Sorting
-
정렬은 중요하다.
-
SQL 쿼리는 정렬할 출력을 지정한다.
-
입력 relation을 먼저 정렬하면 join을 효율적으로 구현할 수 있다.
-
-
relation에 대한 인덱스를 구축한 다음 인덱스를 사용하여 정렬된 순서로 relation을 읽을 수 있다.
-
relation을 논리적으로만 정렬하므로 각 튜플에 대한 하나의 디스크 블록 엑세스로 이어질 수 있다.
- 레코드를 물리적으로 정렬하는 것이 바람직할 수 있다.
-
메모리에 맞는 relation의 경우, 퀵 정렬과 같은 기술을 사용할 수 있다.
-
메모리에 맞지 않는 relation의 경우, 외부 정렬-병합이 좋은 선택이다.
- sort를 한 번에 못해서 일부씩 sort하고 merge하는 정렬 알고리즘
External Sort-Merge
-
M이 메모리 크기를 나타낸다고 하자.
- (메인 메모리의 블록 / 페이지 프레임 수)
-
N은 run의 개수를 나타낸다고 하자.
-
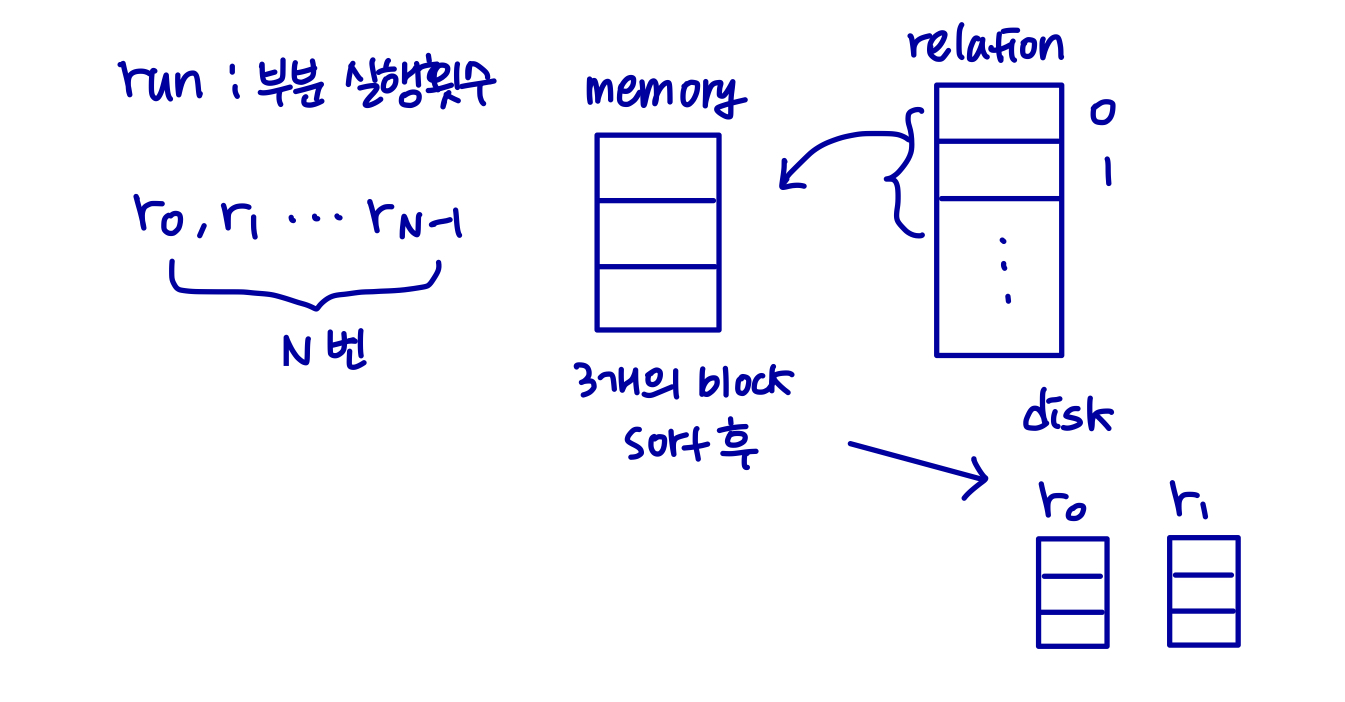
정렬된 runs(실행)을 생성한다. i 는 0으로 초기화 한다.
relation이 끝날 때까지 다음을 반복한다.
(a) relation의 M 블록을 메모리로 읽어온다.
(b) in-memory 블록을 정렬한다.
