
📝 이번 포스트는 2016년 발표된 YOLO로 알려진 "You Only Look Once: Unified, Real-Time Object Detection"논문에 대해 알아보는 시간을 갖도록 하겠습니다.
📚 background
이 논문이 발표되기 전에는 2-stage detector가 SOTA(state-of-the-art)였습니다.
2-stage Detector는 Detect 속도가 느린 반면에 mAP가 보장이 되었습니다.
이러한 시대 속에서 저자인 "Joseph Redmon"이 1-stage Detector인 YOLO(You Only Look Once)를 발표를 하였습니다.
1-stage Detector는 2-stage Detector에 비해 정확도가 떨어지는 반면에 처리 속도가 빠른 장점이 있습니다.
시대의 요구에 응하여 real-time에 가까운 객체 탐지 모델이 발표된 것입니다.
Abstract
저자는 YOLO의 모델에 대해서 설명을 하였다.
본인들이 개발한 모델은 single neural network로 bounding boxes와 class probabilities를 한번의 evaluation으로 예측이 가능하다고 한다.
YOLO는 이미지를 real-time으로 45FPS를 처리할 수 있다고 한다.
그리고 경량화 버전인 Fast YOLO는 155FPS를 처리하는 동시에 다른 real-time 객체 탐지 모델보다 두 배의 mAP 성능을 보인다고 합니다.
YOLO는 SOTA랑 비교했을 때 localization error가 많은 반면에 이미지의 배경 쪽에서 False Positive를 줄였다고 합니다.
1. Introduction
빠르고 정확한 객체 탐지 알고리즘은 차를 특정 센서에 의존 없이 주행가능하게 할 수 있죠.
이 논문이 발표되기 전 이 객체 탐지 분야의 주 모델이였던 R-CNN(2-stage Detector)은 Region proposal이라는 방식으로 바운딩 박스를 처리하고 그 다음 분류작업을 수행하는데 이 복잡한 파이프라인이 실행 속도를 늦추고 최적화하기 어렵게 하는 문제가 있었습니다.

figure 1을 보면 YOLO를 직관적으로 이해하기가 쉬울 수 있습니다.
저자는 객체 탐지를 single regression 문제로 바라보고 이미지를 동시에 바운딩 박스 좌표와 클래스 확률을 갖도록 할 수 있게 하였습니다.
저자는 YOLO의 장점 3가지를 나열하는데,
- First, YOLO is extremely fast.
Titan X GPU 가속기를 이용하여 YOLO를 inference하였을 때,
YOLO 모델은 45FPS 속도의 이미지 처리 속도를 보여준다고 합니다.
경량화버전인 Fast YOLO 같은 경우는 150FPS 속도의 이미지 처리 속도를 보여준다고 합니다.
이전 SOTA에 비하면 엄청난 속도였죠.
- Second, YOLO reasons globally about the image when making predictions.
sliding window와 region proposal 방식과 다르게 YOLO는 이미지 전체 부분을 train과 test시에 이용합니다.
결국에 저자가 하고자 하는 말은 YOLO는 Fast R-CNN과 비교했을 때, background error 수를 절반 이상으로 줄였다고 한다.
- background error란?
배경 이미지에 객체가 있다고 탐지한 것을 의미한다. 즉 False Positive를 뜻한다.
- Third, YOLO learns generalizable representations of object.
YOLO는 DPM(Deformable Part Model)과 R-CNN과 달리 general하여 새로운 도메인의 이미지가 input되어도 YOLO의 성능이 break down될 가능성이 적다고 한다.
