인프라 발전
구분 전통 배포 가상머신 기반 배포 컨테이너 중심 배포 컴퓨터 물리 컴퓨터 1 대 1대의 컴퓨터 + 다수의 가상 머신 컴퓨터 형태에 영향 x 운영체제(OS) OS 1개 설치 가상머신 각각에 OS 설치 형태와 관련 없이 설치된 OS 1개 리소스 1대의 자원 나눠씀 하이퍼바이저로 가상머신 별 개별 자원 할당 OS에서 프로그램 별 자원 할당 관리 격리 수준 격리되지 않음, 프로그램 간섭 발생 가능성 프로그램 별 완전 격리 실행 환경은 격리, OS 자원은 공유 문제 전이 가능성 한 서비스 문제 발생 시 전체 영향 VM 단위로 격리 프로그램이 OS에 문제를 줄 경우 시스템 중단 가능성
컨테이너는 커널을 공유함
- 가상 머신의 경우 OS 전체를 포함, 자신만의 커널을 가지기 때문에 완전한 독립된 환경
- 컨테이너의경우 Host의 커널을 함께 씀 -> 애플리케이션, 라이브러리만 포함하기 때문에 훨씬 가볍고 빠름
🎒 컨테이너 = 가방
🏠 가상 머신 = 집 또는 창고
- 가상머신의 경우 집 안에 가전, 전기, 수도 전부 포함되어 있음(자체 커널 존재) vs 가방만 챙긴 경우 가전, 전기, 수도는 외부에서 얻어서 써야 함
- 가상머신은 집 하나 통째로 쓰기 때문에 문제 생겨도 다른 집에 영향 없음 vs 컨테이너는 어느 정도 독립적이지만 커널(밖의 기반 시설)은 공유하므로 일부 영향 받을 수 있음
- 가상머신은 무거워서 옮기기 어려움 vs 컨테이너는 가볍고 어디든 쉽게 이동 가능
- 가상머신은 전기·수도·공간 모두 많이 사용 vs 컨테이너는 꼭 필요한 것만 챙겨서 리소스 효율적 사용
📌 가방 하나 들고 여행 가는 게 컨테이너, 집 한 채 짓고 들어가는 게 가상머신
📌 가방(컨테이너)는 빠르고 가볍지만, 완전한 독립이 필요하다면 집(가상머신)이 더 적합
쿠버네티스(kubernetes)
- K8s라고도 하는데 쿠버네티스에서(Kubernetes)에서 K와 s 사이에 8글자를 나타내는 약식 표기
- 컨테이너 오케스트레이션 도구
- 쿠버네티스는 여러 대의 서버(호스트)를 하나의 클러스터로 만들어줌 + 타 오케스트레이션 도구와 비교해 세부적인 기능을 더욱 폭넓게 제공
- 도커는 한 대의 물리적 서버에서 실행 <-> 쿠버네티스는 여러 대의 물리적 서버 + 각 서버 별 여러 개의 컨테이너 실행
- 쿠버네티스에서 docker를 사용해서 컨테이너를 관리하는 셈
특징
- 모든 리소스를 오브젝트 형태로 관리함
- ex) Node, Pod, Replica Set - 모든 리소스의 경우
YAML파일로 작성 됨 - 서버마다 정해진 역할이 있을것 → 여러 개의 컴포넌트로 구성
장점
- 여러 대의 서버를 하나의 클러스터 로 만들어줌
- 마이크로 서비스 구조의 컨테이너 배포, 서비스 장애 복구 등 컨테이너 기반 서비스 운영에 필요한 대부분의 오케스트레이션 기능을 지원
단점
- 구조가 복잡, 사용법이 다양 → 학습 비용이 높음
- 소규모 조직 및 회사에서는 쿠버네티스 기능이 오버 엔지니어링일 수 있음
쿠버네티스 → ‘바람직한’ 상태를 유지
- 쿠버네티스가 컨테이너 생성 및 삭제 시 명령어를 일일이 입력하는 방식을 사용하지는 않음
- 어떤 ‘바람직한’ 상태를
YAML파일에 정의한 뒤 자동으로 컨테이너를 생성하거나 삭제하면서 이 상태를 만들고 유지하는 것이 쿠버네티스 기본 아이디어이다.
