Hash-Join
-
해시 함수 h는 두 relation의 튜플을 분할하는 데 사용된다.
-
natural join과 equi-join에 적용 가능하다.
-
h는 joinAttrs 값을 {0,1, … n}에 매핑한다. 여기서 joinAttrs는 natural join에 사용되는 r 과 s의 공통 attributes 이다.
-
r0, r1, … , rn은 r 튜플들의 파티션을 나타낸다.
-
r에 속한 각 튜플 tr은 i = h(tr[joinAttrs]) 인 파티션 ri에 배치된다.
-
s0, s1, … , sn은 s 튜플들의 파티션을 나타낸다.
-
s에 속한 각 튜플 ts는 i = h(ts[joinAttrs]) 인 파티션 si에 배치된다.
-
Hash-Join (Cont.)
h: x mod 5
각 파티션끼리 조인 가능한지 확인하므로 성능이 좋다.
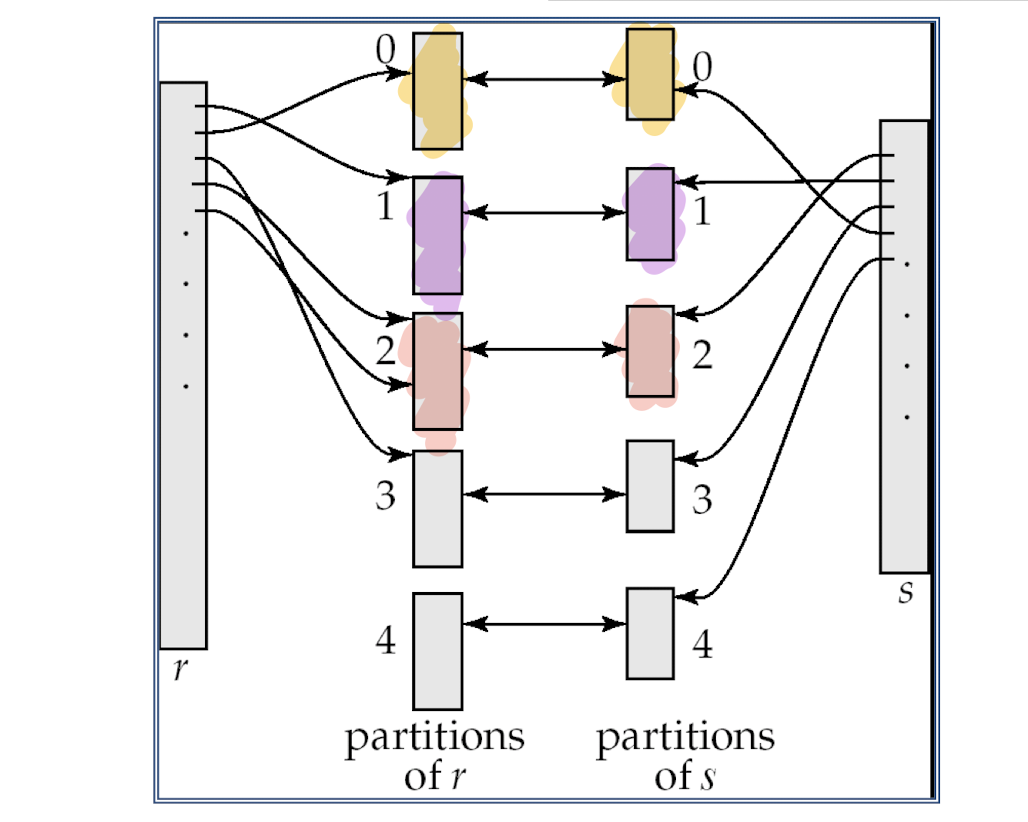
Hash-Join (Cont.)
-
ri 에 있는 r 튜플들은 si에 있는 s 튜플들과만 비교 가능하다.
-
다른 파티션의 s 튜플과 비교할 필요가 없다.
-
왜냐하면..
-
조인 조건을 만족하는 r 튜플과 s 튜플은 조인 속성에 대해 동일한 값을 갖는다.
-
해당 값이 어떤 값 i로 해시되면 r 튜플은 ri에 있어야 하고 s 튜플은 si에 있어햐 한다.
-
Hash-Join Algorithm
r 과 s의 해시 조인은 다음과 같이 계산된다.
-
해싱 함수 h를 사용하여 relation s를 분할한다. relation을 분할할 때, 메모리의 한 블록은 각 분할에 대한 출력 버퍼로 예약된다.
-
파티션 r도 동일하게 동작한다.
