
RunPod?
런팟은 GPU 클라우드 서비스다. 여기에 돈을 내고 GPU를 대여할 수 있고, GPU로 AI 모델을 학습시키거나 서빙(배포)할 수 있다. AWS, GCP 등 대표적인 클라우드 서비스들도 GPU 인스턴스를 제공하지만 가성비는 이쪽이 우위다.
GPU가 필요한 이유
딥러닝 모델의 학습과 추론에는 행렬 연산의 비용이 가장 크다. 행렬 연산은 병렬로 처리 가능한데, 마침 GPU(Graphics Processing Unit)가 병렬 연산에 적합했다. 지금도 GPU를 사용하면 동일 가격대의 CPU보다 월등히 빠른 속도로 딥러닝 연산이 가능하다.
CPU와 GPU의 연산 방식 차이는 아래 영상을 통해 직관적으로 이해할 수 있다.
GPU 클라우드를 사용하는 이유 (=돈)
GPT3를 시작으로 LLM(Large Language Model)들의 크기(=매개변수)는 급격히 증가했고, 이로 인해 아주 많은 메모리와 연산량이 필요해졌다. 더 이상 저렴한 GPU로는 감당할 수 없는 규모가 되었다.
우리가 실험삼아 LLM을 써보기에 CPU는 너무 느리고, GPU는 너무 비싸다. CPU를 쓰자니 대역폭과 연산량이 받쳐주지 못하고 GPU를 쓰자니 너도나도 쓰려고 해서 너무 비싸다. 심지어 최근 RTX5000번대 출시 이후, 4090같은 소비자용 GPU들의 중고 가격이 올랐다. (가격이 점점 비싸지는 전자제품은 처음봤다.)
