블 순으로, Srinivasan, Wu, Mozart)
bucket이 차면 hash prefix가 증가하고 re-hash한다.
prefix가 0 또는 1로 시작하는 레코드를 나누어 두 개의 버켓에 담는다.
bucket1이 꽉 찼고, i = ij 이므로 prefix를 증가시켜 BAT의 사이즈를 증가시킨다.
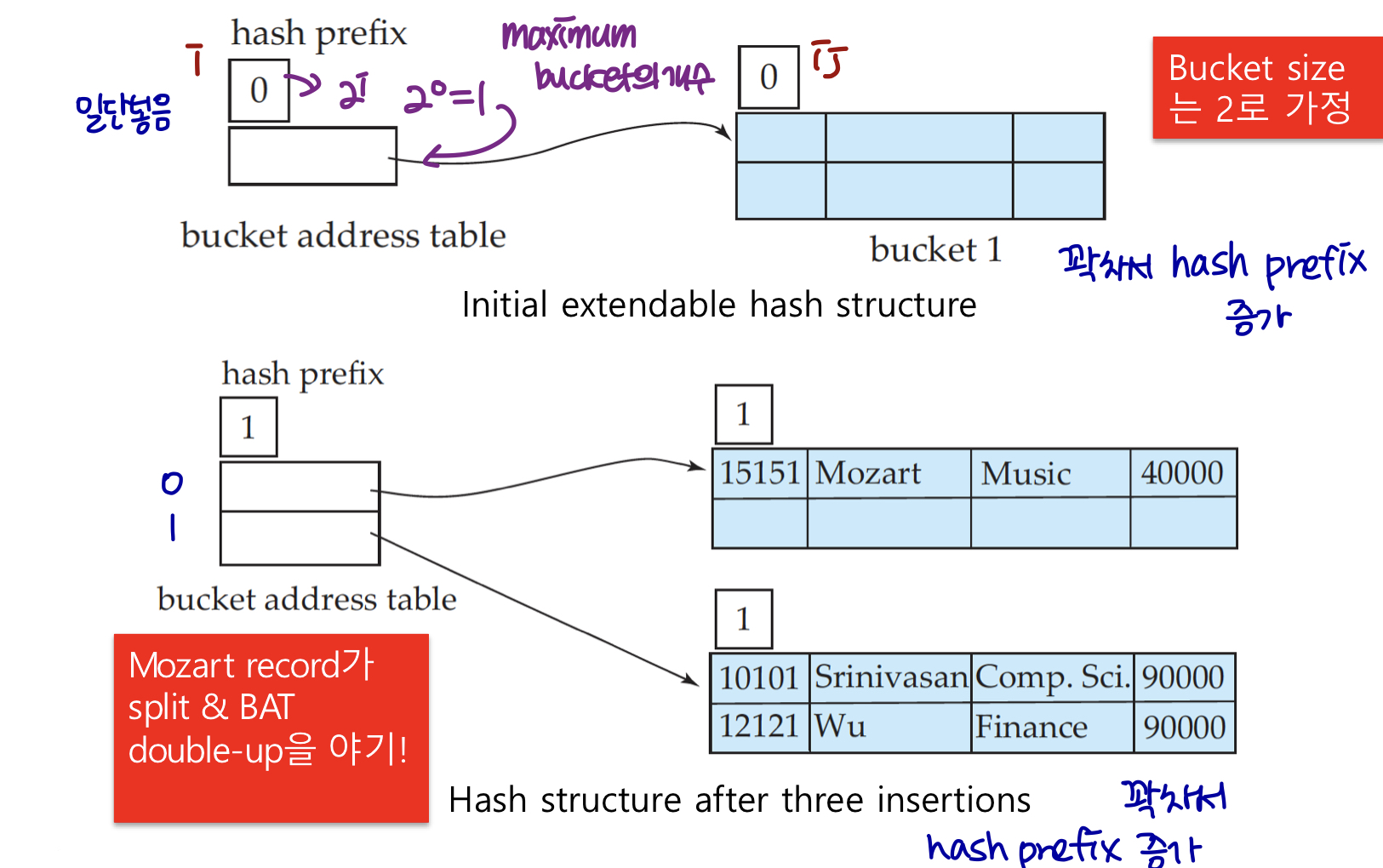
bucket2가 꽉 찼고, i = ij 이므로 prefix를 증가시켜 BAT의 사이즈를 증가시킨다.
