CNN
ILSVRC
- ImageNet Large-Scale Visual Recognition Chagllenge
- Classification, Detection, Localization, Segmentation
- 1000 different categories
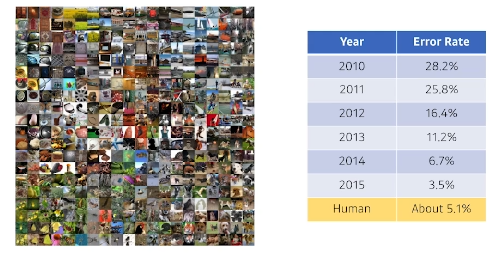
2015년도를 기준으로 사람보다 error rate가 낮아졌다. 참고로 저 '사람'은 어느 테슬라 개발자가 직접 해봤다고 한다.
이후에 설명할 CNN Model들은 해당 대회에서 검증이 됐다고 한다.
AlexNet
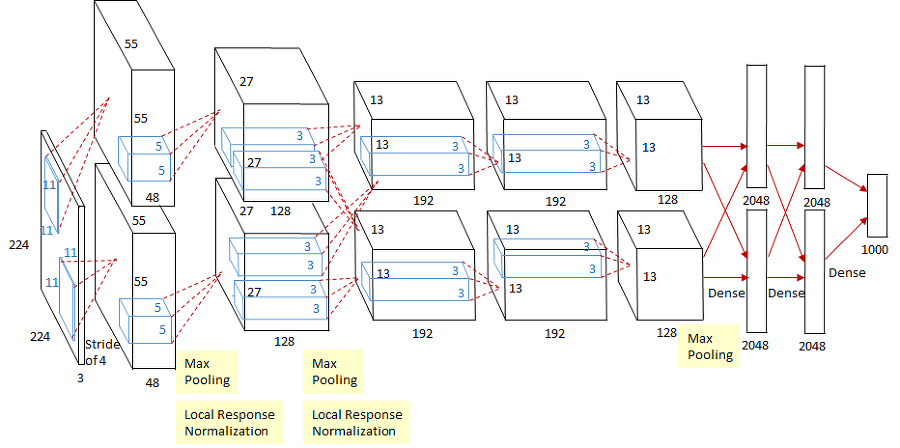
AlexNet은 당시 gpu의 자원이 부족했기 떄문에, 네트워크를 2개로 나누어서 서로 다른 gpu 2개에서 학습이 되도록 했다고 한다.
11x11 filter를 input에 적용했다. 사실 이는 좋은 선택이 아니다. 왜냐하면 filter가 바라보는 이미지의 영역(receptive field)은 넓어지지만 그만큼 parameter의 수가 늘어나기 때문이다.
Key point
- ReLU
- 해석은 많지만, 어쨌든 network가 깊어져도 network를 망치지 않는 효과적인 activation function이다.
- 2 GPU
- LRN(Local response normalization)
- 출력이 강한 영역을 죽이는 것.
- 요즘은 잘 안 쓴다.
- 하지만 data commendation은 무조건 활용한다. 용어가 맞는지 모르겠다..
- Overlapping pooling
- Data augmentation
- Dropout
2021년에는 당연히 사용하는 기법들이지만, 2012년에는 존재하지 않았던 Deep learning에 대한 기준점들이었다.
ReLU
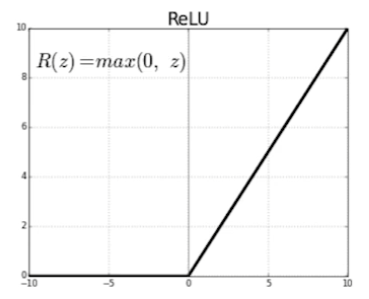
- linaer model들이 가지고 있는 좋은 성질들을 가지고 있다.
- gradient 값이 0보다 아주 많이 커져도, 해당 값을 유지할 수 있다.
- gradient descent가 용이하다.
- good generalization
- gradient vanishing 해결
- 기존의 activation function들은 입력이 0보다 아주 많이 커지면 gradient가 0에 가까워지면서 vanishing한다.
