Relational Algebra
-
Selection: σ
- Horizontal subset
-
Projection: π
- Vertical subset
-
Join: ⋈
- Two tables joined on a certain condition
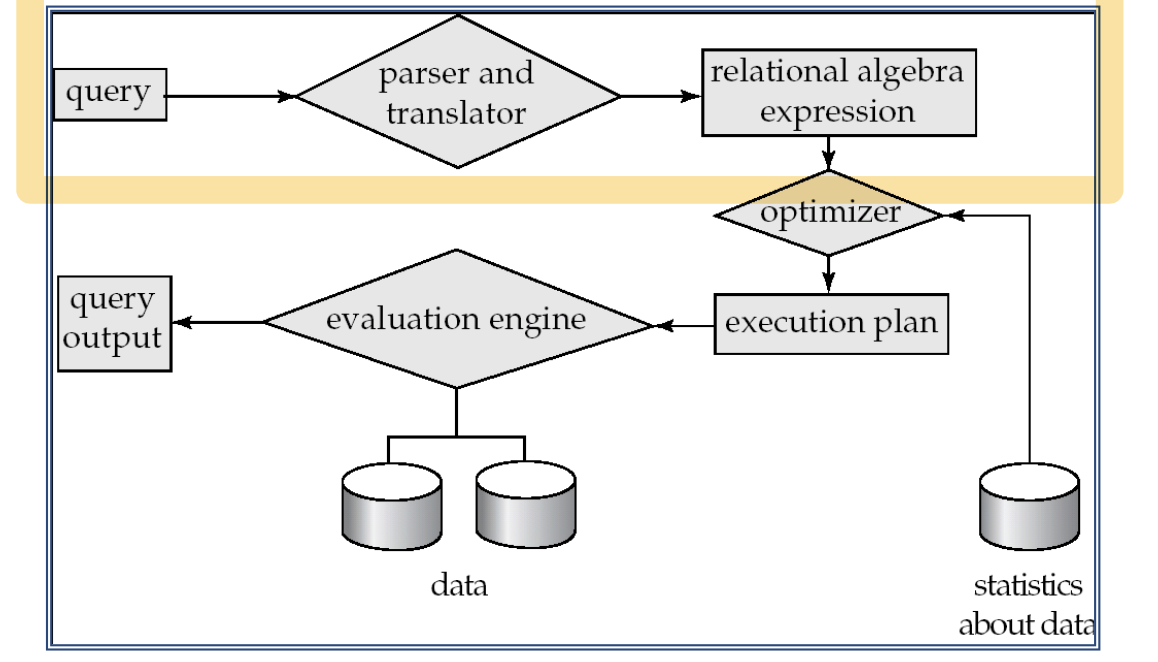
Basic Steps in Query Processing
-
Parsing and translation
-
Optimization
-
Evaluation
-
Parsing and translation
-
쿼리를 내부 형식으로 변환한다.
-
그런 다음 relational algebra로 변환한다.
-
parser가 문법을 확인하고 relation을 확인한다.
-
-
Evaluation
- 쿼리 실행 엔진은 쿼리 평가 계획을 가져와 해당 계획을 실행하고 쿼리에 대한 응답을 반환한다.
Basic Steps in Query Processing : Optimization
-
relational algebra에는 많은 동등한 표현식이 있을 수 있다.
- e.g. σ balance<2500(π balance(account))
is equivalent to
π balance(σ balance<2500(account))
- e.g. σ balance<2500(π balance(account))
-
각 relational algebra 연산은 여러 알고리즘 중 하나를 사용하여 평가할 수 있다.
- 이에 따라 relational algebra 표현은 다양한 방식으로 평가될 수 있다.
-
자세한 평가 전략을 지정하는 주석이 달린 표현을 평가 계획이라고 한다.
-
DBMS의 입장에서 evaluation plan 으로 cost를 추정한다.
-
e.g.)balance에 대한 인덱스를 사용하여 balance(잔액)이 2500 미만인 account(계좌)를 찾을 수 있다. 또는 전체 relation을 스캔하고 balance가 2500이상인 account를 버릴 수 있다.
-
Basic Steps in Query Processing : Optimization (Cont.)
-
쿼리 최적화: 모든 동등한 평가 계획 중에서 비용이 가장 낮은 계획을 선택한다.