(c) 파일 Ri를 실행하기 위해 정렬된 데이터를 기록하고, 증분 i
i 의 최종 값을 N으로 설정
-
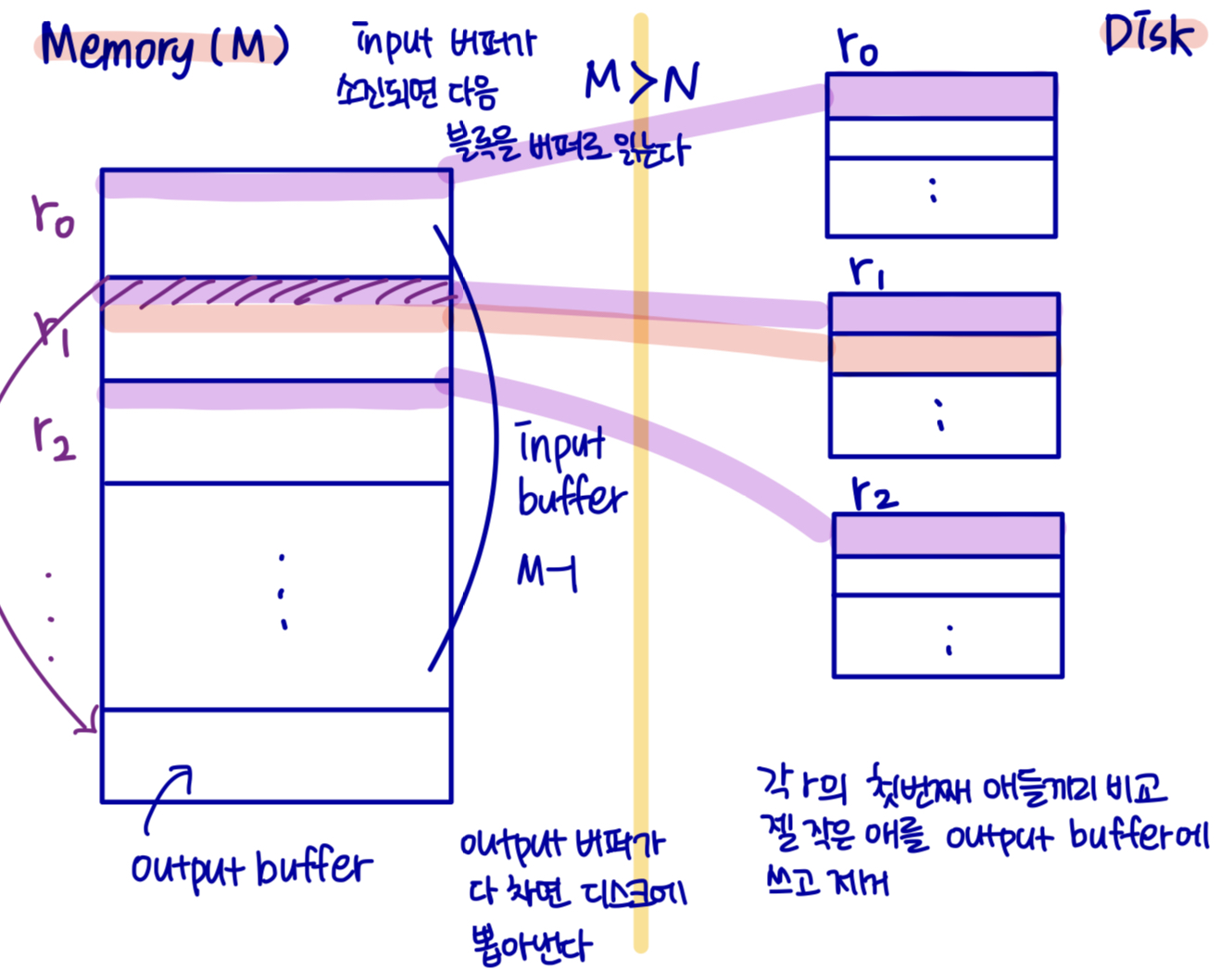
실행(runs)을 병합한다. (N방향 병합) (현재로서는) N < M 이라고 가정
-
N 블록의 메모리를 사용하여 입력 run을 버퍼링하고 1 블록을 버퍼 출력에 사용한다. 버퍼 페이지로 각 실행의 첫 번째 블록을 읽는다.
-
반복한다.
-
모든 버퍼 페이지 중에서 첫 번째 레코드(정렬 순서)를 선택한다.
-
레코드를 출력 버퍼에 쓴다. 출력 버퍼가 가득차면 디스크에 쓴다.
-
입력 버퍼 페이지에서 레코드를 삭제한다.
만약 버퍼 페이지가 비어있는 경우 실행의 다음 블록(있는 경우)을 버퍼로 읽는다.
-
-
모든 입력 버퍼 페이지가 비워질 때까지;
-
글로만 보면 이해가 어려울 수 있으니 과정을 정리한 그림을 첨부한다.
External Sort-Merge (Cont.)