2. Unified Detection
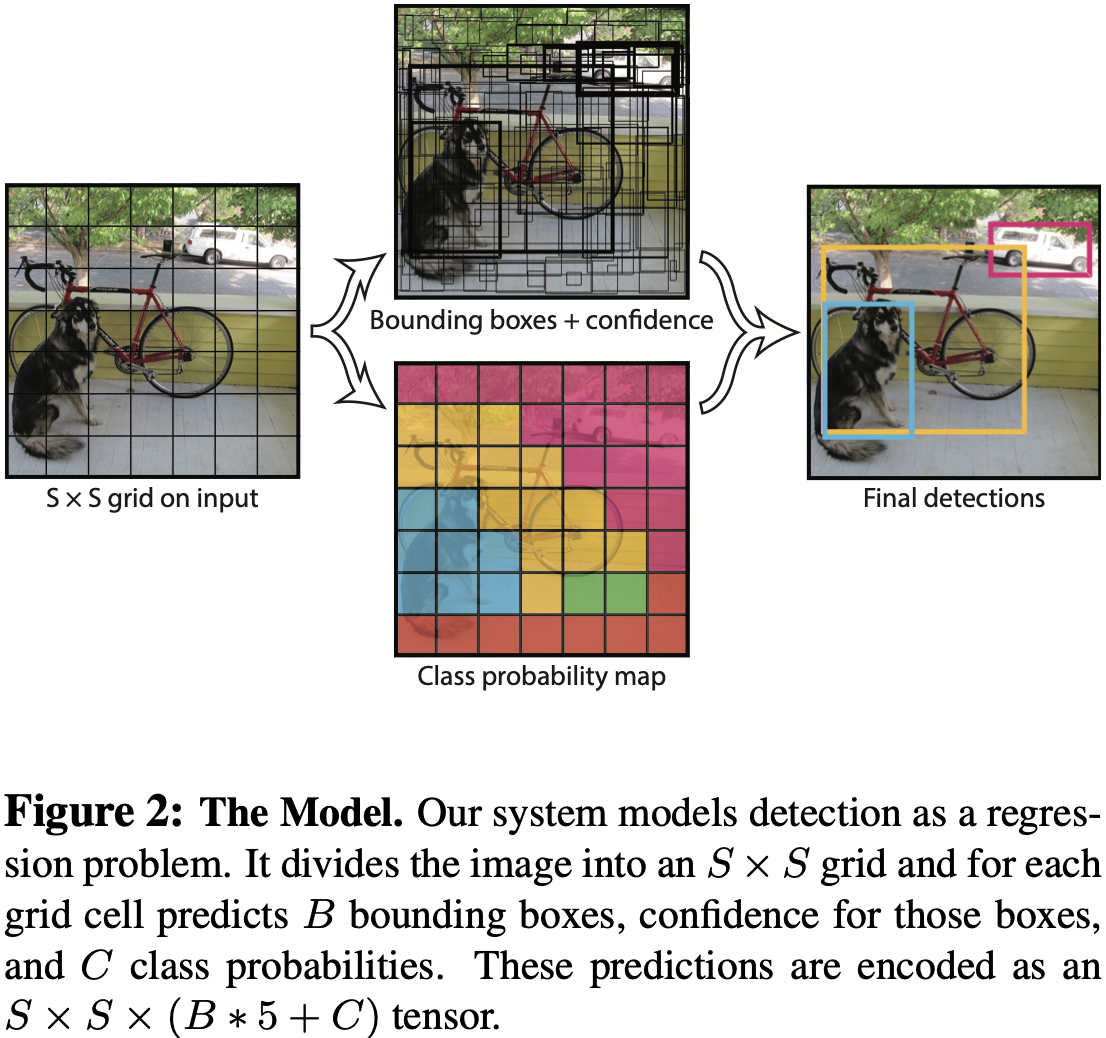
저자는 분리된 Localization과 Classification은 통합하여 single neural network로 만들었다.
YOLO는 이미지를 SS 크기의 grid로 grid cell을 만듭니다.
그리고 Confidence score를 계산합니다.
Confidence score 는 쉘에 객체가 있을 확률과 IoU를 곱한 값을 나타냅니다.
라는 공식으로 confidence score를 표현하였습니다.
✍🏻 용어 정리
: 해당 셀에 객체가 있을 확률
: prediction을 말하며, 모델이 예측한 값을 뜻함
: ground truth를 말하며,정답 레이블을 뜻함
: Intersection over Union으로, ground truth와 prediction사이의 교집합 분의 합집합을 말함
predict된 Bounding Box는 , , , , 로 구성되어 있습니다.
✍🏻 용어 정리
: Bounding Box의 중심 x좌표
: Bounding Box의 중심 y좌표
: Bounding Box의 너비
: Bounding Box의 높이
그리고 각 grid cell에서는 classification을 수행합니다.
conditional class probability인 는 Bounding Box 수와 무관하게 grid cell 당 단 한 번 만 class probability를 계산합니다.
단순히 말하면 classification이라고 할 수 있죠.
📚 조건부 확률 (conditional probability)란?
사건 B가 일어났다는 조건 하에 사건 A가 발생했을 확률
PASCAL VOC 데이터셋의 경우 , 로 이미지를 그리드셀로 나누고 각 셀 당 2개의 바운딩 박스를 택했습니다.