-
각 i 에 대하여
-
si를 메모리에 로드하고 joinAttrs을 사용하여 in-memory 해시 인덱스를 빌드한다. 이 해시 인덱스는 이전 h와 다른 해시 함수를 사용한다.
-
디스크에서 하나씩 ri의 튜플을 읽는다. 각 튜플 tr에 대해 in-memory 해시 인덱스를 사용하여 si에서 일치하는 각 튜플 ts를 찾는다. 속성의 연결(concatenation)을 출력한다.
-
relation s는 build input 이라 부르고, r 은 probe input이 라고 부른다.
Handling of Overflows
-
일부 파티션이 다른 파티션보다 엄청나게 많은 튜플을 갖는 경우 분할이 왜곡되었다고 한다.
-
si가 메모리에 맞지 않으면 파티션 si에서 해시 테이블 오버플로(hash-table overflow)가 발생한다. 이유는 다음과 같다.
-
조인 속성에 대해 동일한 값을 가진 s의 많은 튜플
-
잘못된 해시 함수
-
-
오버플로 해결은 빌드 단계에서 수행할 수 있다.
-
다른 해시 함수를 사용하여 더 분할된 파티션 si
-
파티션 ri는 유사하게 분할되어야 한다.
-
-
오버 플로 방지: 빌드 단계에서 오버플로를 방지하기 위해 신중하게 파티셔닝을 수행한다.
- e.g.) 빌드된 relation을 여러 파티션으로 분할한 다음 결합
-
많은 수의 중복으로 인해 두 가지 접근방식 모두 실패한다.
- 폴백 옵션(fallback option): 오버플로된 파티션에 블록 중첩된 루프 조인 사용
Cost of Hash-Join
-
해시 조인의 비용은 블록 전송이다.
-
분할 단계에서 완전한 읽기 및 후속 쓰기의 경우 2(br + bs)
-
build와 probe 단계는 ()가 필요하다.
-
relation 마다 부분적으로 채워진 블록이 있는 n개의 파티션
- 오버헤드 2n*2 (read/write)
-
4n을 무시: 3()
-
-
전체 빌드 입력을 메인 메모리에 보관할 수 있는 경우 파티셔닝이 필요하지 않다.
- 비용 견적이 로 내려간다.
Example of Hash-Join Cost
customer ⋈ depositor
-
가용 메모리 공간을 20 block으로 가정하자.
-
,
-
둘 중 작은 애를 build input으로 쓴다.
-
depositor는 build input으로 사용된다. depositor를 각각 크기가 20 블록인 5개의 파티션으로 분할한다. 이 분할은 한 번(one pass)에 수행할 수 있다. n의 값이 메모리 페이지 프레임 수보다 크거나 같으면 relation을 한 번에 완료할 수 없다 (n이 20blocks 보다 크면 한 번에 못하고 recursive하게 해야한다.) ⇒ 재귀 분할 이라고 한다.
-
마찬가지로 customer를 각각 크기가 80인 5개의 파티션으로 분할한다. 이 작업도 한 번에 수행된다.
-
그러므로 총 비용은, (부분적으로 채워진 블록을 작성하는 비용을 무시한)
-
3(100 + 400) = 1500 block 전송
-
재귀 분할이 필요하지 않다!
-
Complex Joins
Join with a conjuctive condition:
-
nested loop / block nested loop 사용
-
더 간단한 중 하나의 결과를 계산한다.
-
최종 결과는 나머지 조건을 만족시키는 중간 결과의 튜플로 구성된다.
(를 제외한)
-
join with a disjunctive condition
-
nested loop / block nested loop 사용
-
개별 조인 에서 레코드의 합집합으로 계산
Complex Joins
-
다음의 세 가지 relation을 포함하는 join: join ⋈ depositor ⋈ customer

-
전략 1. depositor ⋈ customer를 먼저 계산하고, 그 결과로 loan과 join한다.
loan ⋈ (depositor ⋈ customer)
-
전략 2. loan ⋈ depositor 를 먼저 계산하고, 그 결과를 customer와 join한다.
customer ⋈ (loan ⋈ depositor)
Complex Joins (cont.)
-
전략 3. 한 쌍의 join을 한번에 수행!
-
loan-number에 대한 loan 빌드 및 인덱싱, customer-name에 대한 customer 빌드 및 인덱싱
-
depositor의 각 튜플 t에 대해, 일치하는 customer의 튜플과, 일치하는 loan의 튜플을 찾는다.
-
depositor의 각 튜플은 정확히 한 번 검사된다.