런팟과 같은 GPU 클라우드를 이용하면 RTX 4090기준 시간당 1달러 미만으로 GPU를 대여할 수 있다. 타 클라우드 서비스들과 마찬가지로 일정 기간 약정을 하면 더 저렴하지만, 24시간 사용할 것이 아니므로 공부용도로 약정은 적합하지 않다.
Google Colab도 나쁘지 않은 선택지라고 생각한다. 다만 무료버전으로는 좋은 GPU(TPU)를 쓸 수 없어서 결제가 필수인데, 런팟보다 가성비가 떨어진다.
사전 준비 : 크레딧 충전하기
해외 결제가 가능한 카드가 필요하다. RunPod 홈페이지에서 회원 가입 후 크레딧을 충전할 수 있다.
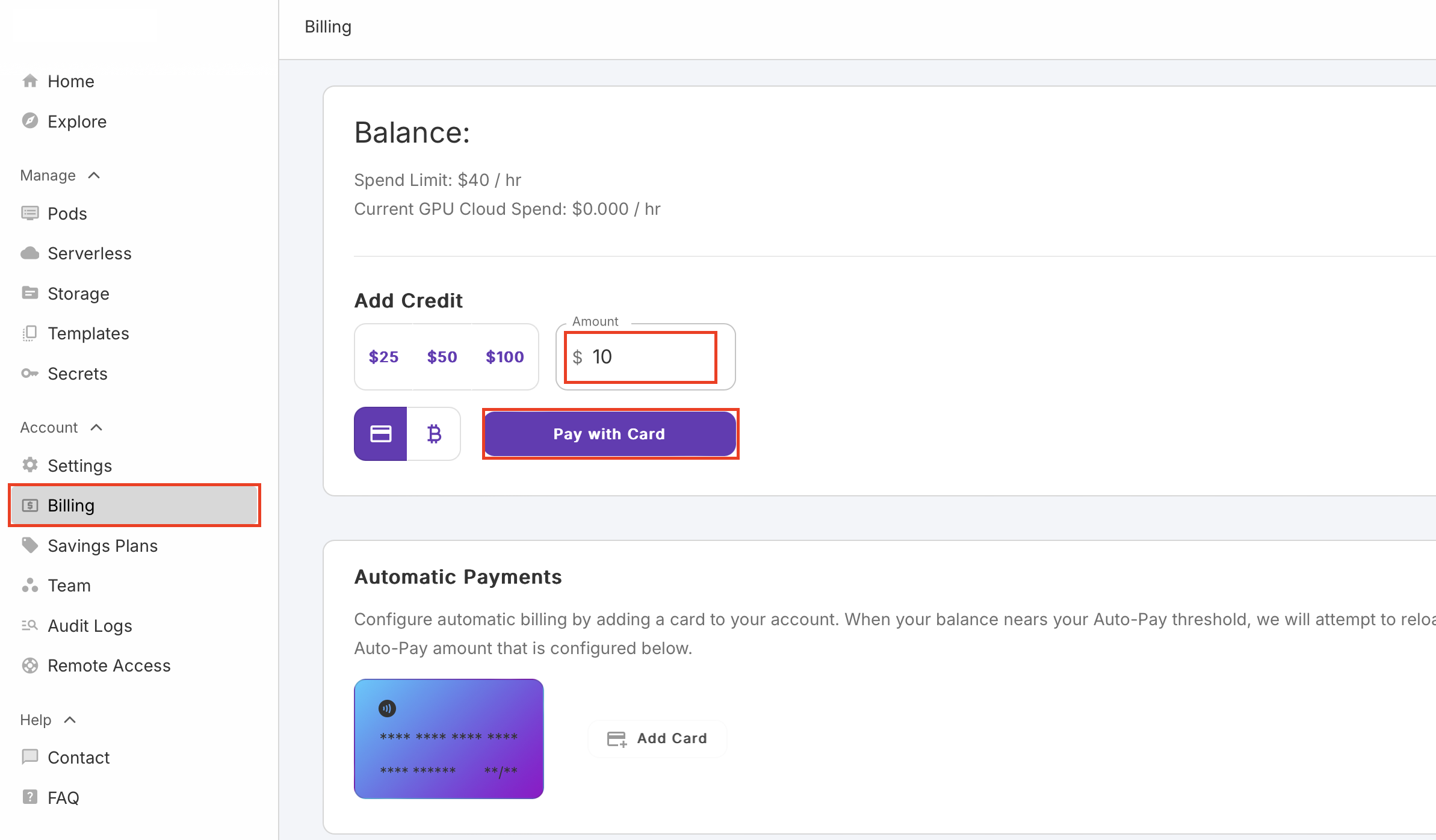
Account - Billing 에서 충전 가능하다.
일단 최소 금액인 10$를 충전했다.
1. Pod 준비하기
Pod은 컨테이너 인스턴스를 실행하는 단위이다. 자세한 내용은 여기를 참조.
원본 글 : 아카라이브
(1) 미리 준비된 템플릿으로 가서 Deploy 버튼 클릭

(2) 원하는 GPU 선택
테스트 용도이므로 4090으로도 충분하다.
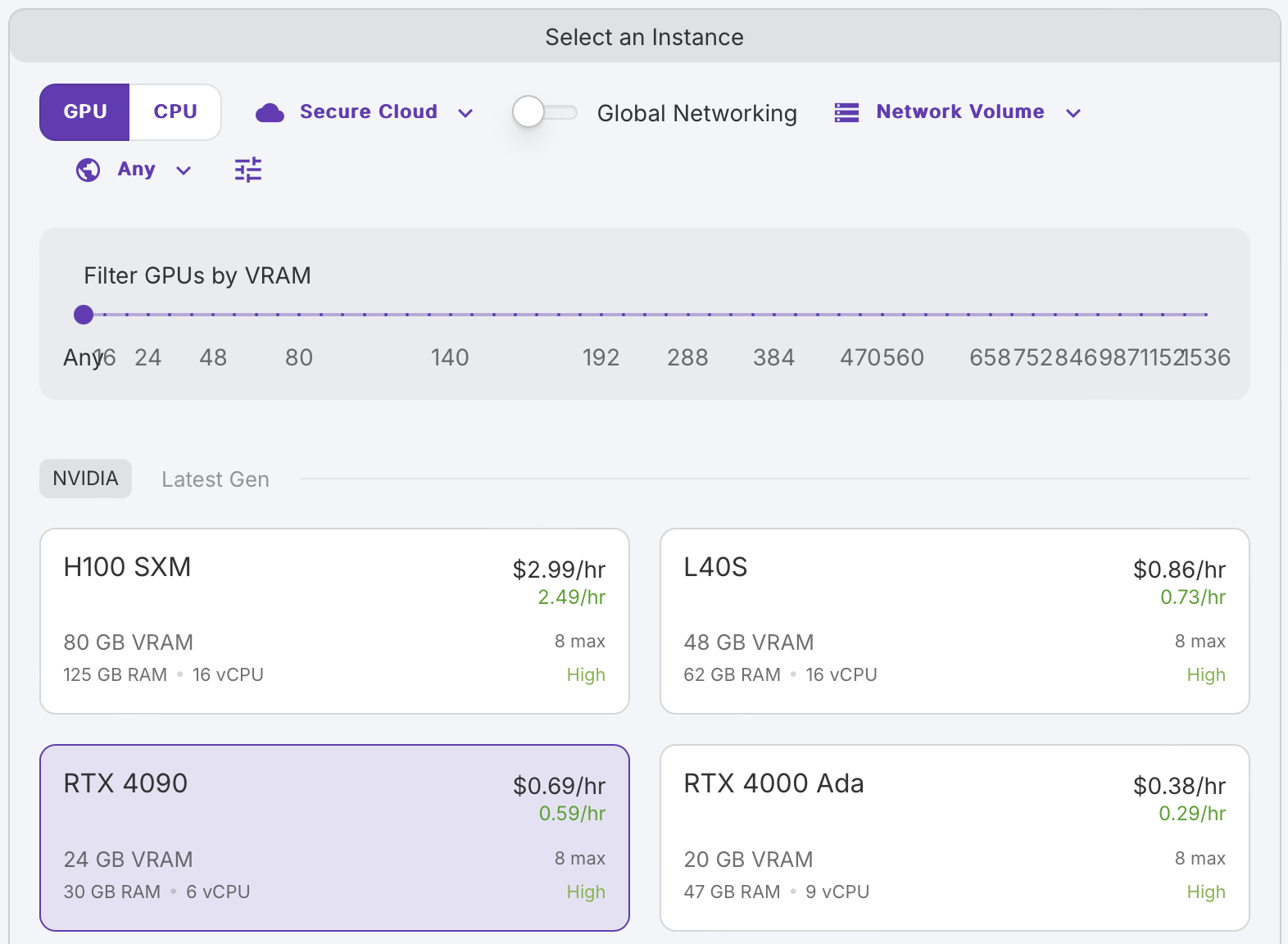
Secure Cloud? Community Cloud?