PASCAL VOC의 클래스 수는 20이여서 prediction 출력 값은 였다고 합니다.
2.1. Network Design
YOLO는 GoogLeNet 모델의 영향을 받아 만들어졌다고 합니다.
모델은 24개의 Convolutional Layer과 2개의 Fully-connected Layer으로 이루어졌습니다.
GoogLeNet과 같이 1x1 reduction Layer을 사용한다고 합니다.

📚 1 1 reduction Layer란?
GoogLeNet에서 1 1 Convolutional Layer를 처음 사용하였는데,
GoogLeNet 논문에서 1 1 필터가 효율적임을 증명하였습니다.
1 1 필터가 파라미터 수를 줄여서 연산량을 줄이는 데 도움을 줬다고 증명하였습니다.
경량화 버전인 Fast YOLO같은 경우는 Convolutional Layer를 24개 대신 9개로 줄이고 필터의 개수도 줄였다고 합니다.
2.2. Training
YOLO 모델은 ImageNet 2012로 validation 했을 때, top-5 accuracy를 88% 달성했다고 합니다.
Darknet 프레임워크를 사용했구요.
그리고 activation 함수로 Leaky ReLU를 사용했다고 합니다.
모델을 학습시킬 때 epoch = 135이고 train과 validation 시에는 PASCAL VOC 2007과 2012를 둘 다 사용하였고, test시에는 VOC 2012를 사용하였다고 합니다.
모델 하이퍼 파라미터는 batch size = 64, momentum = 0.9, decay = 0.0005, learning rate는 75 epoch까지는 , 그 다음 76 ~ 105 epoch는 , 그 다음 106 ~ 135 epoch은 식으로 learning rate를 줄여가며 gradient를 stable하게 갖는 방식을 사용했다고 합니다.
오버피팅을 피하기 위해 dropout과 data augmentation을 진행했습니다.
dropout rate = 0.5이고,
랜덤하게 원본 이미지의 최대 20%까지 scaling하는 방법도 갖었습니다.
그리고 이미지의 exposure와 saturation을 랜덤하게 최대 1.5배까지 적용하는 data augmentation 방법을 사용하여 train을 수행하였습니다.
2.3. Inference
Inference 시에는 PASCAL VOC 데이터셋 사용 시 한 이미지 당 98개의 Bounding Box와 각 bounding box 별로 class probability를 predict한다고 합니다.
2.4. Limitations of YOLO
YOLO의 제약사항은 한 grid cell 당 2개의 bounding box와 하나의 클래스밖에 갖을 수 없는 것입니다.
한 grid cell 당 2개 이상의 물체를 탐지하기 어렵다는 뜻이죠.
그리고 세 때와 같은 조그만 물체는 탐지를 못 한다고 합니다.
그리고 새로운 비율의 객체나 특이한 비율의 객체를 일반화하기가 힘들다고 합니다. (저는 이 문제점이 학습 단계에서 충분한 데이터셋으로 학습이 이루어지지 못해서 발생한 문제라고 생각합니다.)
3. Comparison to Other Detection Systems
이 부분에서는 다른 모델들과 비교하여 YOLO의 장점을 설명합니다.
-
첫 번째로 비교했던 대상은 Deformable Parts Models(DPM)입니다.
DPM은 sliding window 방식으로 localization task에 접근하는 모델입니다.
DPM은 feature extraction, bounding box prediction, non-maximal suppression, contextual reasoning을 별개의 단계로 각각 수행합니다.
이 DPM과 비교하여 YOLO는 통일된 아키텍쳐를 사용하여 빠른 이미지 처리 능력을 갖고, DPM 모델보다 더 정확한 성능을 보여줬다고 합니다. -
두 번째로 R-CNN과 비교합니다.
R-CNN은 DPM과 다르게 sliding window 방식을 사용하지 않고 region proposal 방식을 사용하는 아키텍쳐입니다.
selective search방식은 potential한 바운딩 박스를 생성하고, Convolutional network가 특징을 추출하고, SVM(Support Vector Machine)이 박스를 평가하고, linear model이 바운딩 박스를 업데이트하고, NMS(Non Maximum Suppression)으로 중복되는 박스를 제거하는 과정을 갖습니다.
과정을 설명하는데도 복잡함이 느껴집니다...
실제로 R-CNN 아키텍쳐가 tes time 시에 40 second per image가 걸린다고 합니다. real-time과는 거리가 멀죠.