- ex) 컨테이너가 하나 망가질 경우 → 해당 컨테이너를 자동 삭제, 새 컨테이너 대체
- ex) 바람직한 상태가 바뀔 경우 → 컨테이너 한 개 삭제
클러스터 = 마스터 노드 + 워커 노드
- 마스터 노드
- 전체적인 제어 담당
- 컨테이너를 실행하지 않으며 워커 노드에서 실행되는 컨테이너들 관리 역할을 하기 때문에 도커 엔진 같은 컨테이너 엔진도 x
- 컨테이너 상태 관리를 위한
etcd라는 데이터 베이스가 설치되어야 함
- 워커 노드
- 실제 동작 담당
- 컨테이너가 동작해야 하기 때문에 컨테이너 엔진이 설치되어 있어야 함
- 노드(Node)
- 물리적 서버와 일치하는 개념
- 실제 애플리케이션을 실행하는 물리적 또는 가상 머신
Etcd
Key:value형태의 데이터를 저장하는 저장소- 분산 시스템에서 중요한 데이터를 저장할 때 사용
- 클러스터 관련 정보 전반을 관리하는 데이터 베이스
쿠버네티스 구성 요소
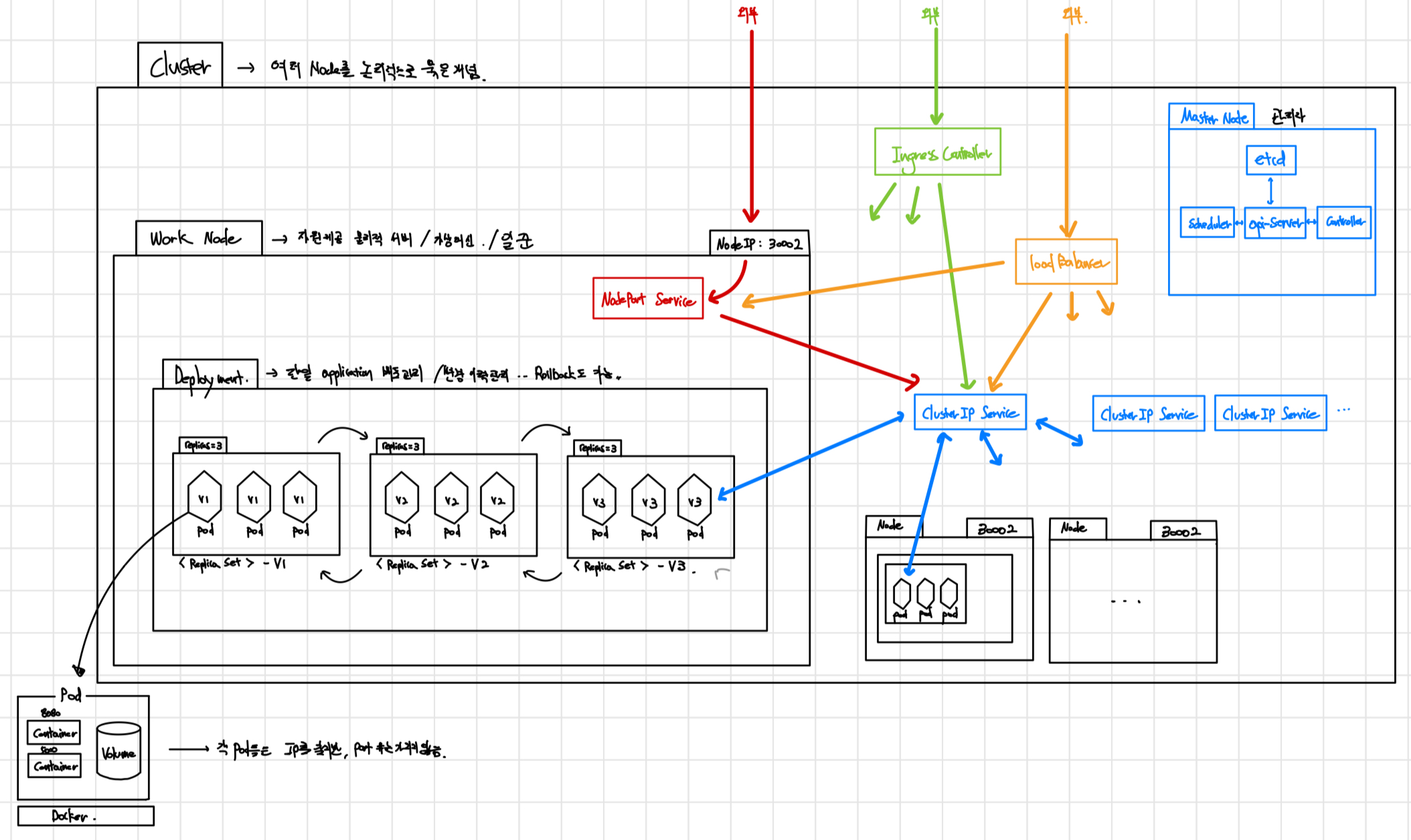
➡️ 파드 (Pod)
- 컨테이너(여러 개 가능) + 볼륨(하나도 없는 경우도 가능)
- 애플리케이션의 기본 단위 → 각각 기능을 담는 컨테이너들이 1개 이상 모여 있는 묶음을 포드라고 함.
- 하나의 컨테이너라도 제대로 작동하지 않으면 애플리케이션이 실행되지 않음 → 컨테이너가 정상적으로 실행될 때까지 컨테이너를 계속 restart 시킴
- 내부 컨테이너들은
Pod의 IP를ocalhost로 공유함 Pod는 따로 포트번호를 갖지 않음 → 내부 컨테이너들이 포트 번호를 가짐
➡️ Pod 생성을 위한 YAML 파일
apiVersion: v1
kind: Pod
metadata:
name: <pod 이름>
spec:
containers:
- name: <컨테이너 이름>
image: <기본 이미지>
ports:
- containerPort: <컨테이너가 노출할 Port>➡️ 서비스
- 위의
pod들이 모인 것 → 클러스터 외부로부터 요청을 받을 수 있게 IP를 노출하는 역할을 하는 리소스 pod를 외부에 노출해 사용자들이 접근하거나 다른Deployment의pod들이 내부에 접근하려면Service를 별도로 생성해야 한다.- 여기서 말하는
service는 여러pod들을 이끄는 반장 정도로 생각 - 특정
service가 관리하는pod들은 모두 동일한 구성을 가짐 - 로드 밸런서(부하 분산장치) 역할 → 각 서비스는 자동으로 고정된 IP 주소를 부여 받음 → 이 주소로 들어오는 통신 처리
- 내부에 여러 개의