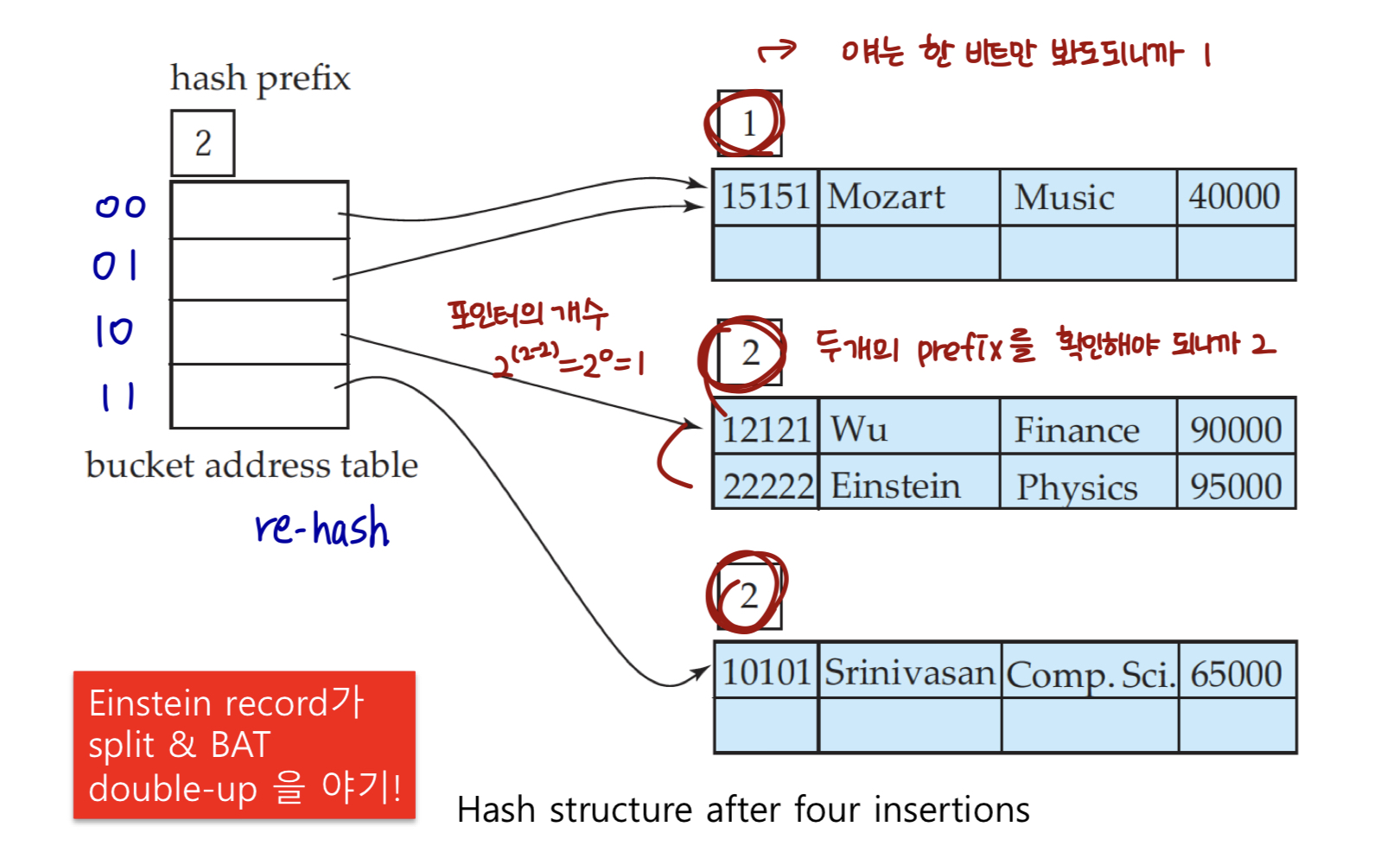
bucket2에서 레코드의 삽입으로 인해 버킷이 꽉 찼다. i = ij 이지만 BAT는 유지한다. (아무리 BAT를 늘린다고 해도 같은 과니까 같은 bucket에 넣는다.)