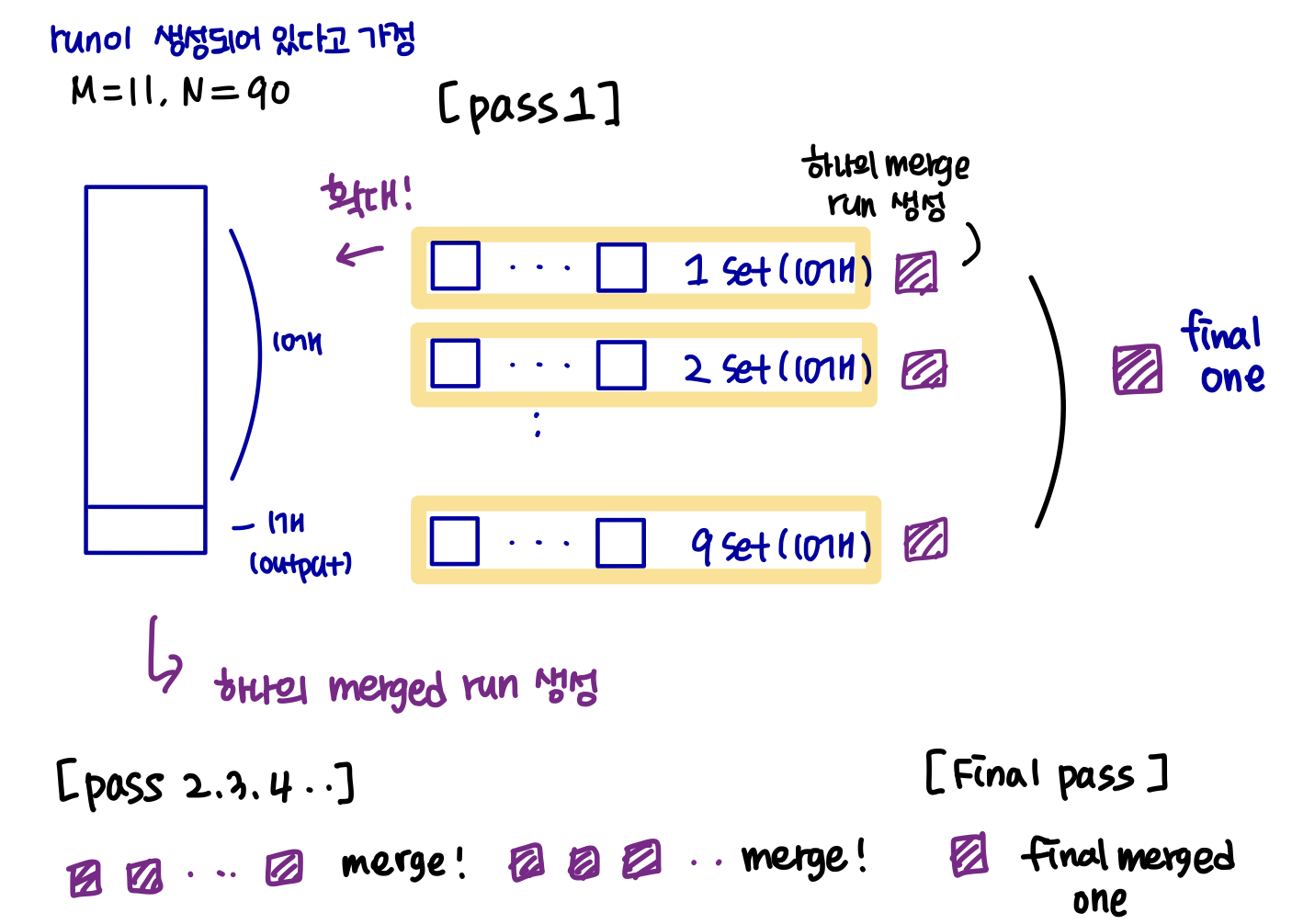
N ≥ M 인 경우, 여러 병합 패스가 필요하다.
-
각 패스마다, M-1개의 runs(실행)의 연속적인 집합이 병합된다.
-
패스는 M-1의 인수로 runs(실행) 수를 줄이고 동일한 인수로 더 긴 runs(실행)을 생성한다.
-
e.g.) 만약 M=11 이고 90개의 runs가 있는 경우, 한 번의 패스 후에 runs(실행)수가 9개로 줄어 각 런의 크기가 초기 run 크기의 10배가 된다.
-
br / M = 90, br / 10 = 90, br = 900
-
-
모든 run이 하나로 병합될 때까지 반복 패스가 수행된다.