R-CNN의 Selective Search는 이미지당 2000개를 생성하지만, YOLO는 98개를 생성하여 훨씬 메모리 할당량을 줄일 수가 있죠.
어떻게 98개란 숫자가 나왔냐면, 이미지를 그리드셀로 나누고 한 그리드셀 당 개의 박스를 생성하기로 했는데 논문의 저자는 로 설정하였으니 이 되는 겁니다. -
Fast RCNN, Faster RCNN과 비교합니다.
RCNN에 비해 향상된 속도와 정확도를 갖지만 여전히 real-time에 못 미치므로 YOLO가 우월하다고 합니다. -
MultiGrasp라는 자신의 이전 모델에서 Gridcell 개념을 가져왔다고 합니다.
MultiGrasp 모델은 객체의 크기나 위치 클래스가 무엇인지는 중요하지 않았고, 단지 graspable region만을 찾기 위한 모델이였다고 합니다.
4. Experiments
이 부분에서는 YOLO를 다른 real-time detector와 비교를 했다고 설명합니다.
즉, R-CNN 계열과의 비교를 뜻하죠.
YOLO는 2-stage detector의 SOTA인 R-CNN 대항마로 세상에 나온 모델이니까요😅.
비교에 공통적으로 사용된 데이터셋은 PASCAL VOC 2007과 2012입니다.
4.1. Comparison to Other Real-Time Systems
이 부분에서는 수치를 통해 다른 real-time detector와 비교하여 YOLO가 더 좋은 모델임을 증명합니다.
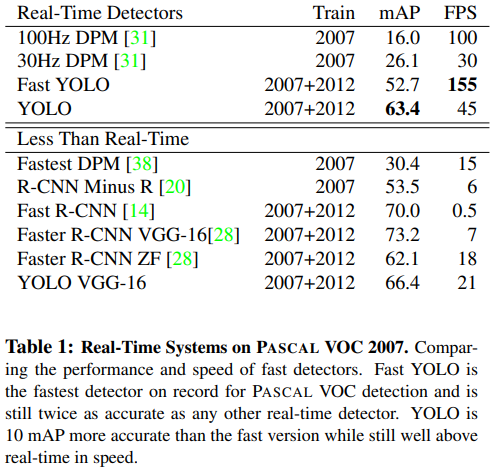
-
30Hz DPM & 100Hz DPM
30Hz DPM은 FPS가 30인 모델이고 100Hz DPM은 FPS가 100인 모델을 뜻합니다.
100Hz DPM이 30Hz DPM보다 속도면에서 빠르지만 정확도는 많이 떨어집니다.
FPS를 보면 각각 100, 30이고 mAP는 16.0, 26.1인 것을 확인할 수 있습니다.
둘 다 YOLO와 비교했을 때 mAP가 많이 떨어집니다. -
Fast YOLO
Fast YOLO는 현존하는 모델들 중 가장 빠른 속도를 보여주는 모델입니다.
Table 1.을 보면 FPS가 155인 것을 확인할 수 있습니다.
30Hz DPM보다 mAP가 2배임을 보여주고, FPS는 더할 나위 없죠. -
Fastest DPM
DPM모델의 속도를 올린 모델입니다.
이 모델은 mAP면에서 감소하지는 않았지만 속도면에서 FPS가 1/2로 줄은 것을 확인할 수 있습니다.
YOLO에는 충분히 못 미치죠. -
R-CNN minus R
이 모델은 selective search 매커니즘을 static bounding box proposal 매커니즘으로 변경한 R-CNN모델입니다.
R-CNN보다는 빠른 모델이지만 정확도는 저하됩니다. -
Fast R-CNN
R-CNN을 classification 단계에서 속도를 증가시킨 모델입니다.
여전히 selective search 방식을 사용하는데 2초당 이미지 1장을 처리할 수 있다고 합니다.
그러면 FPS가 0.5인거죠... 상당히 최악의 모델입니다...😅 -
Faster R-CNN
이 모델은 selective search방식을 propose bounding box 방식으로 대체한 모델입니다.
Faster R-CNN모델을 두가지 종류의 모델을 비교 실험하였는데,- VGG-16 아키텍쳐를 사용한 Faster R-CNN VGG-16은 YOLO에 비해 mAP가 10 정도 높으나 속도면에서는 약 6배 느립니다.
- Zeiler-Fergus가 개발한 Faster R-CNN ZF는 YOLO에 비해 mAP가 비슷하나 속도면에서 약 2.5배 느립니다.
