Diffusion Language Models?
Large Language Diffusion Models라고 부르기도 하므로 Diffusion-LM도 LLM이지만, 혼선을 방지하기 위해 꼭 Diffusion 용어를 붙여주는게 좋겠다. 이전에 썼던 글에 LLM의 정의를 고찰한 적이 있는데, 개인적으로는 아직도 현업에서 용어의 혼동이 잦은 것 같다.
Diffusion-LM은 시장을 주도하고 있는 GPT같은 Autoregressive 모델과 다르다. 이것은 Non-autoregressive 모델로서 출력을 한꺼번에 생성할 수 있다. 대중적인 모델은 아니지만 최근 성능이 좋아지고 있어서 여러가지 이점과 함께 관심이 높아지고 있다. 일단 나는 블로그에 나오는 아래 GIF를 보고 신기해서 더 알아보기로 마음먹었다.
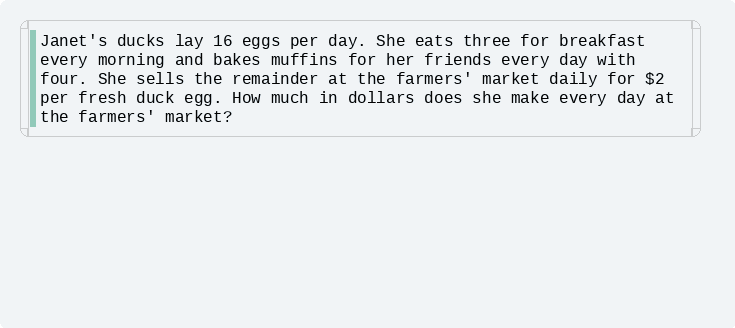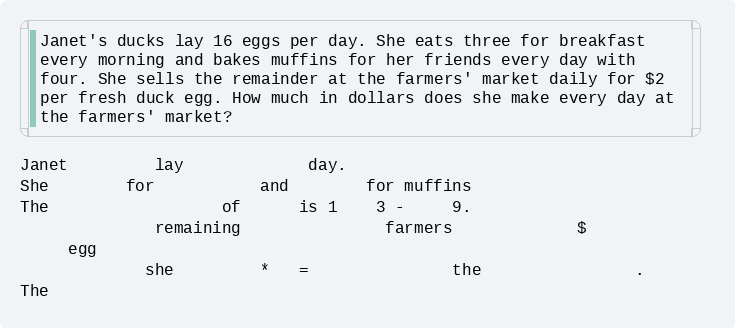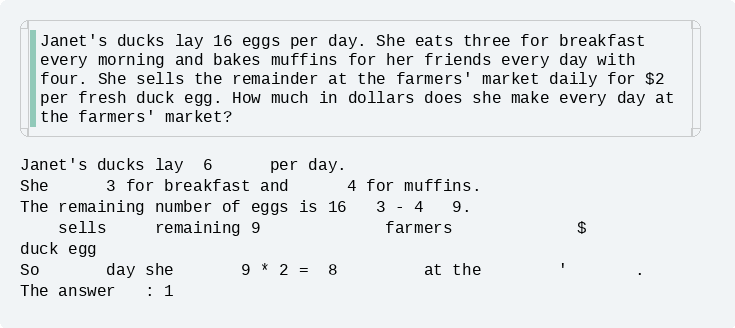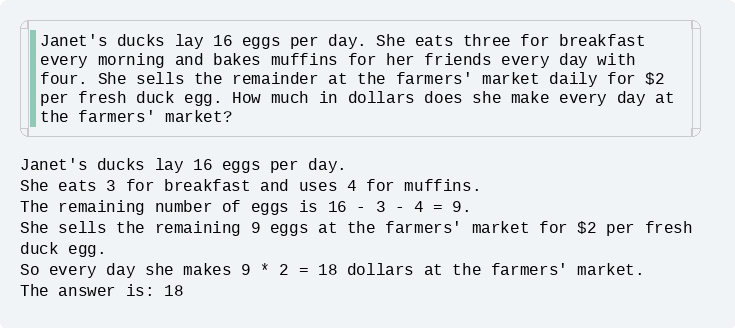
 ...? 토큰이 중간부터 생기네?
...? 토큰이 중간부터 생기네?
Diffusion-LM의 원리
전문적인 내용은 논문을 참고
대체 어떻게 중간에 있는 토큰부터 출력이 되는걸까? 물론 실제로는 토큰이 갑자기 중간에서 생성된 것이 아니라 전체 토큰들이 서서히 선명해진 것이다.