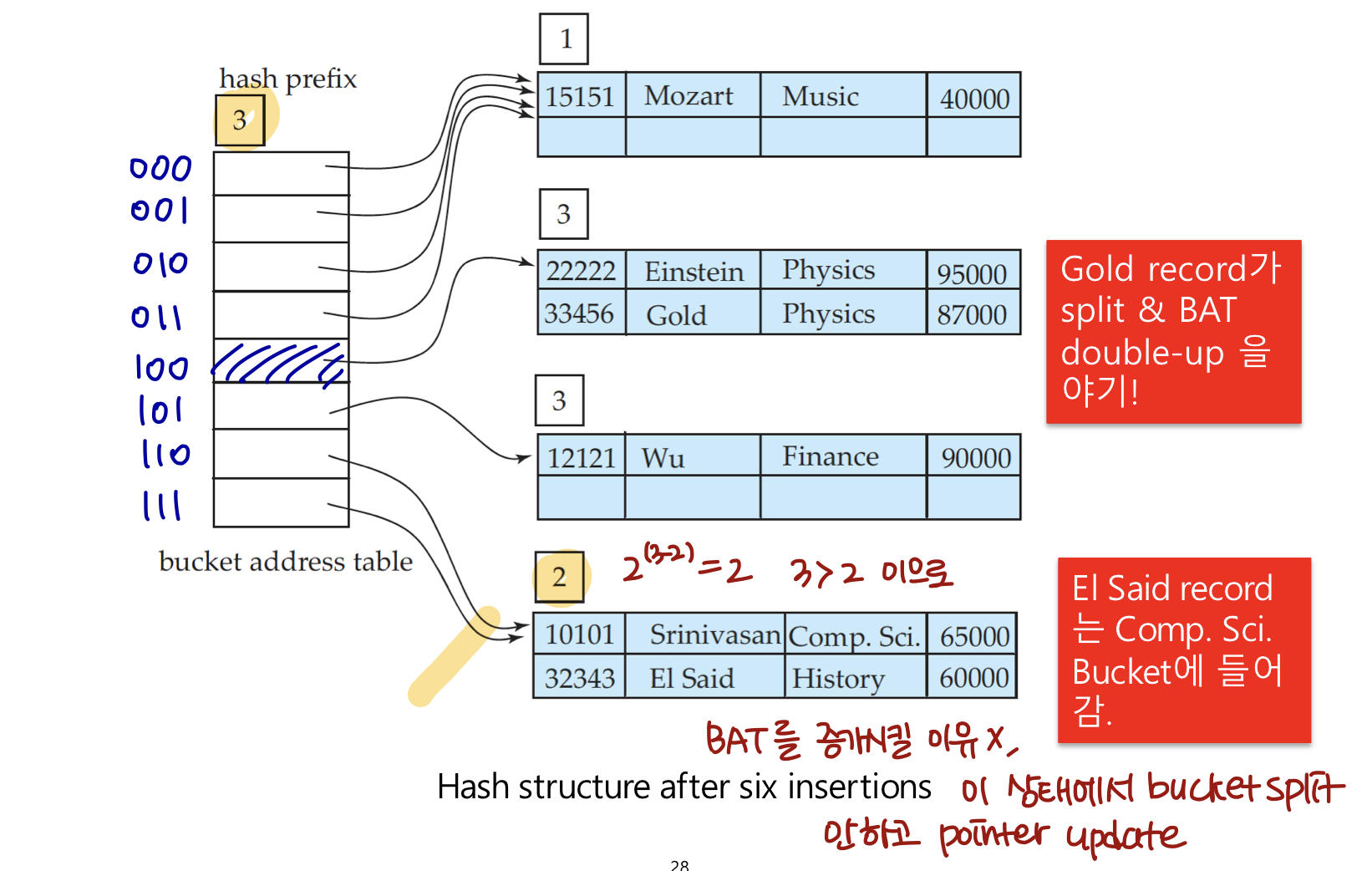
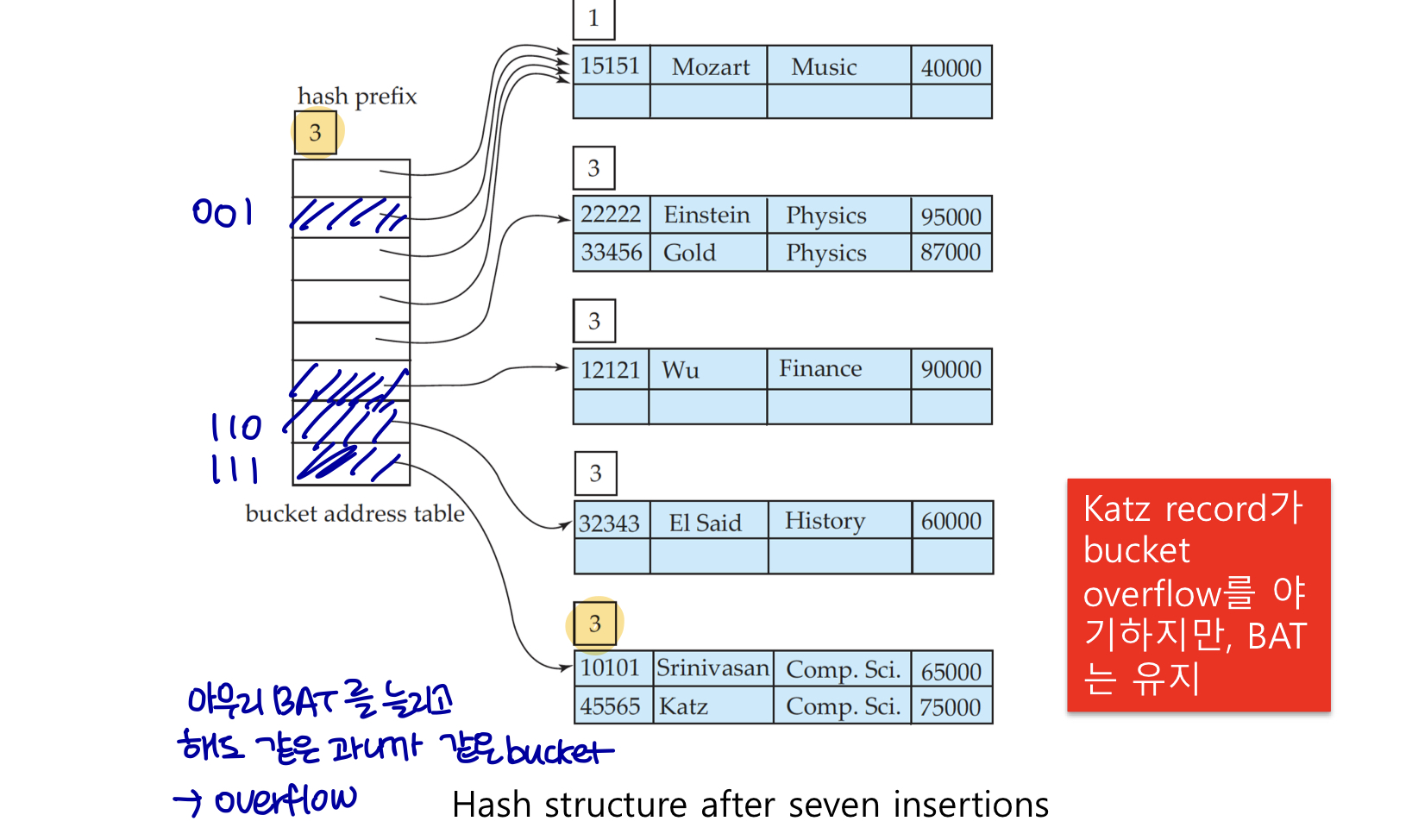
bucket5에서 overflow가 생기지만 같은 과 이므로 BAT를 증가시키기 보단 overflow bucket을 활용한다.