4.2. VOC 2007 Error Analysis

이 파트에서는 YOLO와 그 당시의 SOTA였던 Fast R-CNN을 VOC 2007 데이터셋을 기준으로 비교실험했던 것을 설명합니다.
평가 요소는 각 모델의 Correct, Localization, Similar, Other, Background의 비율을 비교했습니다.
- Correct : 클래스를 맞추고 predicted bounding box와 ground-truth간의 IoU > 0.5를 만족하는 prediction을 뜻합니다.
- Localization : 클래스를 맞추고 predicted bounding box와 ground-truth간의 0.1 < IoU < 0.5를 만족하는 prediction을 뜻합니다.
- Similar : 클래스는 틀렸지만 비슷한 종류의 클래스(ex. dog클래스가 정답레이블이지만 wolf?라고 답한 케이스)라고 답하고 0.1 < IoU를 만족하는 prediction을 뜻합니다.
- Other : 클래스는 틀렸지만 0.1 < IoU를 만족하는 prediction을 뜻합니다.
- Background : 0.1 < IoU 인 prediction을 뜻함.(False Positive를 뜻함)
일 때, Figure 4를 보면 Fast R-CNN과 YOLO가 어떤 구성을 갖는지 보여줍니다.
YOLO는 Localization error가 꽤 큰 편입니다. 그 이외의 에러들을 합했을 때보다도 높죠.
이것이 YOLO의 가장 큰 단점이라고 할 수 있습니다. 왜냐하면 실시간에 가까운 처리속도를 갖는 대신 optimize단계를 낮춘 1-stage detector이 때문에 자명한 사실이 됩니다.
실제로 위로 올라가 Table 1을 살펴보면 Fast-RCNN은 mAP가 70.0이지만 YOLO는 mAP가 63.4인 것을 확인할 수 있죠.
Fast R-CNN의 Background error가 YOLO의 약 3배 큰 것을 확인할 수 있습니다.
4.3. Combining Fast R-CNN and YOLO
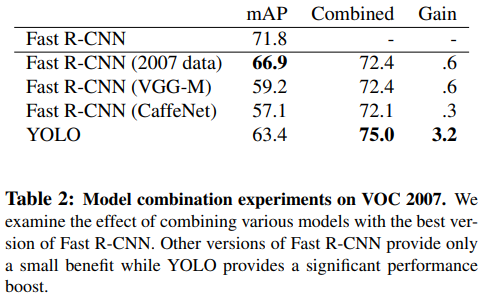
이 파트에서는 Fast-R-CNN과 다른 모델들을 결합했을 때 어떤 performance를 보이는지 말합니다.
위의 Table 2를 보면 알 수 있듯이 Fast R-CNN의 mAP는 71.8인데 YOLO와 결합했을 때 75.0을 보여줍니다.
다른 모델들도 각 모델들 원래 mAP보다 다들 증가한 것을 확인할 수 있죠.
4.4. VOC 2012 Results
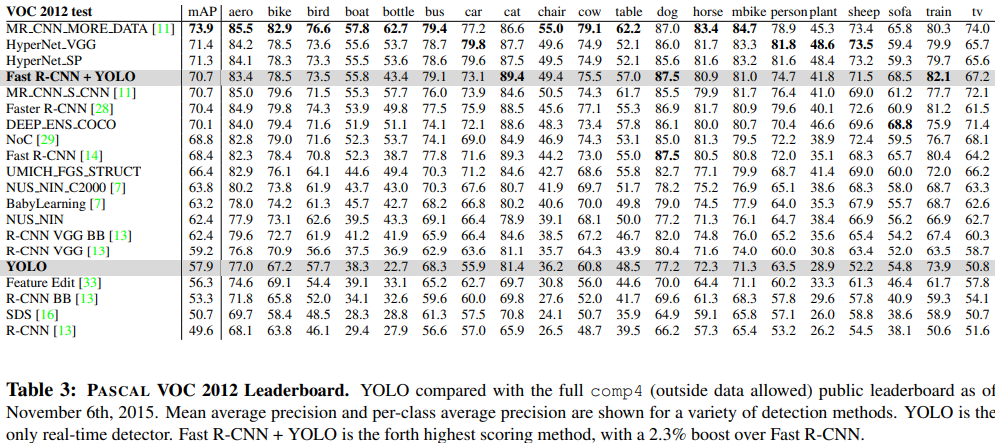
이 파트에서는 VOC 2012 데이터셋으로 학습했을 때 각 모델들의 mAP와 클래스별 AP를 비교한 것을 보여줍니다.