VGGNet
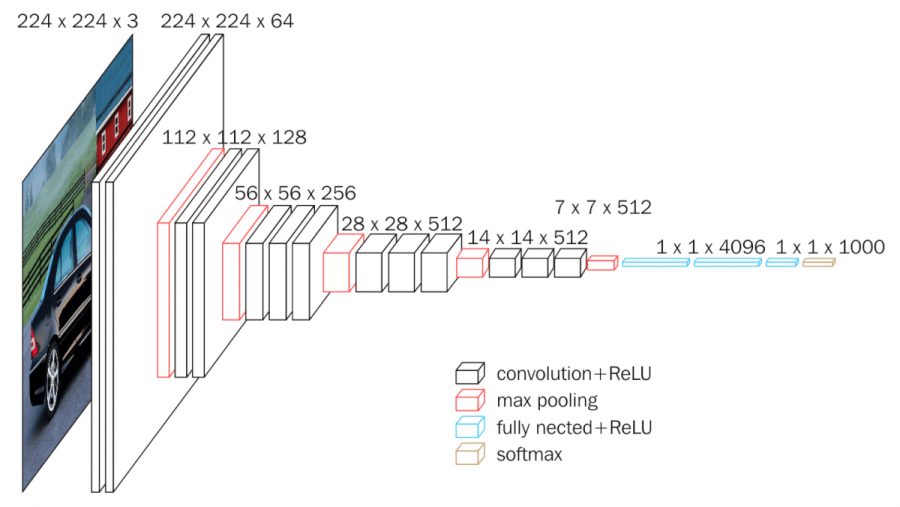
ICLR 2015 1등
- 3x3 convolution filter만 사용(with stride 1)
- 1x1 convolution for fully connected layers
- 최근에 1x1 filter를 사용하는 것처럼 paramter를 줄이기 위해 사용한 것은 아니다.
- Dropout(p=0.5)
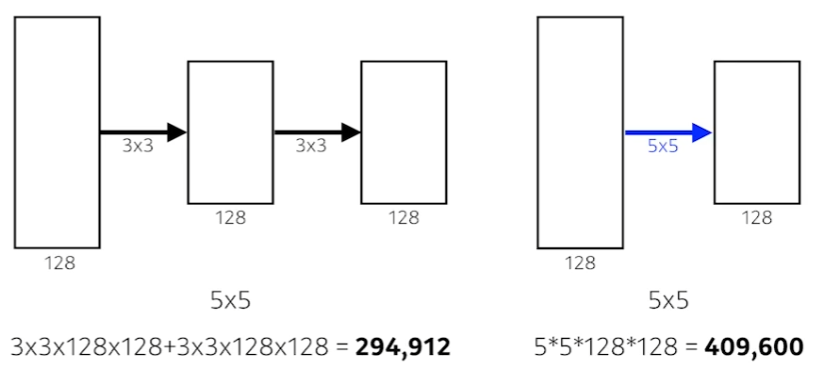
Receptive field : filter를 통해 입력받는 영역의 크기
3x3 filter를 2번 거친 것이 5x5 filter를 한번 쓴것과 receptive field는 5x5로 같다.
하지만 parameter의 수는 거의 1.5배 차이가 난다. 직접 계산한 식은 위와 같다.
따라서, 이후의 CNN 논문들은 대부분 3x3, 5x5의 filter를 쓰고 커봤자 7x7을 넘지 않는다. AlexNet의 11x11이 얼마나 비효율적인지 알 수 있다.
요약하면, receptive field를 늘리고자 한다면 작은 차원의 filter를 여러개 쌓는 것이 훨씬 유리하다.
GoogLeNet
지금까지 l을 소문자로 쓰는 논문을 찾아보니까 L을 대문자로 쓰더라.
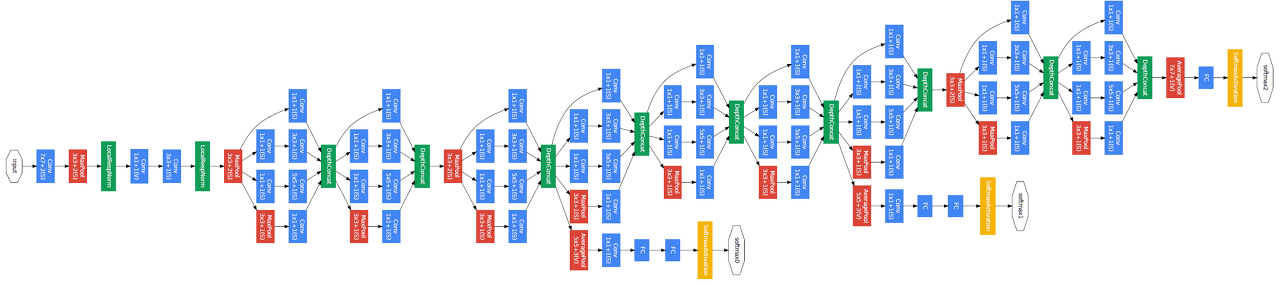
- ILSVRC 2014 1등
- NIN(Network in Network), 네트워크 내에 비슷한 모양의 네트워크가 또 존재한다.
- Inception block 사용
Inception block

- 여러 path에 대한 convolution 결과들을 concatenete
- 1x1 convolution 연산을 통해 parameter의 수를 줄인다.
- 1x1은 channesl 방향으로 dimension을 줄이는 효과가 있다.