-
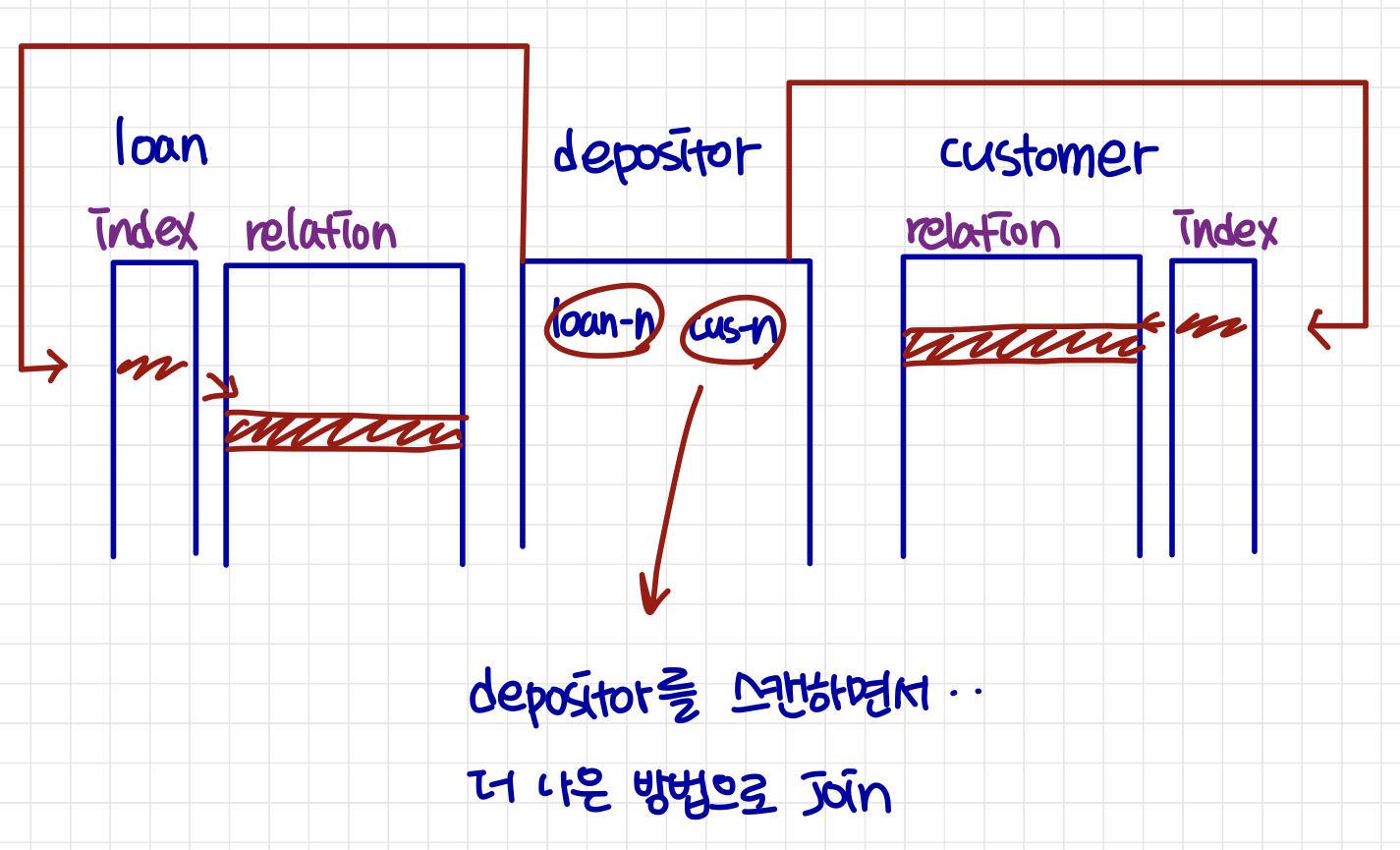
- 두 개의 relation을 두 번 join하는 것 보다 하나의 특수 목적 연산으로 더 효율적으로 두 relation을 join 할 수 있다!
Other Operations
중복 제거는 해싱 또는 정렬을 통해 구현할 수 있다.
-
정렬 시 중복 항목이 서로 인접해 있으며 한 세트를 제외한 모든 중복 항목을 삭제할 수 있다.
-
최적화: 외부 정렬-병합 의 중간 병합 단계 뿐만아니라 실행(run) 생성 중에 중복 항목을 삭제할 수 있다.
-
해싱도 비슷하다. 중복 항목은 동일한 버킷에 들어간다.
Projection 하기
- 각 튜플에서 projection을 수행한 다음 중복 제거를 수행한다.
Other Operation: Aggregation
-
집계 (aggregation)은 중복제거와 비슷한 방식으로 구현될 수 있다.