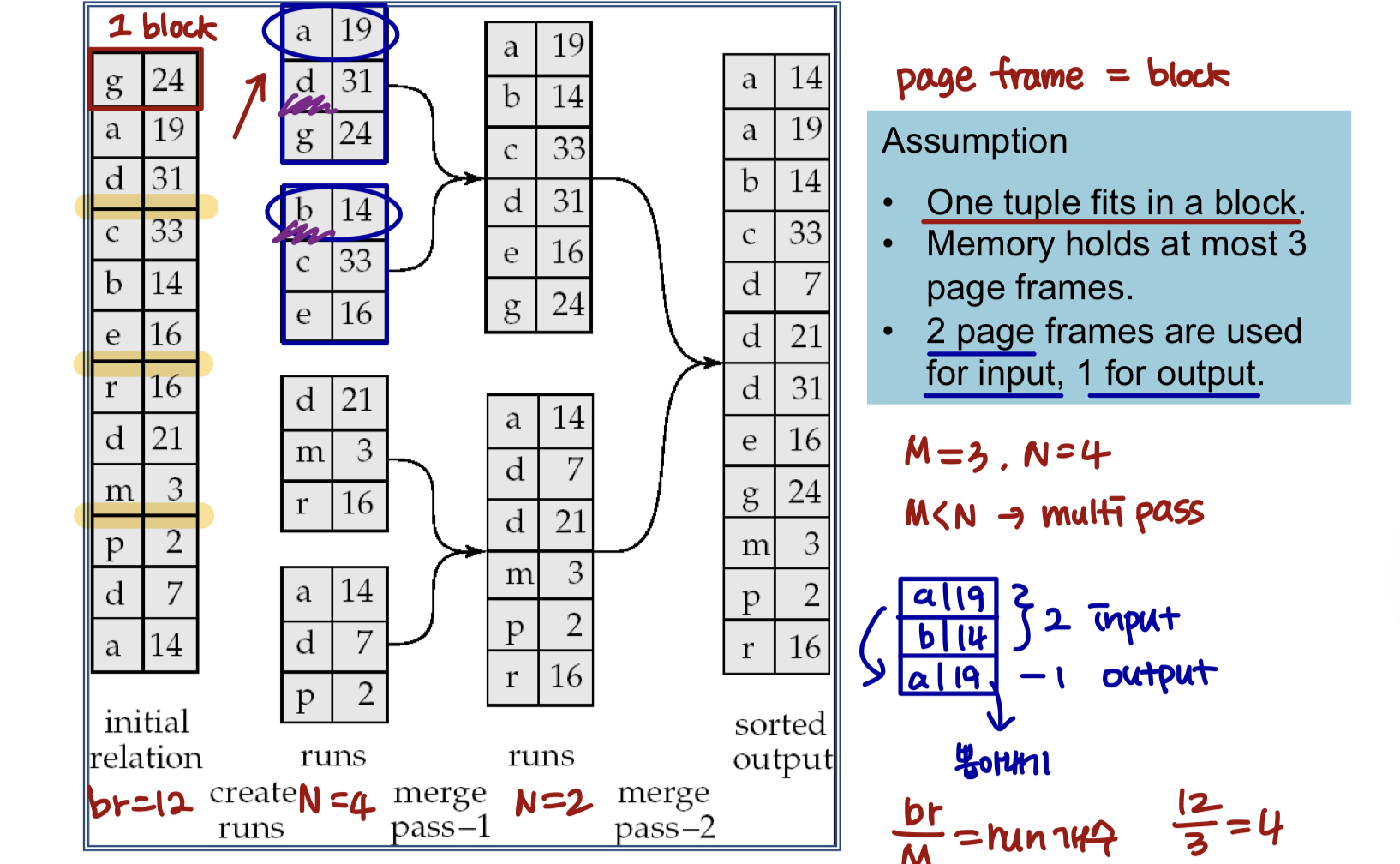
Example: External Sorting Using Sort-Merge
실제 relation 예시 그림으로 보면 이해가 수월하다.
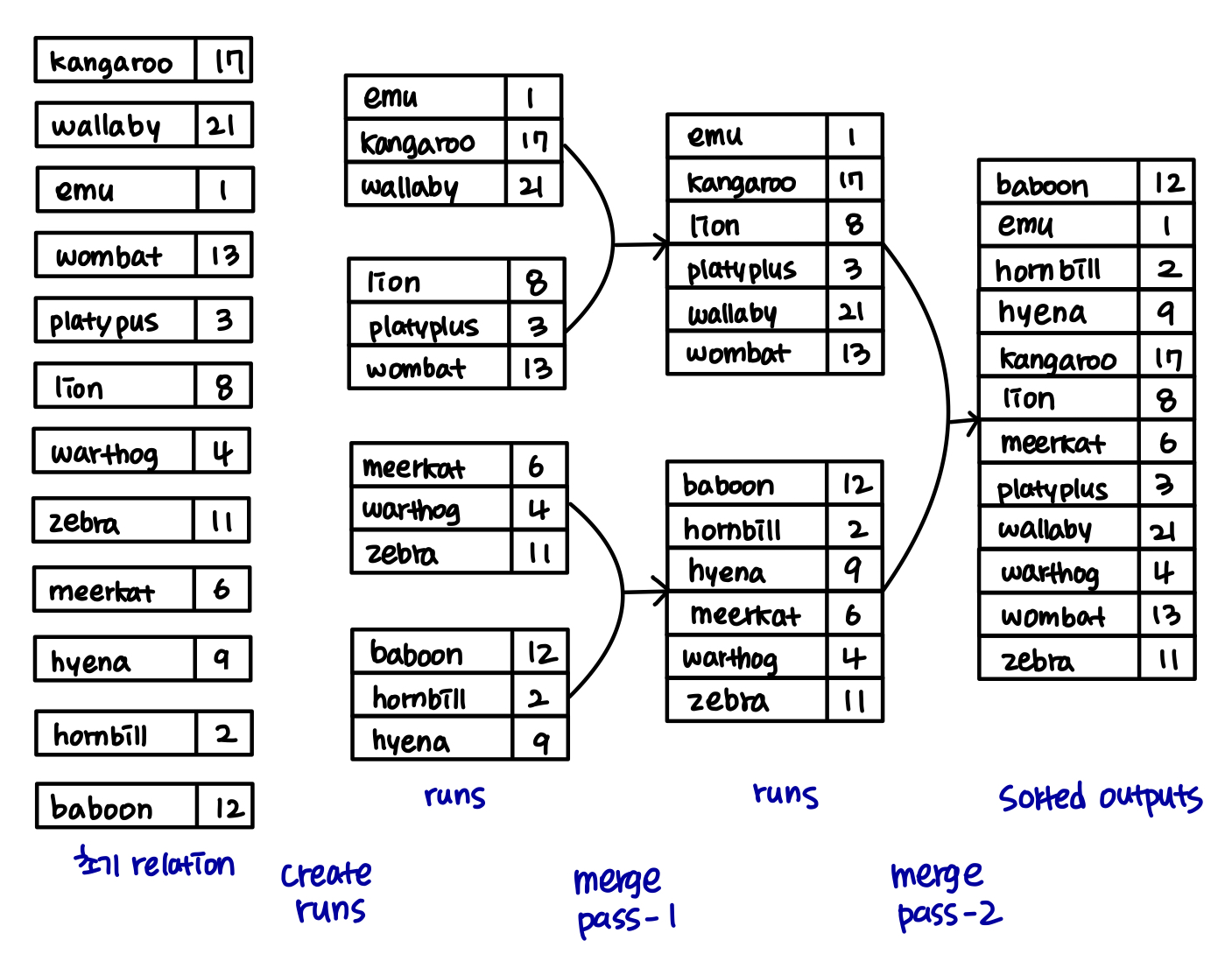
External Merge Sort (Cont.)