1x1 convolution
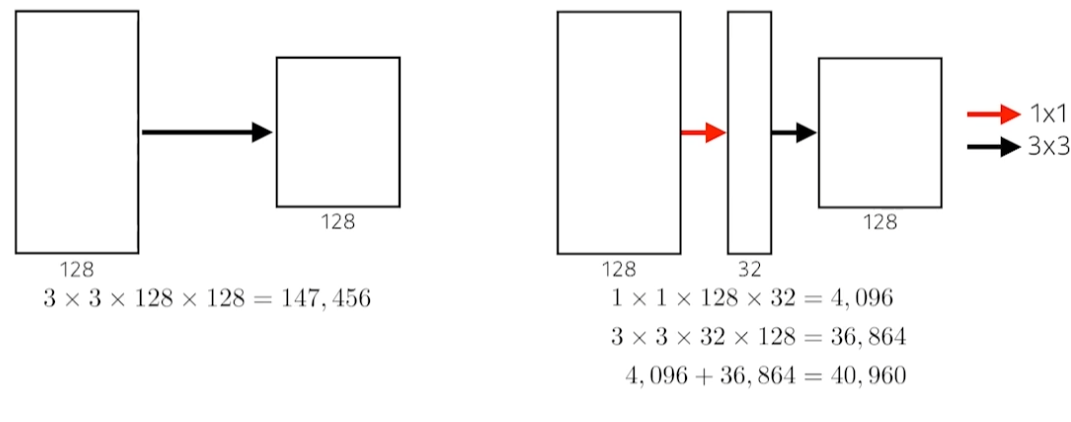
일반적인 convoltuion
3x3 filter가 128 channel이 있다. ouput channel이 128이기 때문에 filter가 128개 있어야한다.
따라서, 3x3x128x128 = 147,456개만큼의 parameter가 필요하다.
1x1 convolution
중간 output의 channel이 32개이다. 즉, 1x1x128 filter가 32개 존재한다.
3x3 convolution을 거친 결과가 128개의 channel을 가진다. 즉, 3x3x32 filter가 128개 있다.
이를 표현하면 위의 수식과 같다. 합하면 40,960개의 parameter가 필요하다.
1x1 convolution을 섞은 효과
input, output, reception field 크기를 유지하면서 parameter의 수를 줄였다.
CNN model 중간 비교
number of parameters
- AlexNet(8 layers): 60M
- VGGNet(19 layers): 110M
- GoogLeNet(22 layers): 4M
ResNet
그 유명한 Kaiming He가 쓴 논문이라고 한다. 누군지는 모르겠다..
등장 배경
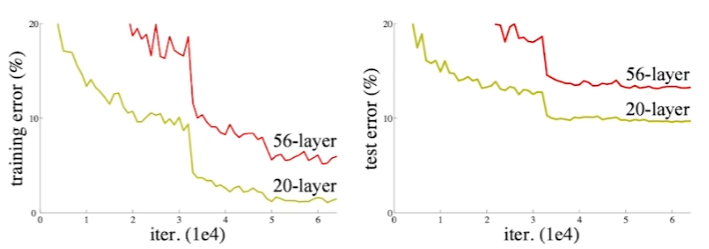
- overfitting은 과도한 parameter 수를 가질 때 발생한다.
- 56layer의 네트워크는 아무리 많이 학습해도 20 layer의 네트워크보다 학습이 안된다.
Skip connection
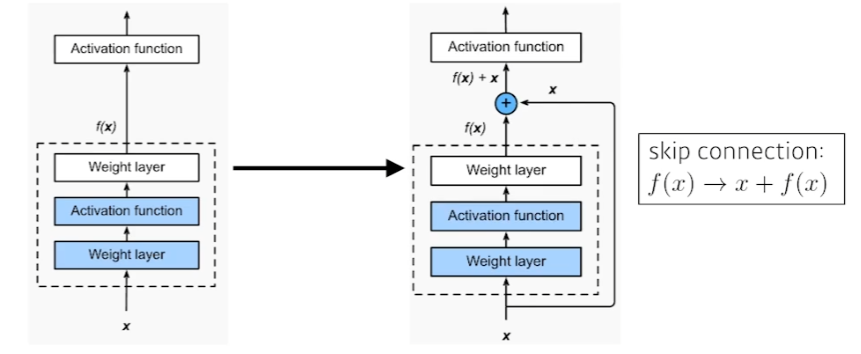
차이만을 학습하게 해보자
--
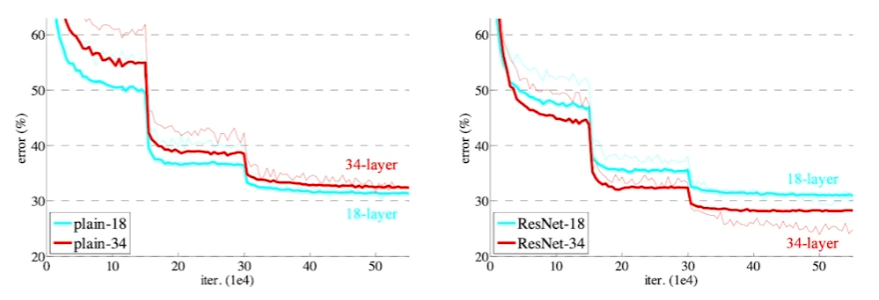
skip connection을 넣으니 layer를 많이 쓸수록 더 학습이 잘된다.