이 실험에서는 처리 속도를 제외한 오로지 탐지 성능 지표인 mAP만 따졌습니다.
위 Table 3는 mAP leaderboard입니다. 높은 mAP순으로 나열한 표이죠. 그래서 처음 들어보는 모델이 랭킹이 가장 높은 것입니다.
이 파트에서 말하고자 하는 것은 YOLO로는 속도가 우월하게 빠르지만 mAP면에서는 다소 많이 떨어지지만, Fast R-CNN과 결합하면 TOP 4에 드는 mAP를 보여준다고 합니다.
4.5. Generalizability: Person Detection in Artwork
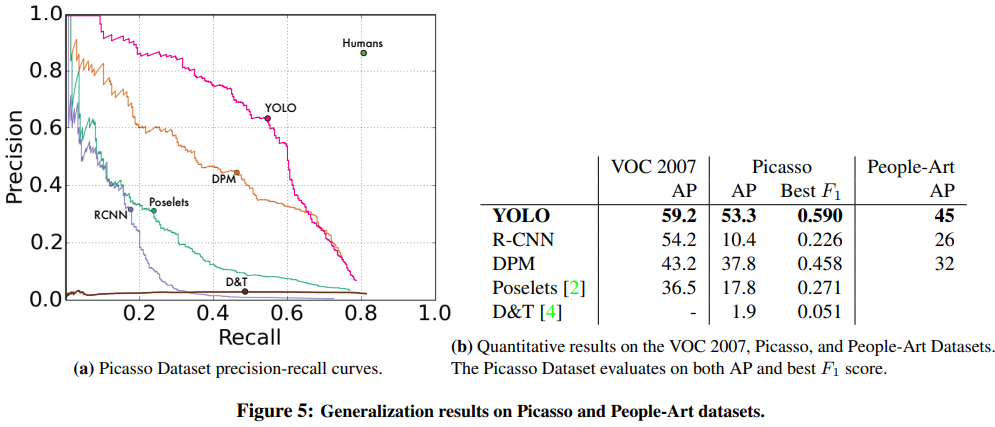
이 파트에서는 YOLO와 다른 object detector들을 VOC 2007, Picasso Dataset, People-Art Dataset을 기반으로 "Person"클래스의 AP를 비교하는 실험을 보여줍니다.
Figure 5의 (a)를 보면 각 모델별로 사람을 탐지하는 성능을 Average-Precision 그래프로 보여줍니다.
각 YOLO가 가장 인간의 인지능력에 가까운 성능을 보입니다.
그리고 (b)를 보면 Picasso dataset으로 test한 경우는 VOC-2012 데이터셋으로 train하였고,
People-Art dataset으로 test한 경우는 VOC-2010 데이터셋으로 train하였고,
그 이외의 나머지 VOC-2007으로 test한 경우는 같은 VOC-2007 데이터셋으로 train하여 실험을 진행했다고 합니다.
(b)를 보면 R-CNN 같은 경우는 훈련과 테스트 둘 다 똑같은 데이터셋(VOC2007)을 썼을 경우 비교적 높은 AP를 보여주지만, 훈련 때 사용한 데이터셋(VOC2012)과 다른 Picasso데이터셋으로 테스트했을 때는 급격하게 감소한 AP를 볼 수 있습니다.
하지만 YOLO같은 경우는 훈련과 테스트를 다른 데이터셋으로 사용했을 때 같은 데이터셋으로 사용했을 때에 비해 AP를 잘 유지하는 것을 볼 수 있습니다.
이 이유는 R-CNN의 selective-search가 오직 작은 region과 좋은 proposal을 요구하고, YOLO의 grid cell 방식이 다양한 사이즈와 형태의 객체를 찾을 수 있어서 라고 합니다.
5. Real-Time Detection In The Wild
YOLO 모델을 웹캠 카메라에 연결하여 test를 해보았다.
결과는 되게 만족스러운 결과였다.
마치 트래킹 시스템처럼 객체의 움직임과 변화를 감지하는 것 같았다.
6. Conclusion
여태까지 말한 YOLO모델의 장점을 설명한다.
real-time 성능을 보여주고,
Fast-YOLO는 엄청난 처리 속도를 보여주는 Object Detector의 SOTA로 자리매김하였다.