- 비용 분석:
-
필요한 총 병합 패스 수: [ logM-1(br/M)].
- br은 relation r의 레코드를 포함하는 블록의 수이다.
-
초기 run 생성 및 각 패스의 블록 전송은 2br이다. (읽기, 쓰기)
-
최종 단계에서는 쓰기 비용을 계산하지 않는다. (-br)
- 작업의 output이 디스크에 기록되지 않고 상위 작업으로 전송될 수 있으므로 모든 작업에 대한 최종 쓰기 비용을 무시한다.
-
따라서 외부 정렬을 위한 총 블록 전송 수: br(2[logM-1(br/M)]+1)
-
seeks: 추후 이어서..
-

External Merge Sort (Cont.)
- 탐색 비용:
-
run 생성 동안: 한 번은 각각의 run을 읽고 한 번은 각 run을 쓰려고 한다.
-
2 * run의 개수
-
2 [ / M ]
-
-
병합 패스 동안:
-
버퍼 사이즈: (한 번에 블록 읽고 쓰기)
-
각 병합 패스에 대해 2[ / ] 검색이 필요하다.
- 쓰기가 필요하지 않은 마지막 항목을 제외하고
-
총 탐색 횟수:
- 2 [ / M ] + [ / ] (2 [$log_{m-1}(b_r / M)]-1)$
-
또는 간단히 마지막 경우를 무시할 수 있다.
- 2 [ / M ] + [ / ] (2 [$log_{m-1}(b_r / M)])$
-
-

Join Operation
-
join을 구현하기 위한 몇 가지 알고리즘이 있다.
-
Nested-loop join
-
Block Nested-loop join
-
Indexed nested-loop join
-
Merge-join
-
Hash-join
-
-
비용 견적에 따른 선택
-
예제에서는 다음 정보를 사용한다.

- Customer relation의 경우 block 1개에 25개의 레코드가 들어가고, Depositor relation의 경우 block 1개에 50개의 레코드가 들어간다.
Join in SQL
SELECT *
FROM Customer, Depositor
WHERE Customer.ID = Depositor.Customer_ID
Customer relation: outer relation
Depositor relation: inner rleation
-
어떤 relation을 outer/inner 로 정하는지에 따라 성능이 달라진다.
-
하지만 이는 쿼리 옵티마이저가 알아서 순서를 조정해서 join하므로 개발자가 신경쓸 필요는 없다.
Nested-Loop Join
- 세타 조인 을 계산하기 위해서 (임의의 조건: θ)

-
r은 join에 있어서 outer relation이라 부르고 s는 inner relation이라 부른다.
-
인덱스가 필요하지 않으며 모든 종류의 조인 조건과 함께 사용될 수 있다.
-
두 relation의 모든 튜플 쌍을 검사하기 때문에 비용이 많이 든다.
Nested-Loop Join (Cont.)
-
최악의 경우, 각 relation의 블록 하나만 보관할 수 있는 메모리가 있다면 , 추정된 비용은 다음과 같다.
- block 전송 (: r에 있는 tuple의 개수, : s의 block 개수, : r의 block 개수)
-
만약 더 작은 relation이 메모리에 완전히 들어 맞으면, 해당 relation을 inner relation으로 사용한다.
-
메모리에 올려놓고 비교하기 때문에 비용이 감소한다.