-
비용은 데이터베이스 카탈로그의 통계정보를 사용하여 추정된다.
- e.g.) 각 relation의 튜플 수, 튜플 크기 등
-
-
쿼리 프로세싱
-
쿼리 비용 측정 방법
-
relational algebra 연산을 평가하기 위한 알고리즘
-
완전한 식을 평가하기 위해 개별 작업에 대한 알고리즘을 결합하는 방법
-
-
최적화
-
쿼리를 최적화 하는 방법, 즉 최정 추정 비용으로 평가 계획을 찾는 방법
Measures of Query Cost
-
비용은 일반적으로 쿼리에 응답하는 총 경과 시간으로 측정된다.
-
많은 요인이 시간 비용에 기여한다.
- disk access, CPU 또는 네트워크 통신
-
-
일반적으로 디스크 엑세스는 주요 비용이며 비교적 쉽게 예측할 수 있다.
-
다음을 고려하여 측정한다.
-
탐색 횟수 X 평균 탐색 비용
-
읽은 블록 수 X 평균 블록 읽기 비용
-
쓰여진 블록 수 X 평균 블록 쓰기 비용
-
블록을 쓰는 비용이 블록을 읽는 비용보다 크다.
-
쓰기가 성공적이었는지 확인하기 위해 데이터를 쓴 후 다시 읽는다.
-
-
Measures of Query Cost (Cont.)
-
단순화를 위해, 디스크에서 블록 전송을 찾는 횟수와 비용 측정 횟수를 사용한다.
-
tT - 한 블록을 전송하는데 걸리는 시간
-
tS - 한 블록을 찾는데 걸리는 시간
-
b 블록 전송에 대한 비용과 s 탐색
- btT +StS
-
단순화를 위해 CPU 비용은 무시한다.
- 실제 시스템은 CPU 비용을 고려한다.
-
비용 공식에 출력을 디스크에 쓰는 비용을 포함하지 않는다.
-
-
여러 알고리즘은 추가 버퍼 공간을 사용하여 디스크 IO를 줄일 수 있다.
-
버퍼에 사용할 수 있는 실제 메모리의 양은 실행 중에만 알려진 다른 동시 쿼리 및 OS 프로세스에 따라 다르다.
- 작업에 필요한 최소한의 메모리만 사용할 수 있다고 가정하고 최악의 경우 추정치를 사용하는 경우가 많다.
-
-
필요한 데이터는 디스크 I/O를 피하면서 이미 버퍼에 상주할 수 있다.
- 그러나 비용 추정을 고려하기 어렵다.
Selection Operation
-
파일 스캔 - 선택 조건을 충족하는 레코드를 찾아 검색하는 검색 알고리즘이다.
-
알고리즘 A1 (linear search)
-
각 파일 블록을 스캔하고 모든 레코드를 테스트하여 선택 조건을 충족하는지 확인한다.
-
예상 비용 = br 블록 전송(메모리에 올린다.) + 1 탐색
- br은 relation r의 레코드를 포함하는 블록 수를 나타낸다.
-
선택 항목이 키 속성에 있는 경우 레코드 찾기를 중단할 수 있다.
-
비용 = (br / 2) 블록 전송 + 1 탐색
-
(대략 중간쯤에 있을 것이라 추정하고 탐색하는 방법)
-
-
다음과 관계없이 선형 검색을 적용할 수 있다.
-
선택 조건
-
파일 레코드의 순서
-
index의 가용성
-
-
Selection Operation (Cont.)
-
A2 (binary search)
-
선택이 파일이 정렬된 속성에 대한 동등성 비교인 경우에 적용 가능하다.
-
relation의 블록이 연속적으로 저장된다고 가정한다.
-
예상 비용(스캔할 디스크 블록 수):
-
블록에 대한 이진 검색으로 첫 번째 튜플을 찾는 비용
-
[log2(br)] * (tT + tS)
-
선택을 만족하는 레코드가 여러 개인 경우
-
선택 조건을 만족하는 레코드를 포함하는 블록 수의 전송 비용 추가
-
나중에 이 비용을 추정하는 방법을 확인한다.
