Gradient Accumulation, 큰 모델 학습시 어떻게 배치 사이즈를 늘릴수 있을까?
최근에 파이토치로 모델을 학습하는 경우 단일 GPU로 학습하는 경우 메모리에 제한이 있어 큰 배치사이즈를 가지지 못하는 문제가 있습니다. 모델의 성능향상을 위해 어떻게 하면 더 큰 배치사이즈로 학습할 수 있을지 찾아보다 적용할 만한 부분이 있어 찾아보고 간략하게 정리하고자 합니다.
병렬 16개의 GPU로 1024의 배치사이즈를 처리하는 경우 배치사이즈를 64으로 나누어 처리할 수 있습니다.
큰 배치사이즈를 사용하는 이유는 학습시에 정보의 노이즈를 제거하고 더 나은 gradient decsent를 수행할수 있습니다.
그러나 매우 큰 배치 사이즈는 SGD가 수렴되는 속도와 최종 모델의 성능에는 부정적인 영향을 끼진다고 합니다.
12GB GPU로 BERT 학습하기
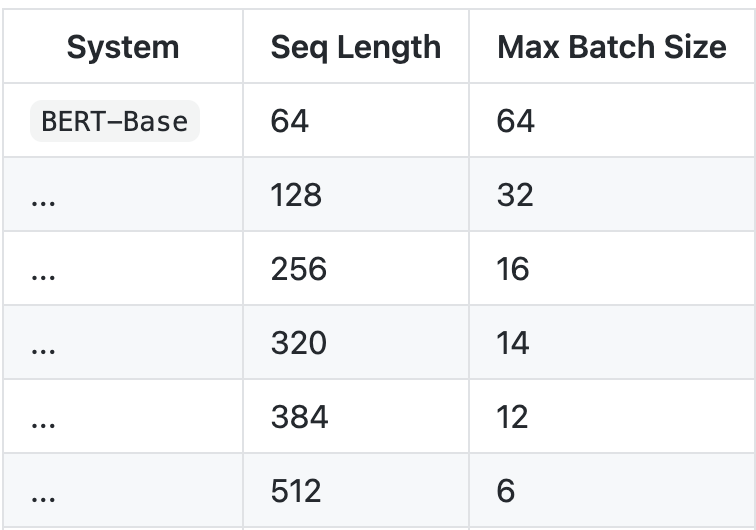
https://github.com/google-research/bert#contact-information 참고.
위와 같이 BERT-base 모델을 학습시킬때 512 토큰을 사용하는 경우, 12GB 메모리로 최대 학습 시킬수 있는 배치 사이즈의 경우 6으로 실제 학습시에 256 배치 사이즈와 비교해보았을때 많이 적은 크기의 배치사이즈 입니다.
그래디언트 축적(Gradient Accumulation)을 이용한 큰 배치 사이즈 효과 내기
위와 같이 12gb gpu에서 BERT-base 모델을 256배치 모델을 학습시키기 위한 같은 효과를 내기 위해서는 그래디언트 축적 방법을 사용할 수 있습니다.
샘플코드
Gradient Accumulation 코드는 아래와 같으며 12GB 메모리에서 미니배치 4로 미니배치 256을 내기 위해서는 256 = 4 * 64에서 볼수 있듯, 64번의 그래디언트 축적을 통해 큰 배치 사이즈의 효과를 낼수 있습니다.
model.zero_grad() # Reset gradients tensors
for i, (inputs, labels) in enumerate(training_set):
predictions = model(inputs) # Forward pass
loss = loss_function(predictions, labels) # Compute loss function
loss = loss / accumulation_steps # Normalize our loss (if averaged)
loss.backward() # Backward pass
if (i+1) % accumulation_steps == 0: # Wait for several backward steps
optimizer.step() # Now we can do an optimizer step
model.zero_grad() # Reset gradients tensors
if (i+1) % evaluation_steps == 0: # Evaluate the model when we...
evaluate_model() 