-
block 전송
-
튜플 단위로 비교
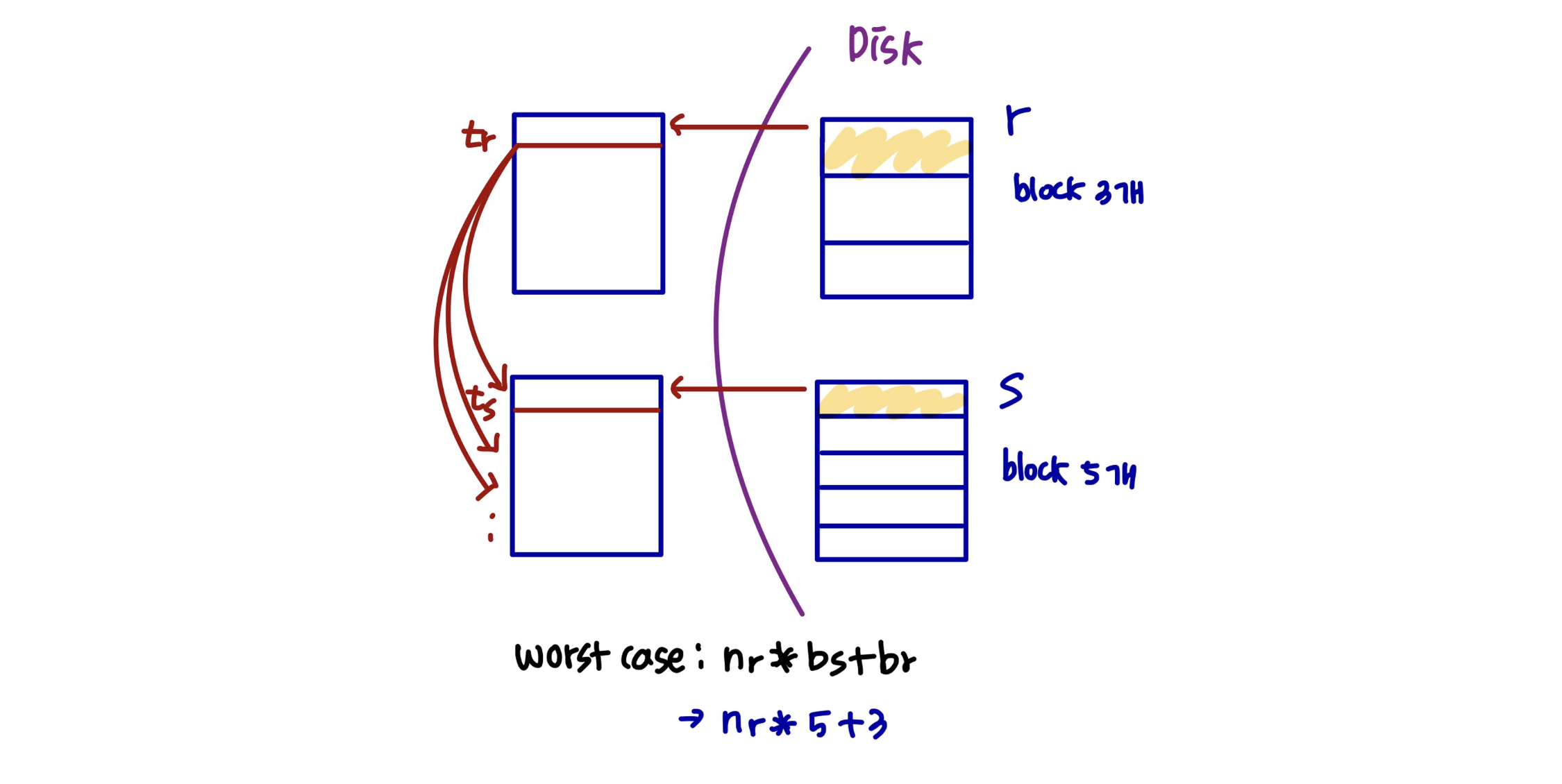
Nested-Loop Join (Cont.)

-
최악의 경우 메모리 가용성 비용 추정치를 다음과 같이 가정한다.
-
depositor가 outer relation인 경우:
- 5,000 * 400 + 100 = 2,000,100 block 전송
-
customer가 outer relation인 경우:
- 10,000 * 100 + 400 = 1,000,400 block 전송
-
-
더 작은 relation(Depositor)이 메모리에 완전히 맞는 경우 예상 비용은 500 block 전송이 된다.
-
Block nested-loops 알고리즘 (다음 챕터) 가 바람직하다.
Block Nested-Loop Join
- inner relation의 모든 블록이 outer relation의 모든 블록과 쌍을 이루는 nested-loop join의 변형이다.