-
-
-
B+ - Tree
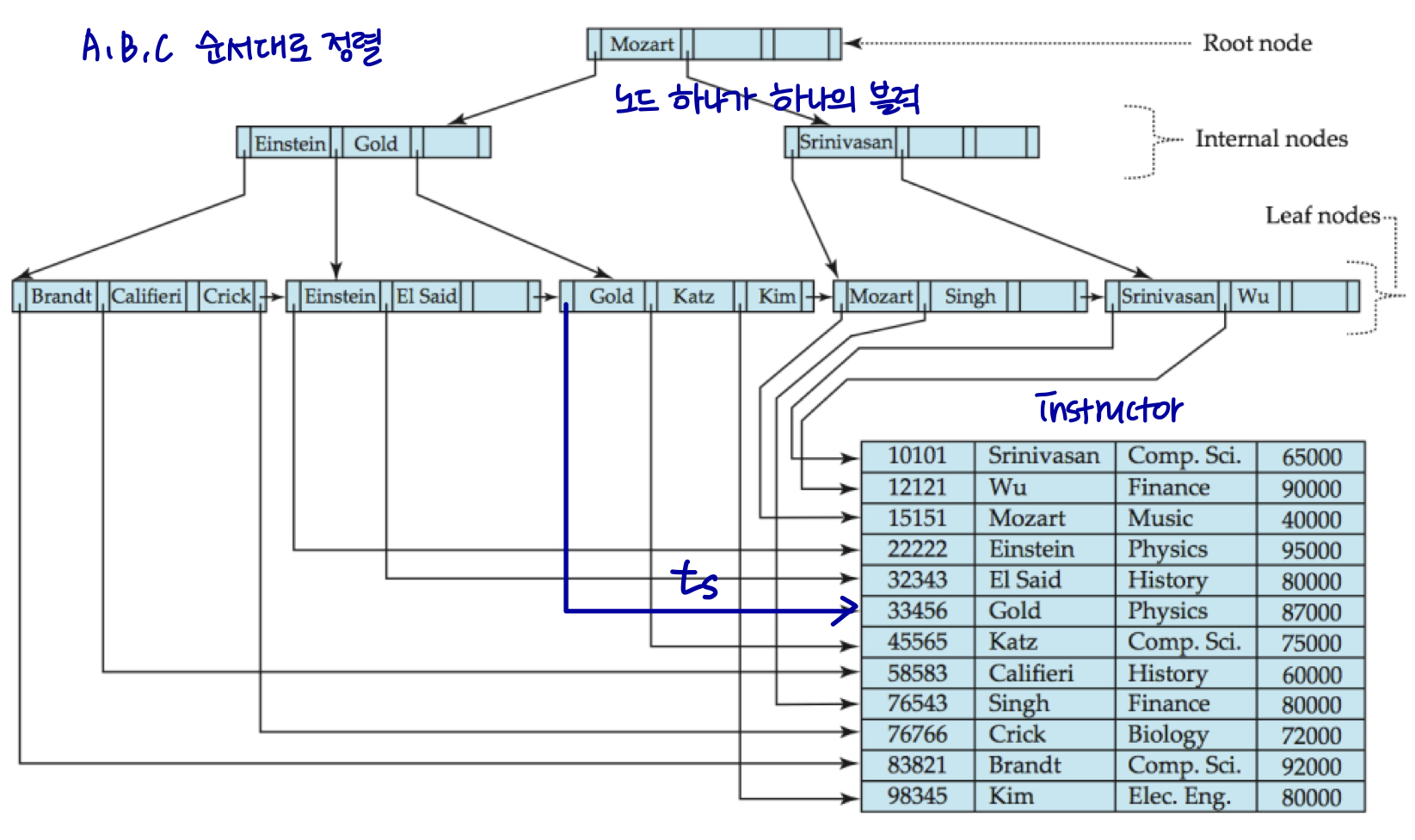
Secondary Indices Example
-
인덱스 레코드는 특정 검색 키를 가진 모든 실제 레코드에 대한 포인터를 포함하는 버킷을 가리킨다.
-
보조 인덱스는 밀도가 높아야 한다.