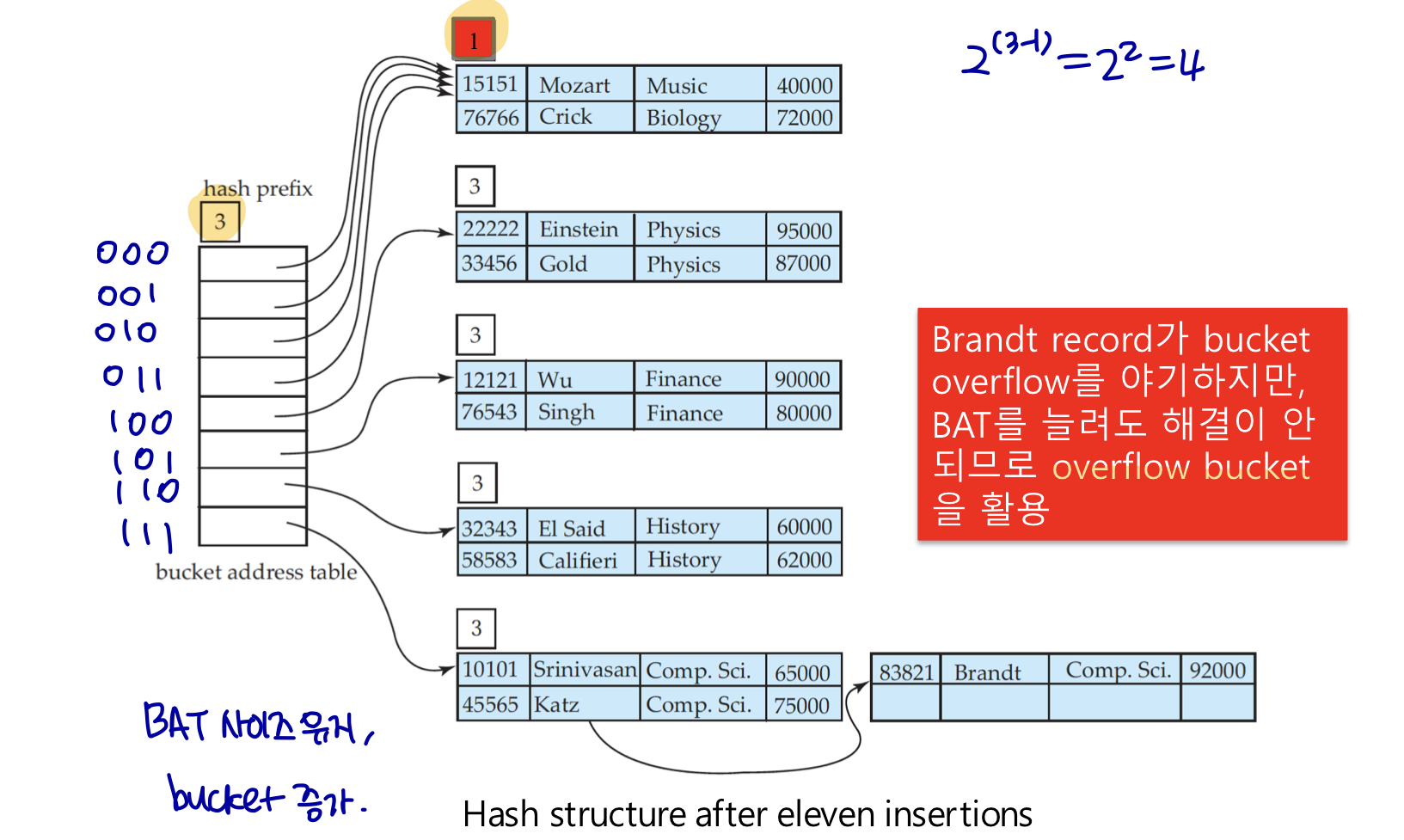
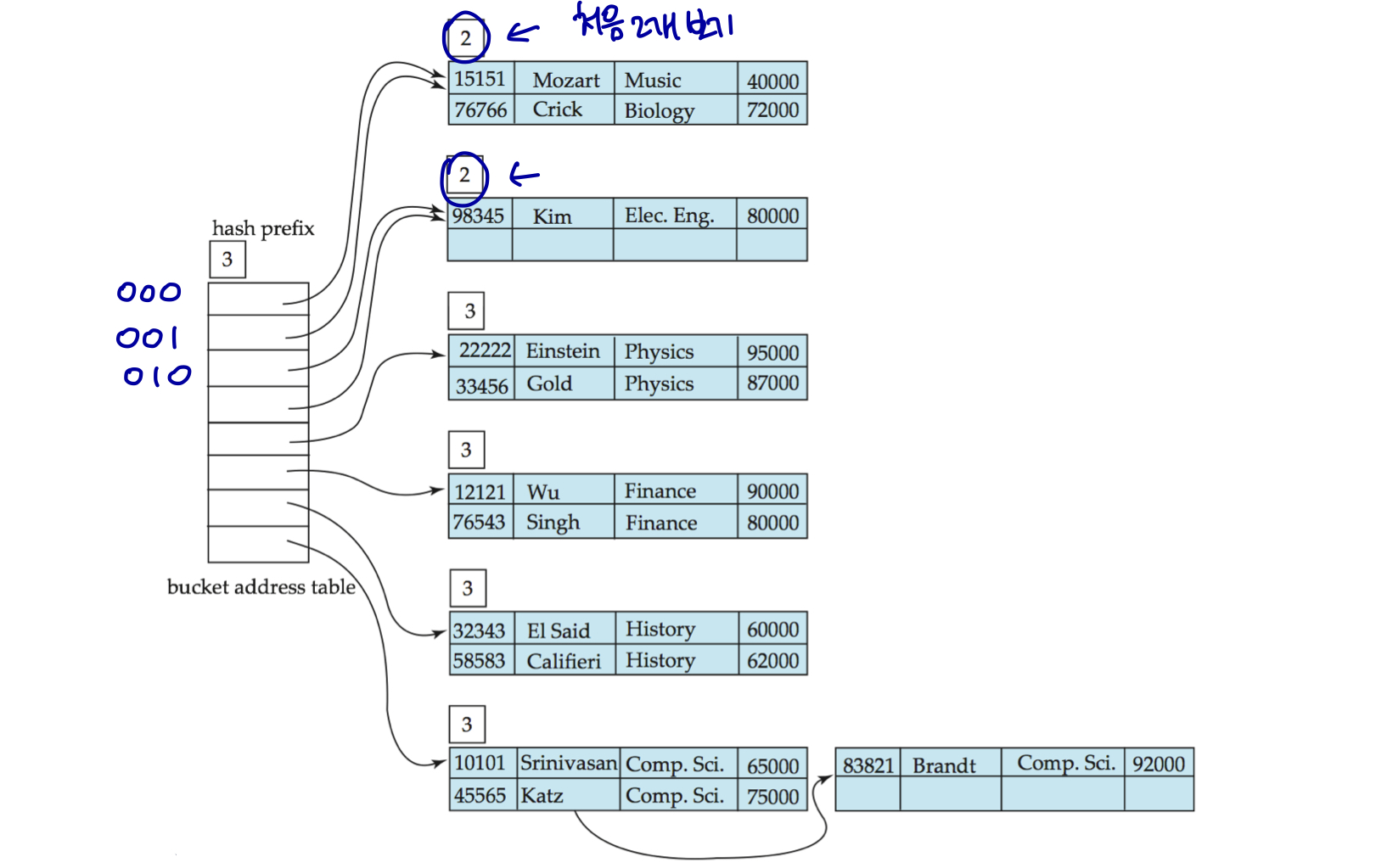
prefix가 늘어났으므로 bucket1도 세분화하여 두 개로 분리한다.
Extendable Hashing vs. Other Schemes
-
Extendable hashing의 장점
-
파일 증가에 따라 해시 성능이 저하되지 않음
-
최소 공간 오버헤드 (어쩔 수 없이 chaining)
-
-
Extendable hashing의 단점
-
원하는 레코드를 찾기 위해 추가 레벨 간접 참조 (h → BAT 를 거쳐야 함)
-
버킷 주소 테이블(BAT) 자체가 매우 커질 수 있다. (메모리 보다 큼)
-
디스크에서 매우 큰 연속 영역을 할당할 수 없다.