이는 이미지 생성 모델인 Stable Diffusion의 기본 원리와 비슷하다. 멀쩡한 데이터에 노이즈를 단계별로 주고, 각 단계에서 노이즈를 줄이는 방향으로 모델을 학습하게 된다. 이미지 출처
Diffusion-LM
Diffusion-LM starts with a sequence of Gaussian noise vectors and incrementally denoises them into vectors corresponding to words, as shown in Figure 1

Gaussian noise 벡터로 시작해서 점진적으로 노이즈를 줄여나가게 된다. 마지막에는 연속적인 벡터값에서 이산적인 단어(토큰)값이 되기 위해 Rounding 과정이 필요하다. Non-autoregressive 모델이므로 모든 토큰을 병렬로 처리할 수 있다.
Autoregressive-LM
RNN이나 GPT같은 자기회귀형 언어 모델은 이전 입력()으로 다음 출력()을 예측하는 것이다. 토큰들은 병렬로 생성될 수 없고, 재귀적으로 계속 생성 가능하므로 문장의 끝에 EOS토큰을 출력하도록 학습이 필요하다.
Diffusion-LM 실행 예제
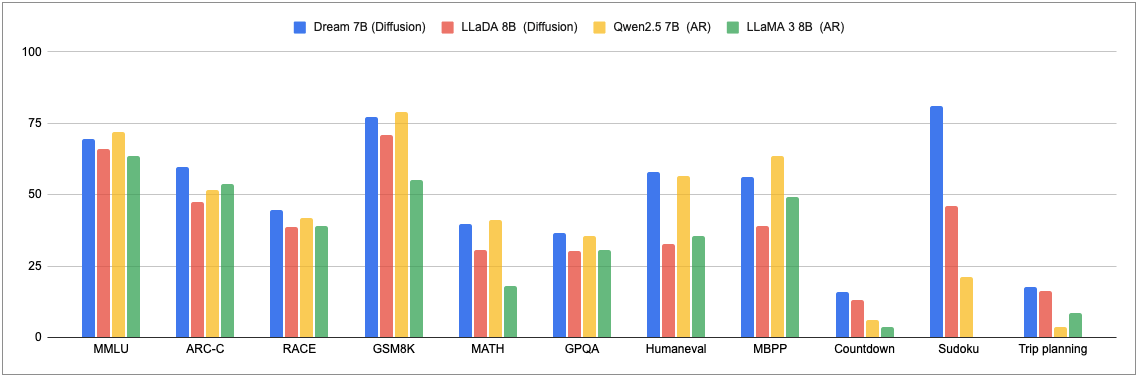
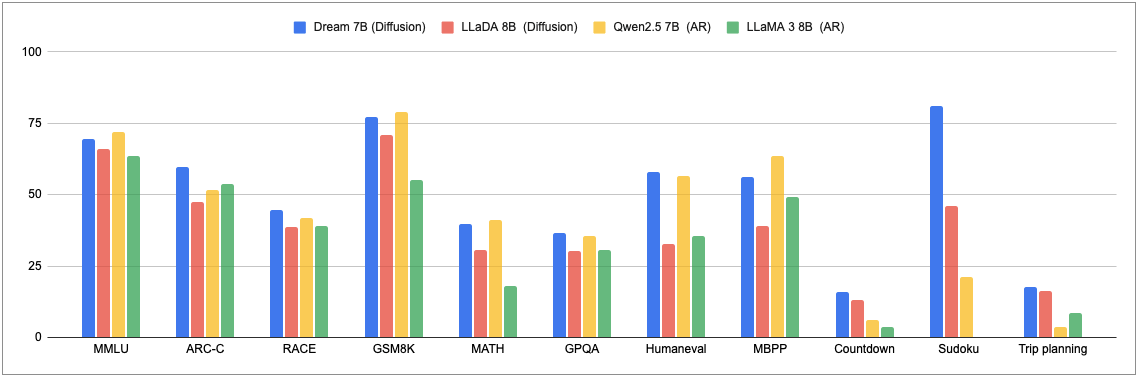
위에서도 언급한 Dream 7B를 실행해보았다. 아래 차트를 보면, 다른 Diffusion 및 AR(Autoregressive)모델들과 비교했을때 성능이 나쁘지 않아 보인다.