인스턴스 선택시 둘 중 하나를 선택할 수 있는데, 보통 Community Cloud가 더 저렴하다.
Secure Cloud는 일반적으로 데이터센터에서 제공되고, Community Cloud는 일반 사용자에 의해 호스팅 되는 것으로 보인다. 높은 가용성을 위해서라도 Secure Cloud를 사용하자. 자세한 내용은 여기를 참조
(3) GPU 개수와 요금 플랜 선택
여기서는 GPU 1개를 On-Demand 요금으로 생성한다.
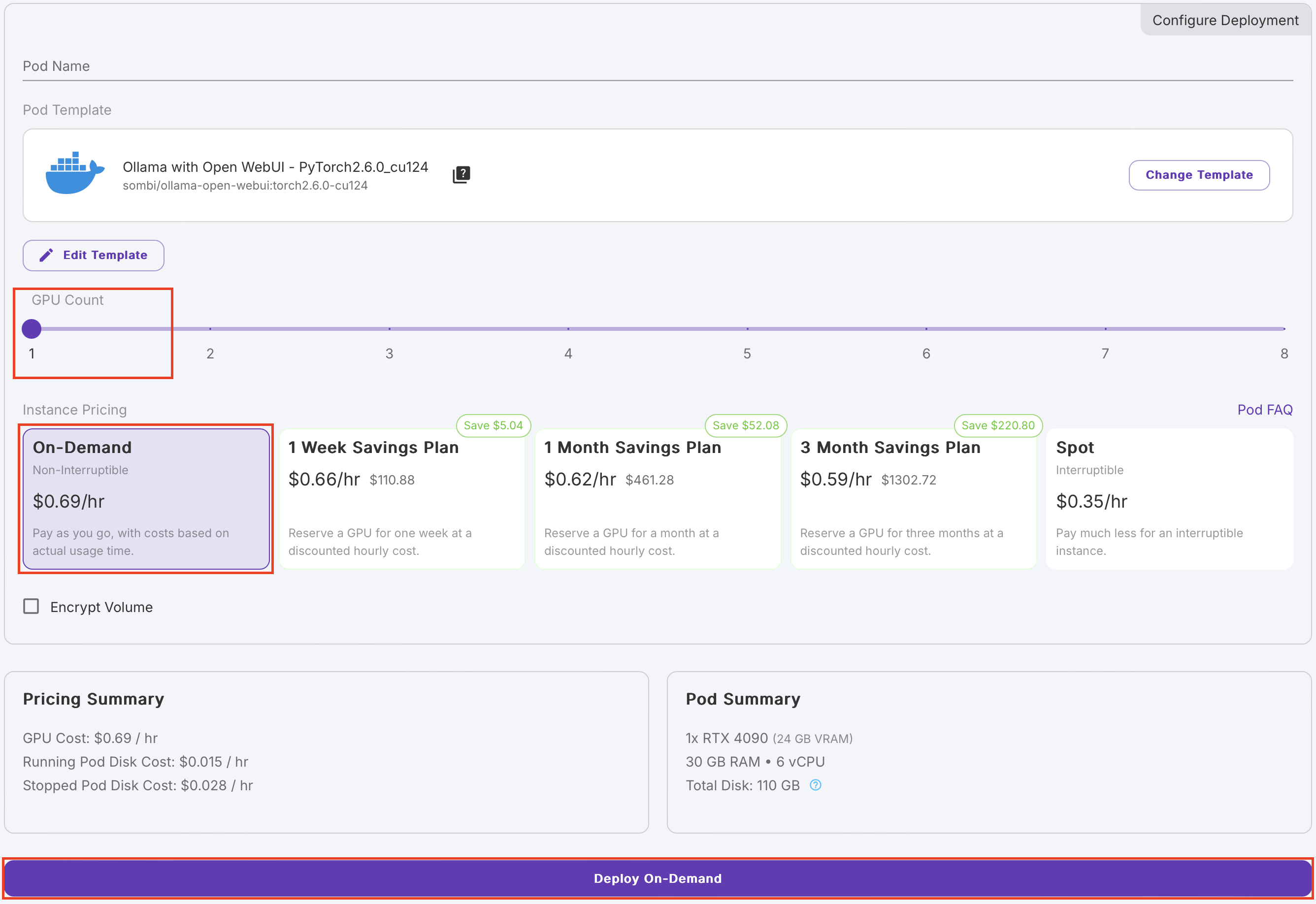
5분 정도 기다리면 실행중인 Pod을 확인할 수 있다.

2. 접속 & 모델 다운로드
(1) Connect 클릭
