사전학습과 파인튜닝 패러다임을 넘어서
최근 자연어처리 시스템에서는 사전학습된 language representions에 파인튜닝 하는 과정을 거친다. 하지만 이러한 접근 방식들도 다운스트림 태스크를 학습하는데 있어 수천에서 수십만의 특정 데이터가 필요하다. 따라서 사전학습과 파인튜닝 패러다임의 아래 제한사항들을 극복 하는것이 필요하다.
-
실용적인 측면에서 모든 자연어 태스크에 대한 대용량의 라벨링된 데이터 세트가 필요하다는 점은 언어모델의 적용 가능성을 제한한다.
-
학습데이터에 대한 거짓 상관관계가 나타날 가능성은 모델의 표현과 학습 분포의 협소성과 함께 증가한다. GPT3에서의 관점은 사전학습 다음에 파인튜닝을 거치는 것은 사전학습하는 동안 정보를 흡수하기 위해 크게 설계된 모델이 매우 협소한 태스크에 대해 파인튜닝 되는 것으로 본다.
몇가지 사례를 통해 대형 모델 대형 모델들이 일반화를 위해 필수 사항이 아니고, 이러한 사전학습+파인튜닝 패러다임이 성능이 저조한 경우도 있다.
-
사람은 대부분의 자연어 태스크들을 학습하는데 많은 수의 데이터나 예가 필요로 하지 않다. 사람의 예를 생각해보면 긴 대화를 하는 동안 다양한 자연어 task들과 skill들을 매끄럽게 섞어서 사용하는것을 생각해보면 된다.
메타러닝 meta-learning
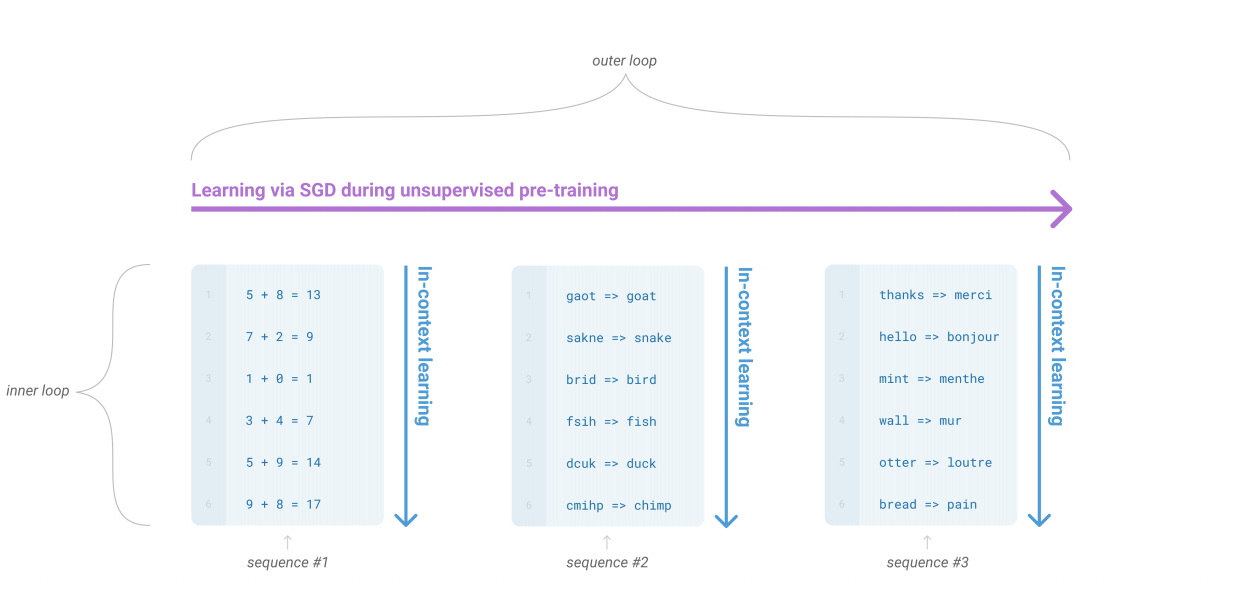
in-context learning이라 불리는 방법을 통해 학습된다. 비감독 사전학습 과정에서 언어모델이 광범위하게 skill과 패턴 인식 능력을 개발할 때, 이과정의 내부 루프를 설명하기 위해in-context-learning용어를 사용한다. 각각의 다이어그램은 학습 데이터의 전체 모습을 나타낸다는 것이 아닌, 단일 시퀀스 내에서 반복적으로 포함된 하위 태스크들(sub-task)들이 있음 보여준다.