pod가 있어도 밖에는 하나의 IP 주소만 볼 수 있음 → 해당 주소로 접근할 경우service가 통신을 적절히 분배해줌
➡️ Service 타입
- ClusterIP
- 가장 기본이 되는 Service 타입
- 클러스터 내부 통신만 가능, 외부 트래픽은 받을 수 없음
- NodePort
- 클러스터 내부 및 외부 통신이 가능한 Service 타입
- 외부 트래픽을 전달받을 수 있고 노드의 포트를 사용함(30000~32767)
- Cluster를 구성하는 각 Node에 동일한 port를 열고, 열린 포트를 통해 각 Node 별로 외부 트래픽을 받은 뒤 ClusterIP로 모인 뒤 분산됨
- LoadBalancer
- 외부 트래픽을 받는 역할
- LoadBalancer → NodePort → ClusterIP 순서
- AWS, GCP 등과 같은 클라우드 플랫폼 환경에서만 사용 가능
- ExternalName
- 외부로 나가는 트래픽을 변환하기 위한 용도
➡️ 레플리카 세트(ReplicaSet)
- 정해진 수의 동일한
pod가 항상 실행되도록 관리하는 역할을 하는 오브젝트 - 서비스가 요청을 배분하는 반장이라면,
replica set은pod수를 관리하는 반장임 - 모자라는
pod를 보충 혹은 정의 파일에 정의된pod수 감소 시pod수를 실제로 감소시킴 replica set가 관리하는 동일한 구성의pod⇒ 레플리카Replica set생성YAML파일- 어 근데 동일한
pod생성이면 → 각pod속 컨테이너들이 갖는 포트 번호가 전부 동일하지 않나..? → 그럼 어떤pod로 요청을 보내려나? → 이 역할을 하는 것이Service
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: <레플리카셋 이름>
spec:
replicas: <Pod 유지 개수>
selector:
matchLabels:
app: <관리할 Pod를 찾는 선택기>
template:
metadata:
name: <포드 이름>
labels:
app: <레플리카셋의 matchLabels의 항목과 동일하게 작성>
spec:
containers:
- name: <컨테이너 이름>
image: <기본 이미지>
ports:
- containerPort: <컨테이너가 노출할 Port>➡️ Deployment
- 여러 개의
Replica Set을 관리하기 위한 상위 오브젝트 → 컨테이너 애플리케이션 배포하고 관리하는 역할을 담당함 - 애플리케이션 업데이트 시
Replica Set의 변경사항을 저장하는 리비전(Rivision)을 남겨놓고 롤백 가능