블록 단위로 비교
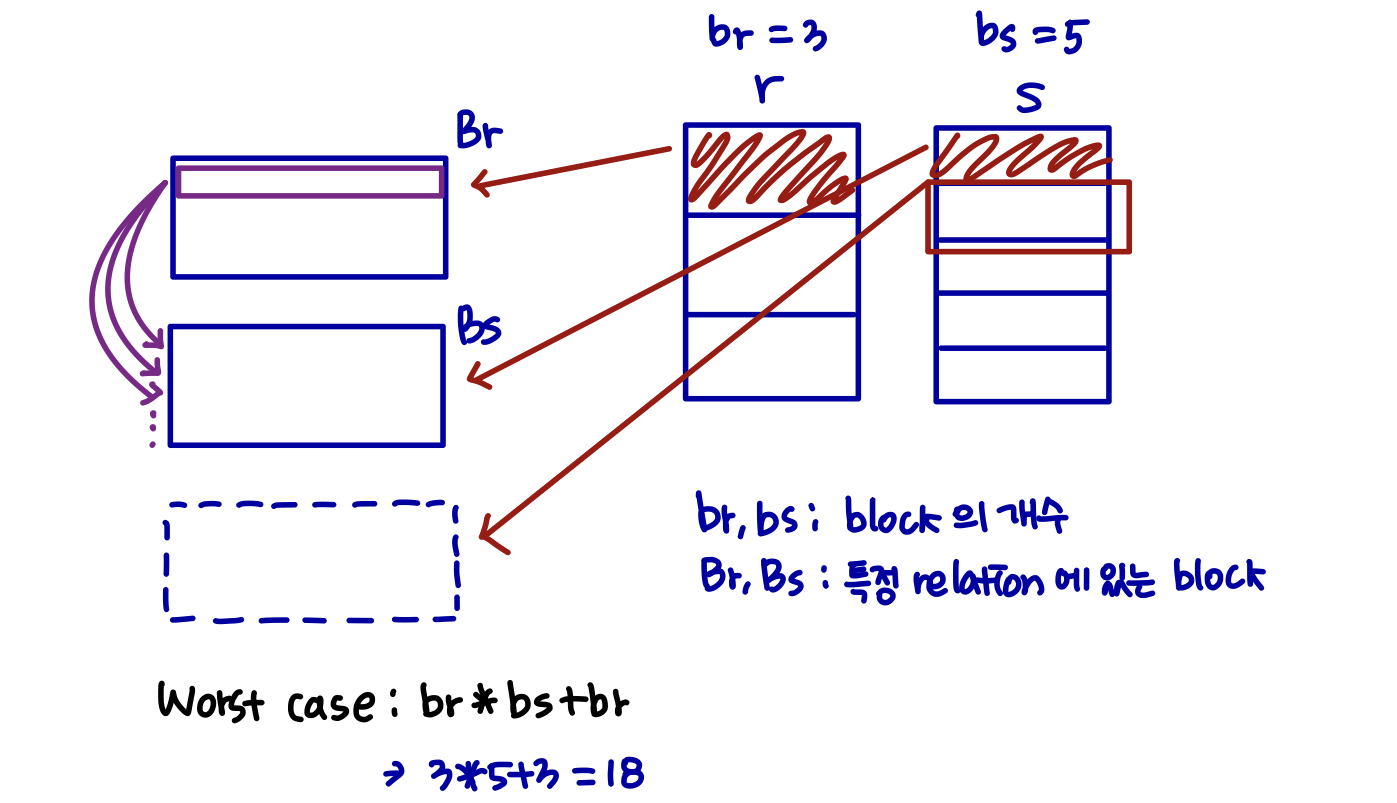
Block Nested-Loop Join (Cont.)
-
최악의 경우 추정: block 전송
- inner relation s의 각 블록은 outer relation의 각 블록에 대해 한 번 읽는다. (outer rleation의 각 튜플에 대해 한 번이 아니라)
-
최선의 경우: block 전송
Improvements
-
nested loop 와 block neseted loop 알고리즘에 대한 개선사항:
-
block nested-loop 에서, outer relation에 대한 차단 단위로 M-2 디스크 블록을 사용한다. 여기서 M은 블록의 메모리 사이즈이다.
-
나머지 두 블록을 사용하여 inner relation 과 output 버퍼링
- 비용 = block 전송
-
equi join 속성이 inner relation에서 키를 형성하는 경우, 첫 번째 일치에 inner loop를 중지한다.
-
inner loop를 앞뒤로 번갈아 스캔하여 버퍼에 남아있는 블록을 사용한다. (LRU 대체 포함)
-
가능한 경우 inner relation에 인덱스를 사용한다. (이 부분은 이어서 설명)
-
Indexed Nested-Loop Join
-
인덱스 검색이 파일 검색을 대체할 수 있는 경우
-
join이 equi-join이거나 natural join인 경우
-
inner relation의 조인 속성에 대한 인덱스를 사용할 수 있는 경우
-
join을 계산하기 위해 인덱스를 구성할 수 있다.
-
본질적으로 inner relation에 대한 selection
-
-
-
outer relation r에 있는 각 튜플 에 대해서
- 과의 조인조건을 만족하는 s에 있는 튜플들을 검색하기 위해 인덱스를 사용한다.
Indexed Nested-Loop Join(Cont.)
-
최악의 경우: r의 한 페이지에 대한 버퍼 공간과 인덱스를 위한 한 페이지, r의 각 튜플에 대해 S에서 인덱스 조회를 수행한다.
-
join 비용:
-
여기서 c는 인덱스를 순회하고 하나의 튜플 또는 r에 대해 일치하는 모든 s 튜플을 가져오는 비용이다.
-
c는 조인 조건을 사용하여 s에서 단일 선택 비용으로서 추정할 수 있다.
-
-
r과 s 모두의 조인 속성에서 인덱스를 사용할 수 있는 경우 튜플 수가 적은 relation을 outer relation으로 사용한다.
Example of Nested-Loop Join Costs

-
depositor를 outer relation으로 설정하고, depositor와 customer의 natural join을 계산한다.