그림을 해석하기로는 각 시퀀스들을 돌면서 시퀀스 안에 세자릿수 덧셈, 오탈자 교정, 번역등과 같이 데이터가 학습된다는 것으로 보인다. 컨텍스트 안에서 학습된다는 의미로 보인다
위의 제한 사항들을 해결하기 위한 한가지 방법으로 메타 러닝이 있다. 메타 러닝은 언어 모델의 맥락 안에 모델이 학습을 거치는 동안 넓은 범위의 기술과 패턴을 인식하는 능력을 개발하는 것을 의미한다. 그리고 개발된 능력들은 예측시간(inference time)에 매우 빠르게 적용하거나 태스크들을 인식한다.
사전 학습된 언어모델의 텍스트 인풋을 task specification 의 한 형태로 이용하여 in-context-learning을 한 최근 사례도 있다: 모델을 자연어 지시 및/또는 몇가지 task demonstration들에 대한 조건이 주어지고, 모델은 다음 순서에 무엇이 올지를 예측하므로써 간단하게 주어진 인스턴스들을 완성하기를 기대된다.
이것이 초기에 가능성을 보이기도 했지만, 파인튜닝보다 훨씬 낮을 결과를 얻는다. Natural Questions에 대해서는 4%의 결과만 얻고, 다른 CoQa 태스크에서도 낮은 성능을 보였다. 따라서 메타 러닝이 자연어 처리에서 실제적으로 사용되기 위해서는 상당한 개선이 필요해보였다.
또 다른 방법, 모델의 크기
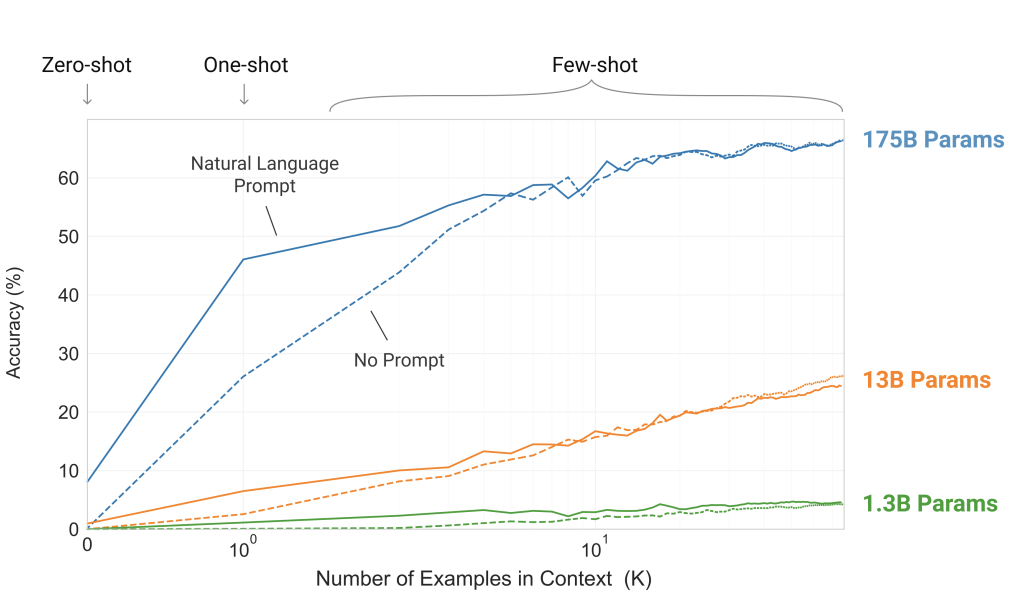
최근 트랜스포머의 크기는 상당히 증가했고, 1억개의 파라미터 부터 3억개의 파라미터를 지나, 15억개의 파라미터, 80억개, 110억개, 170억개의 파라미터로 증가했다. 각각의 증가는 성능향상을 이루었다. 그 증거로는 많은 다운스트림 태스크들에 대해 상관관계가 큰 log loss 가 모델의 규모에 따라 부드럽게 개선되는 경향이 있다.
in-context learning은 통해 모델의 파라미터들이 많은 스킬들과 태스크들에 대해 학습하기 때문에, 모델의 규모에 따라 강력한 성능을 보인다.