깃허브의 예제 코드를 약간 수정해서 수원이 어느 나라에 있는 도시인지 물어보았다.
의외로 라이브러리 버전에 따라 오류가 많이 발생했는데,
diffusion_generate()자체가 잘 안쓰이는 API여서 그런건 아닐까 추측해본다.
아래 코드는pytorch==2.8.0,transformers==4.46.2에서 실행되었다.
Dream 7B 예제 코드
import torch
from transformers import AutoModel, AutoTokenizer
model_path = "Dream-org/Dream-v0-Instruct-7B"
model = AutoModel.from_pretrained(model_path, torch_dtype=torch.bfloat16, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = model.to("cuda").eval()
messages = [
{"role": "user", "content": "Which country is the city of Suwon located in?"}
]
inputs = tokenizer.apply_chat_template(
messages, return_tensors="pt", return_dict=True, add_generation_prompt=True
)
input_ids = inputs.input_ids.to(device="cuda")
attention_mask = inputs.attention_mask.to(device="cuda")
output = model.diffusion_generate(
input_ids,
attention_mask=attention_mask,
max_new_tokens=8,
output_history=True,
return_dict_in_generate=True,
steps=16,
temperature=0,
top_p=1,
alg="origin",
alg_temp=0.,
)
generations = [
tokenizer.decode(g[len(p) :].tolist())
for p, g in zip(input_ids, output.sequences)
]
print(len(input_ids[0]))
print(len(output.sequences[0]))
print(len(output.sequences[0]) - len(input_ids[0]))
print(generations[0])결과
30
38
8
Suwon is located in South Korea.여기서는 출력 토큰 수(8)가 max_new_token과 동일하지만 일반적으로는 필요한 토큰만 생성하고 나머지는 <|endoftext|>토큰으로 출력된다. 여기서 재밌는건 output_history=True 파라미터인데, 이걸 활성화하면 아래와 같이 출력 시퀀스의 생성과정을 볼 수 있다.
history 확인 코드
step_outputs = []
for step_output in output.history:
step_output_ids = step_output[0][len(input_ids[0]):]
decoded_output = tokenizer.decode(step_output_ids)
step_outputs.append(decoded_output)
for step, text in enumerate(step_outputs):
print(f"Step {step + 1}:\n{text}\n{'='*50}")결과
Step 1:
<|mask|><|mask|><|mask|><|mask|><|mask|><|mask|><|mask|><|mask|>
==================================================
Step 2:
<|mask|><|mask|><|mask|><|mask|><|mask|> South<|mask|><|mask|>
==================================================
Step 3:
<|mask|><|mask|><|mask|><|mask|><|mask|> South<|mask|><|mask|>
==================================================
Step 4:
<|mask|><|mask|><|mask|><|mask|><|mask|> South<|mask|><|mask|>
==================================================
Step 5:
<|mask|><|mask|><|mask|><|mask|><|mask|> South<|mask|><|mask|>
==================================================
Step 6:
<|mask|><|mask|><|mask|><|mask|><|mask|> South<|mask|><|mask|>
==================================================
Step 7:
<|mask|><|mask|><|mask|><|mask|><|mask|> South<|mask|><|mask|>
==================================================
Step 8:
<|mask|><|mask|><|mask|><|mask|><|mask|> South Korea<|mask|>
==================================================
Step 9:
<|mask|><|mask|> is<|mask|><|mask|> South Korea<|mask|>
==================================================
Step 10:
Su<|mask|> is<|mask|><|mask|> South Korea<|mask|>
==================================================
Step 11:
Su<|mask|> is<|mask|><|mask|> South Korea.
==================================================
Step 12:
Su<|mask|> is<|mask|><|mask|> South Korea.
==================================================
Step 13:
Suwon is<|mask|> in South Korea.
==================================================
Step 14:
Suwon is<|mask|> in South Korea.
==================================================
Step 15:
Suwon is<|mask|> in South Korea.
==================================================
Step 16:
Suwon is located in South Korea.
==================================================기대한 것과 같이 단계적으로 토큰들이 예측됨을 확인할 수 있다.

여기서 주의할 점은 step이 충분하지 않다면 <|mask|> 토큰이 남아있을 수 있다. Stable Diffusion도 step을 적게줄 경우 이미지가 뭉개져있는 것을 생각해보면 적절한 step 수를 찾는 것이 중요해보인다. (step이 너무 길면 시간이 오래걸릴 수 있다.)
이미지 출처