-
해결책: 원하는 레코드를 찾기 위한 B+-tree 구조 버킷 주소 테이블
-
-
버킷 주소 테이블의 크기 변경은 비용이 많이 드는 작업이다.
-
-
Linear hashing이 대체 메커니즘이다.
-
디렉토리의 점진적인 증가 허용 (버킷 주소 테이블과 동일)
-
더 많은 버킷 오버플로 비용 (→ threshold로 조정)
-
Comparison of Ordered Indexing and Hashing
예상되는 쿼리 유형
- 해싱은 일반적으로 지정된 키 값이 있는 레코드를 검색하는 데 더 좋다.
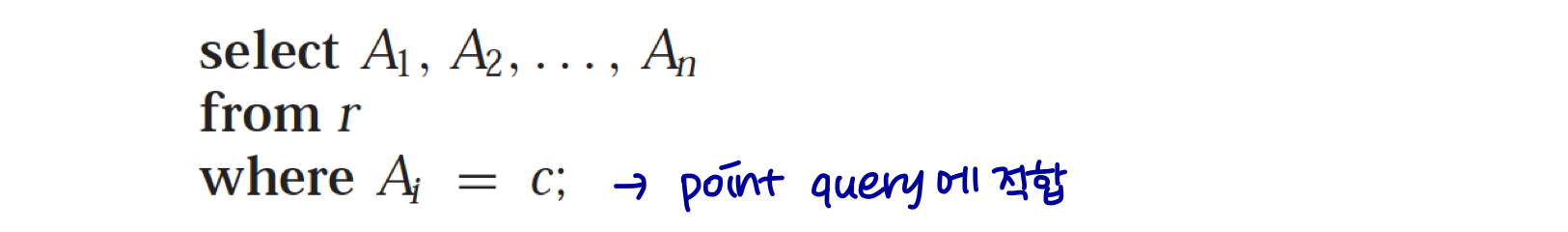
- 범위 쿼리가 일반적인 경우에는 정렬된 인덱스가 선호된다.
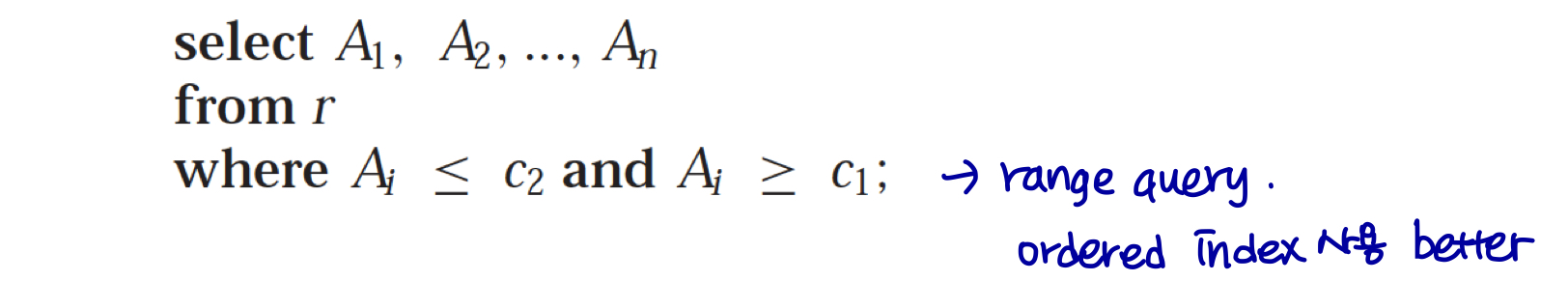
이러한 부분에 있어서는 query optimizer에 의해서 자동 결정된다.
Comparison of Ordered Indexing and Hashing
Issue
-
주기적인 재구성 비용
-
삽입과 삭제의 상대적 빈도
-
최악의 엑세스 시간을 희생하면서 평균 엑세스 시간을 최적화 하는 것이 바람직한 것인가?
In practice
-
Oracle은 정적 해시 구성을 지원하지만 인덱스는 지원하지 않는다.
-
SQLServer는 B+-tree만 지원한다.
-
PostgreSQL은 해시 인덱스를 지원하지만 성능 저하로 인해 사용하지 않도록 한다.