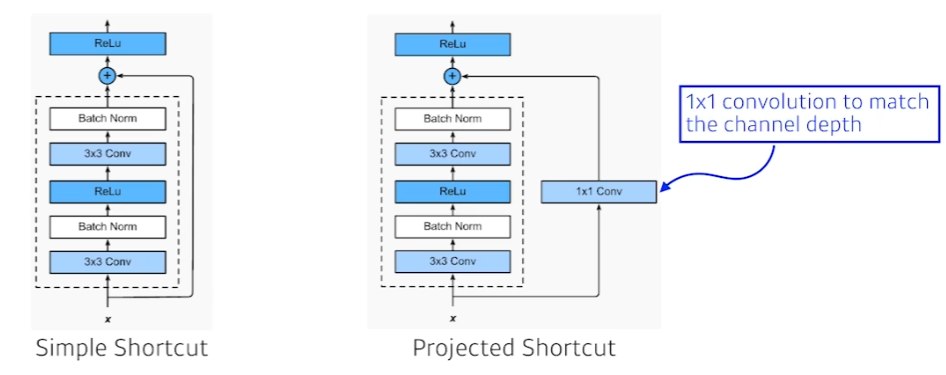
- simple shortcut
- 단순히 입력과 convolution 결과를 더한 것
- 많이 사용
- projected shorcut
- 1x1 convolution과 convolution 결과를 더한 것
- 잘 사용 안된다.
- batch nomarlization
- ResNet 논문에서는 convolution 연산 후, activation function 전에 넣는다.
- 논란이 많다. conv->relu->bn 이 성능이 더 좋다는 의견도 있고, 아예 bn을 안 쓰는게 좋다는 의견도 있다.
Bottleneck architecture

왼쪽이 기존 네트워크, 오른쪽이 bottlenet architecture.
convolution 앞뒤로 1x1 filter를 자유롭게 넣어서 입력고 출력 차원을 맞춰주는 효과를 기대함과 동시에 parameter 수를 줄인다.
CNN model 비교
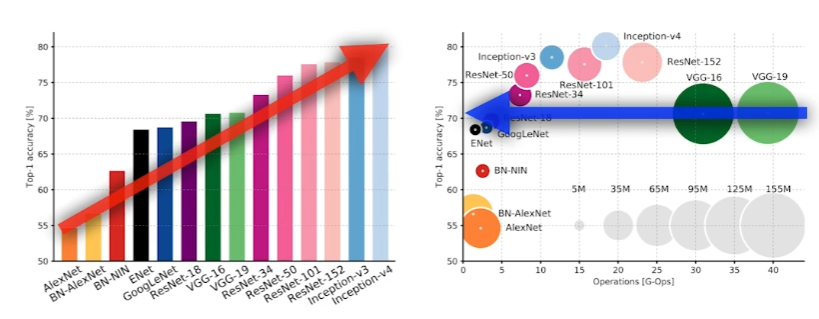
Performance는 늘었고, parameter는 더 줄었다!
DenseNet
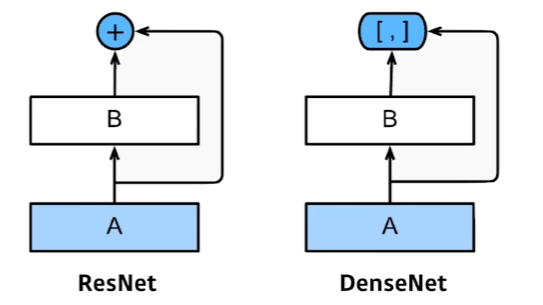
ResNet의 Skip connection에서 결과들을 더하면 값이 섞일 것이다. 따라서, concatenate하자. 차원이 같으니 문제도 없을것이다.
간단한 분류에서 굉장히 유용하다!
문제점
차원이 2배씩 커질 것이다.
Dense Block, Transition Block

문제점을 해결하기 위해 차원을 줄여주면서 network를 구성한다.
즉, Dense block으로 차원이 커지면, transition block으로 차원을 줄인다.
transition block = bn-> 1x1 conv -> 2x2 AvgPooling