여기서는 Pod의 상태를 확인할 수 있는데, 연산이 너무 느리면 GPU를 안쓰고 CPU만 사용중인지 확인해보자.
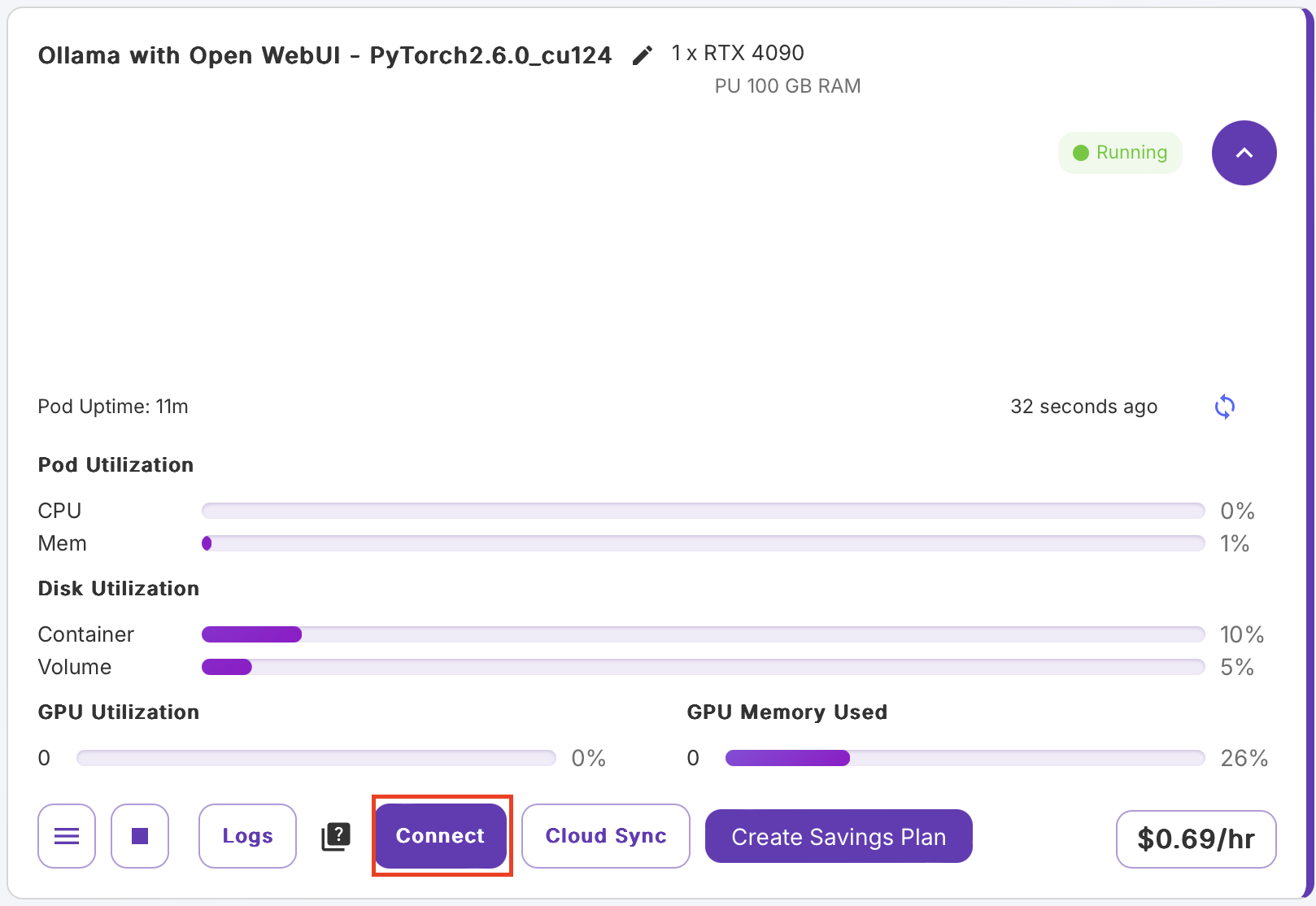
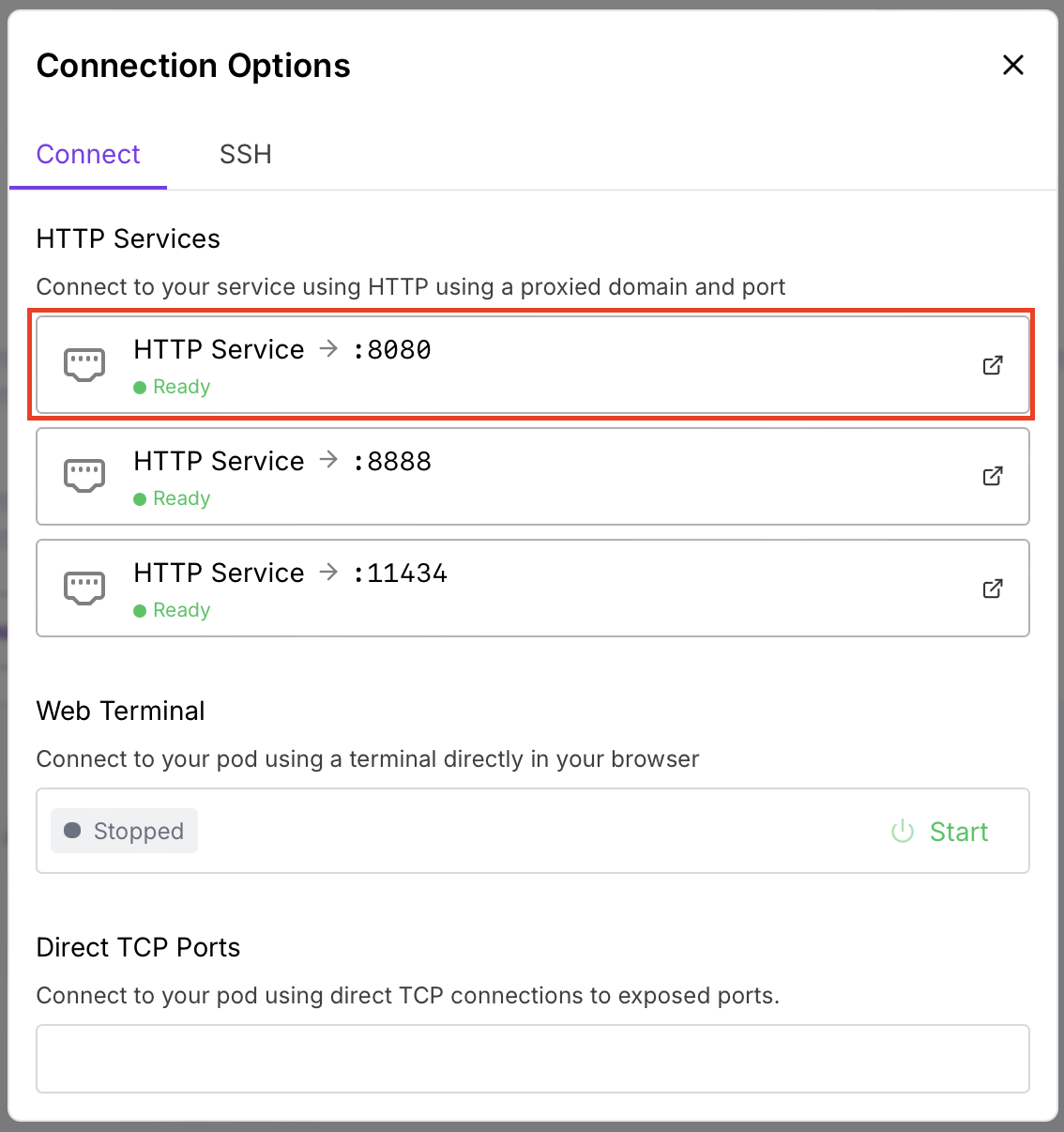
(2) HTTP 서비스 중에서 8080포트로 접속
참고로 8888은 주피터 노트북이다.
(3) 채팅에 쓸 모델 다운로드
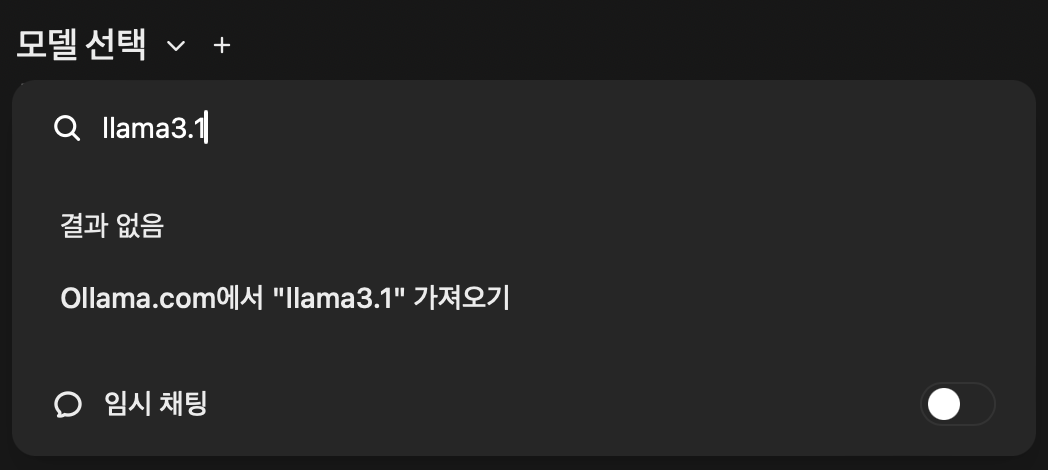
좌상단 "모델 선택" 클릭 - 원하는 모델명 입력 - "Ollama.com에서 가져오기" 클릭
여기서는 8B 크기의 "llama3.1"을 골랐다.