-
customer가 각 인덱스 노드에 20개의 항목을 포함하는 조인 속성인 customer-name에 기본 B+ 트리 인덱스를 갖도록 한다.
-
customer가 10,000개의 튜플을 가지고 있기 때문에 트리의 높이는 4이고 실제 데이터를 찾으려면 한 번 더 엑세스해야한다.
-
depositor는 5,000개의 튜플을 가지고 있다.
-
block nested loop join의 비용
-
-
100 * 400 + 100 = 40,100 block 전송
-
최악의 메모리 가정
-
메모리가 많을수록 훨씬 적을 수 있다.
-
-
indexed nested loop join의 비용
-
-
100 + 5000 * 5 = 25,100 block 전송
-
CPU 비용은 block nested loop join에 대한 비용보다 적을 수 있다.
-
Merge-Join (Sort-merge Join)
-
조인 속성에 대해 두 relation을 모두 정렬 (조인 속성에 대해 아직 정렬되지 않은 경우)
-
정렬된 relations를 병합하여 결합한다.
-
natural join 및 equi-join을 계산하는데 사용될 수 있다.
-
조인 단계는 정렬-병합 알고리즘의 병합단계와 유사하다.
-
주요 차이점은 결합 속성에서 중복 값을 처리하는 것이다. 결합 속성에서 동일한 값을 가진 모든 쌍은 계산되어야 한다.
Merge-Join (Cont.)
-
각 블록은 한 번만 읽어야 한다.
-
따라서 병합 조인 비용은 block 전송 + relation이 정렬되지 않은 경우 정렬 비용
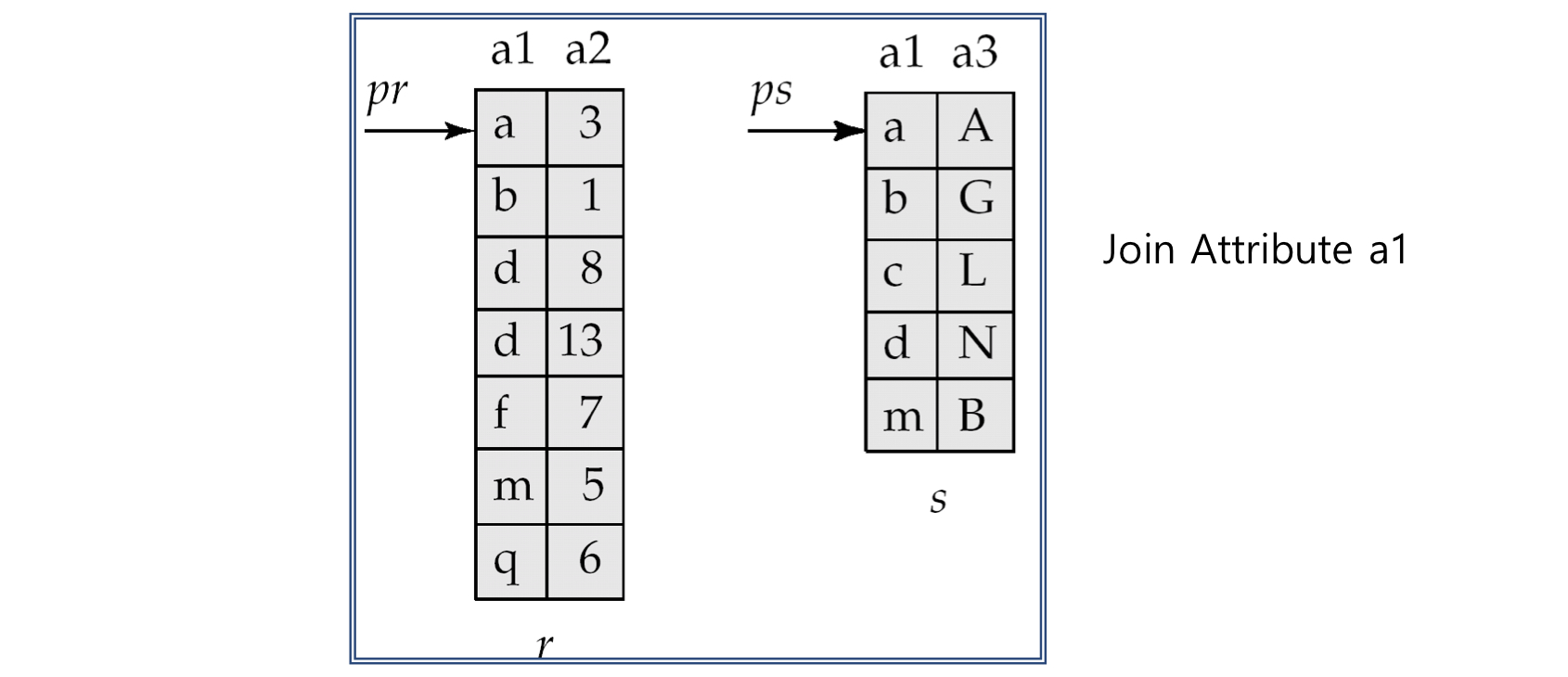
Merge-Join (Cont.)