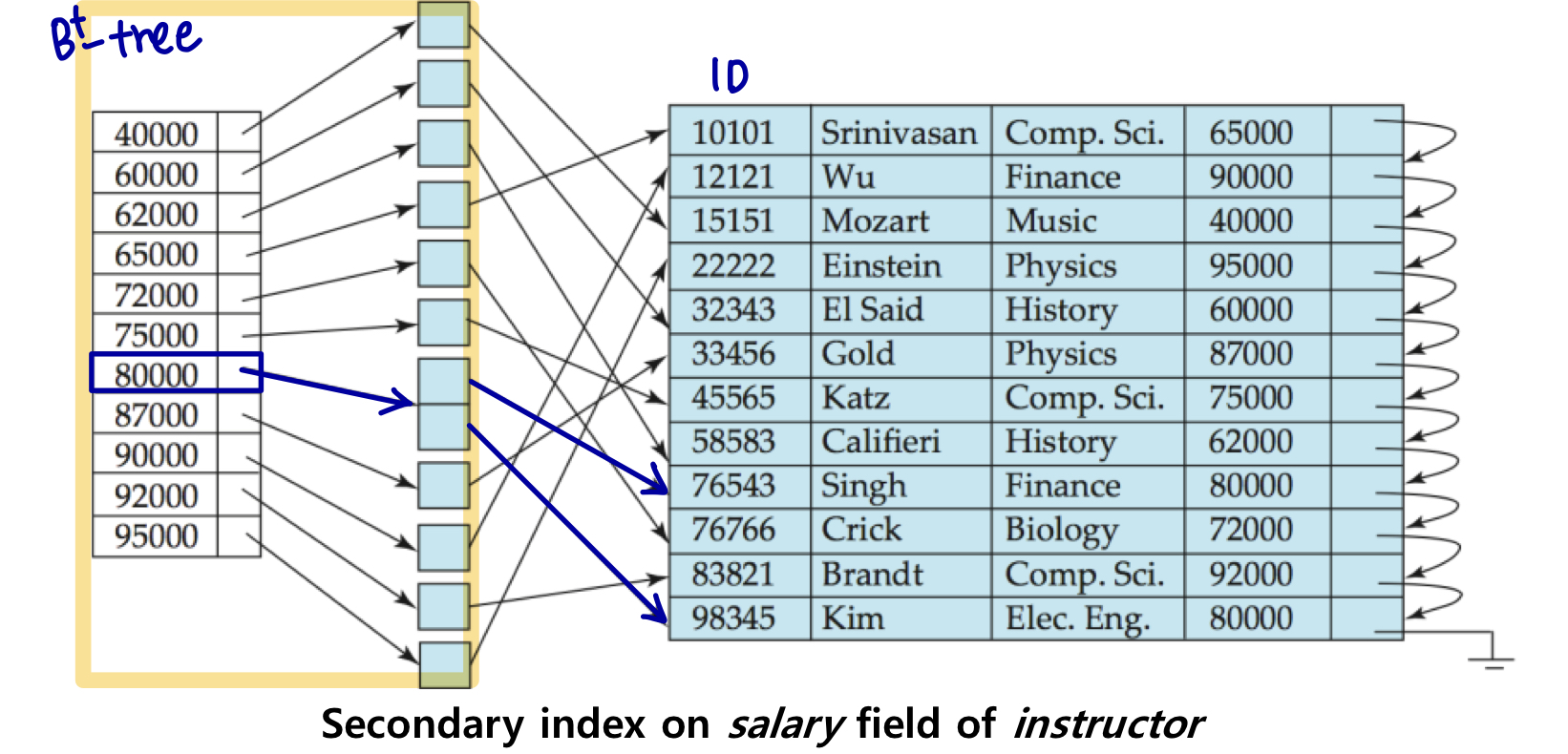
Selections Using Indices
인덱스 스캔 - 인덱스를 사용하는 검색 알고리즘
-
A3 (후보 키에 대한 기본 인덱스, 동등성)
-
해당 같음 조건을 만족하는 단일 레코드 검색
-
B+ 트리가 사용되는 경우, Cost = (hi + 1) * (tT + tS).
- 여기서 hi는 높이이다.
-
-
A4 (키가 아닌 기본 인덱스, 동등성)
-
레코드는 연속 블록에 있다. (’.’ 기본 인덱스)
-
Cost = hi (tT +tS)+tS +tT b
- 여기서 b는 일치하는 레코드를 포함하는 블록 수 이다.
-