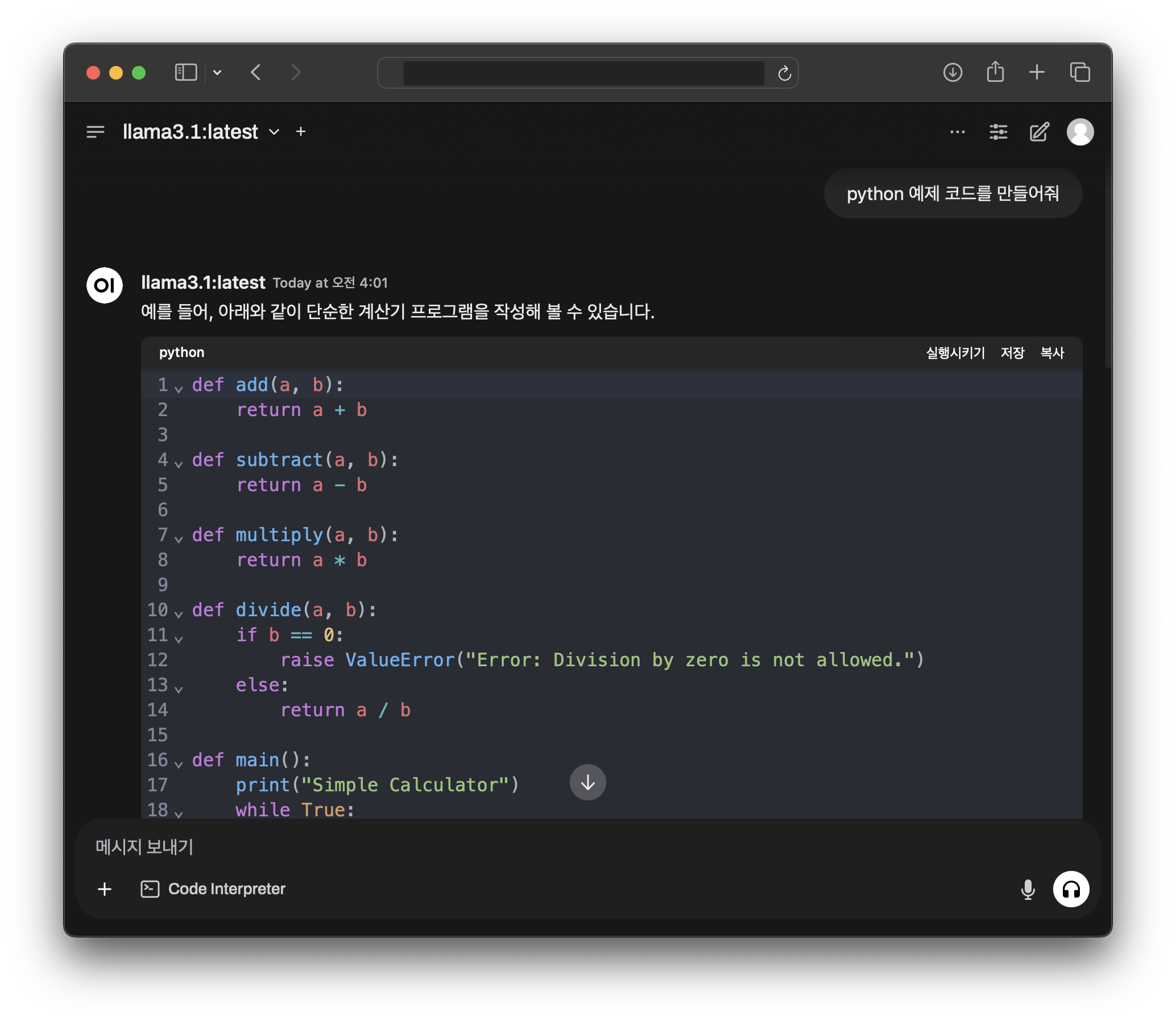
(4) 채팅 시작
모델을 선택하면 채팅을 시작할 수 있다.
사용이 끝난 Pod은 가능하면 삭제해주자. 정지를 시켜도 스토리지 비용이 소모될 수 있다.