➡️ Deployment Strategy
- Recreate
- 배포된 모든 앱 제거 후 새로운 버전 앱 한 번에 생성
- 모든 배포 앱을 다운시킨 뒤 새로운 앱이 업로드될 때까지 사용자 접근이 불가 → 무중단 배포(Zero Downtime Deployment)가 불가능
- ex) 5개를 지운 뒤 새로운 앱 5개 새로 띄우기
- Rolling Update
- 현재 배포된 pod를 새로운 pod로 점진적으로 교체함
- 구 버전을 부분적으로 내린 뒤, 그 수만큼의 새 버전을 배포 → 모두 새 버전이 될 때까지 반복함
➡️ Cluster AutoScaling
- 쿠버네티스에서 Cluster Autoscaler는 클러스터의 리소스 사용량에 따라 노드의 수를 자동으로 늘리거나 줄이는 역할을 한다.
- Cluster AutoScaling 동작 과정
- Pending 상태인 Pod 발생
- 새로 생성된 Pod가 리소스를 충분히 할당받지 못하면
Pending상태로 대기함 - Cluster Autoscaler는 주기적으로 클러스터 상태를 확인하여 스케줄링되지 않은
Pending Pod를 탐지
- 새로 생성된 Pod가 리소스를 충분히 할당받지 못하면
- 리소스 부족 판단
- Autoscaler는 쿠버네티스 API 서버와 통신하여 현재 스케줄되지 못한 Pod들의 목록을 가져옴
- 현재 노드들의 자원을 고려했을 때해당 Pod들을 수용할 수 없다고 판단
- 필요한 노드 수 계산 및 확장 요청
- Cluster Autoscaler는 얼마나 많은 노드를 추가해야 하는지 계산
- 해당 값 기반 Auto Scaling Group (ASG)의 Desired Capacity를 증가시킴
- 새로운 노드가 자동으로 생성됨
- Pending 상태인 Pod 발생
➡️ HPA(Horizontal Pod Autoscaler)
- Pod 수를 스케일아웃하여 서비스 요청을 여러 pod로 분산시키는 방법
- 쿠버네티스의 HPA는 주기적으로 MetricStore로부터 Pod의 metric을 얻고, 이를 기반으로 pod 수를 계산해 pod 수 경
- 명령어 → Helm 이용
- Helm : 쿠버네티스 용 소프트웨어 검색, 사용을 위한 패키지 관리자
helm repo add metrics-server https://kubernetes-sigs.github.io/metrics-server/
helm repo update
helm show values metrics-server/metrics-server > values.yaml
백엔드 개발자 나무입니다