-
정렬 또는 해싱을 사용하여 동일한 그룹의 튜플을 함께 가져온 다음 각 그룹에 집계함수를 적용할 수 있다.
-
최적화: 부분 집계 값을 계산하여 실행(run) 생성 및 중간 병합 중에 동일한 그룹의 튜플을 결합한다.
-
for count, min, max, sum: 그룹에서 지금까지 발견된 튜플의 집계 값을 유지한다.
- 개수에 대한 부분 집계를 결합할 때 집계를 합산한다.
-
평균의 경우, 합계와 개수를 유지하고 끝에서 합계를 개수로 나눈다.
-
-
Evaluation of Expressions
Alternatives of evaluating an entire expression tree (전체 식 트리를 평가하는 대안)
-
Materialization(구체화): 입력이 relation이거나 이미 계산된 표현식의 결과를 생성하고 disk에 materialize(저장)한다. 그리고 이를 반복한다.
-
Pipelining: 작업이 실행되는 동안에도 부모 작업에 튜플을 전달한다.

Materialization
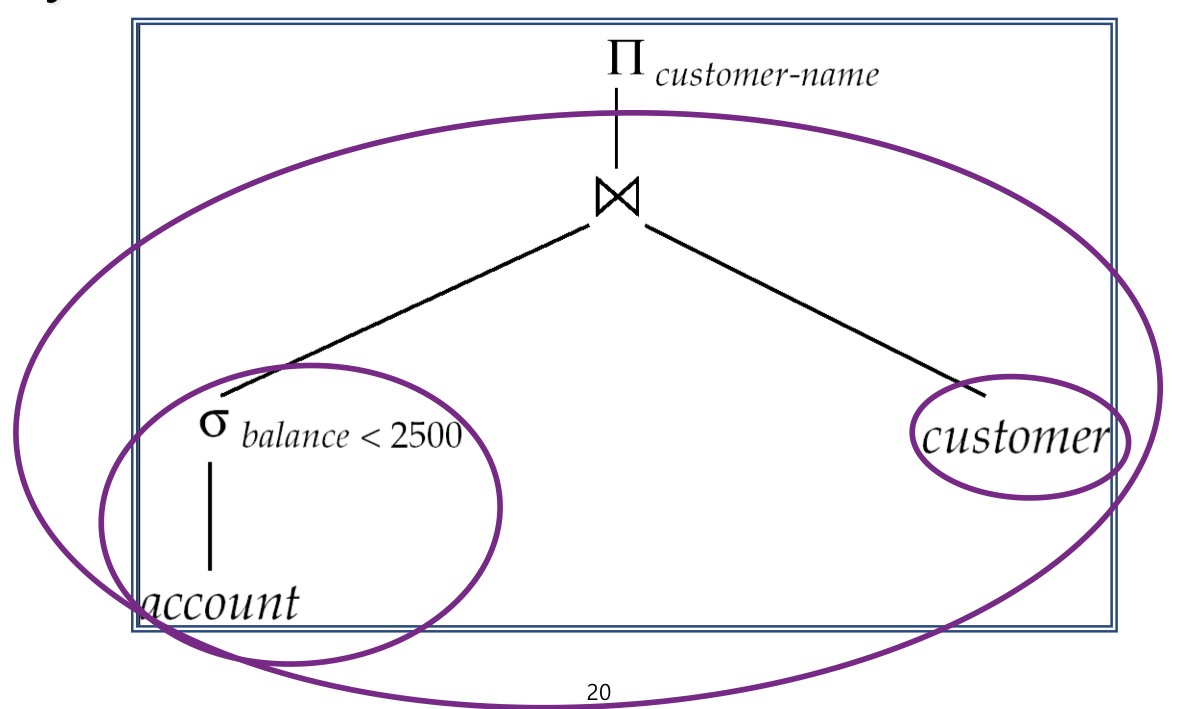
Materialization evaluation (구체화된 평가): 가장 낮은 수준에서 시작하여 한 번에 하나의 작업을 평가한다. 임시 relation으로 구체화된 중간 결과를 사용하여 다음 level의 작업을 평가한다.
(현업에서는 주로 execution plan이라고 부른다.)
- e.g. 를 계산하고 저장한다. 그 후 customer와의 Join을 저장하기 위해 계산한다. 마지막으로 customer-name에 대한 projection을 계산한다.
Materialization (Cont.)
-
Materialized evaluation은 항상 적용가능하다.
-
결과를 디스크에 쓰고 다시 읽는 비용이 상당히 높을 수 있다!
-
운영 비용 공식은 결과를 디스크에 쓰는 비용을 무시하므로 다음과 같다.
-
전체 비용 = 개별 작업 비용의 합계 + 중간 결과를 디스크에 쓰는 비용
-
Double buffering(더블 버퍼링): 각 작업에 대해 두 개의 출력 버퍼를 사용한다. 하나가 가득차면 디스크에 기록하고 다른 하나는 채워진다.
- 디스크 쓰기와 계산의 중복을 허용하고 실행 시간을 단축한다.
Pipelining
Pipelined evaluation: 여러 작업을 동시에 평가하여 한 작업의 결과를 다음 작업으로 전달한다.
-
e.g. 이전 표현식 tree에서의, 다음의 결과를 저장하지 않는다.
-
-
대신, 튜플을 join에 바로 전달한다. 마찬가지로 join한 결과를 저장하지 않고 projection을 위해 튜플을 바로 전달한다.
-
materialization 보다 훨씬 값싸다. : 디스크에 임시 relation을 저장할 필요가 없다.
-
파이프라이닝이 항상 가능한 것은 아니다 - e.g. 정렬, 해시 조인
-
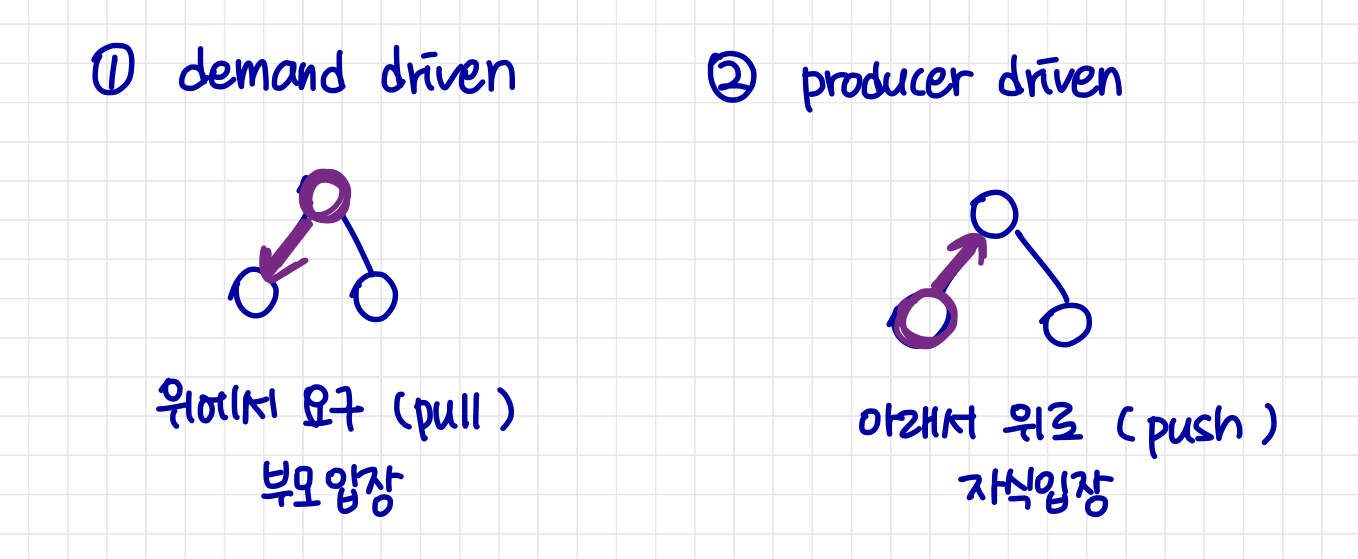
파이프라인은 두 가지 방식으로 실행될 수 있다. : demand driven, producer driven (수요 주도형, 생산자 주도형)
Pipelining (Cont.)
-
In demand driven 또는 lazy 평가 (pull model)
-
시스템이 최상위 작업에서 다음 튜플을 반복적으로 요청한다.
-
각 작업은 다음 튜플을 출력하기 위해 필요에 따라 자식 작업으로부터 다음 튜플을 요청한다.
-
호출 사이에 작업은 다음에 반환할 내용을 알 수 있도록 “상태”를 유지해야 한다.
-
-
In producer-driven 또는 eager 파이프라이닝 (push model)
-
연산자는 열심히 튜플을 생성하여 부모에게 전달한다.
-
버퍼는 연산자 사이에 유지되며 자식은 버퍼에 튜플을 넣고, 부모는 버퍼에서 튜플을 제거한다.
-
버퍼가 가득차면 자식은 버퍼에 공간이 생길 때까지 기다렸다가 더 많은 튜플을 생성한다.
-