Transformer로 한국어-영어 기계번역 모델 만들기
최근에 여러가지 자연어처리 모델들을 다루면서 트랜스포머 기반의 모델들인 BERT, GPT, ELECTRA 등과 같이 다양한 모델들을 사용하게 되는데, 모델들을 사용하게 되면서 트랜스포머 모델 자체에 대한 직접 구현을 해보고 싶다는 생각을 가지게 되었습니다.
기존에 트랜스포머 관련해서 자세히 설명한 자료들을 참고하여 트랜스포머 모델을 직접 개발해보고, 한국어에서 영어로 번역하는 기계 번역 태스크에 대해 학습하였습니다. 개발하는데 참고한 자료로 The Annotated Transformer와 pytorch 공식문서를 사용하였고 설명이나 코드가 자세히 설명 되어있어 부족한 부분은 앞의 페이지들을 참고하시면 많은 도움 될것 같습니다.
아래의 모든 코드는 https://github.com/nawnoes/pytorch-transformer 에서 확인 가능합니다.
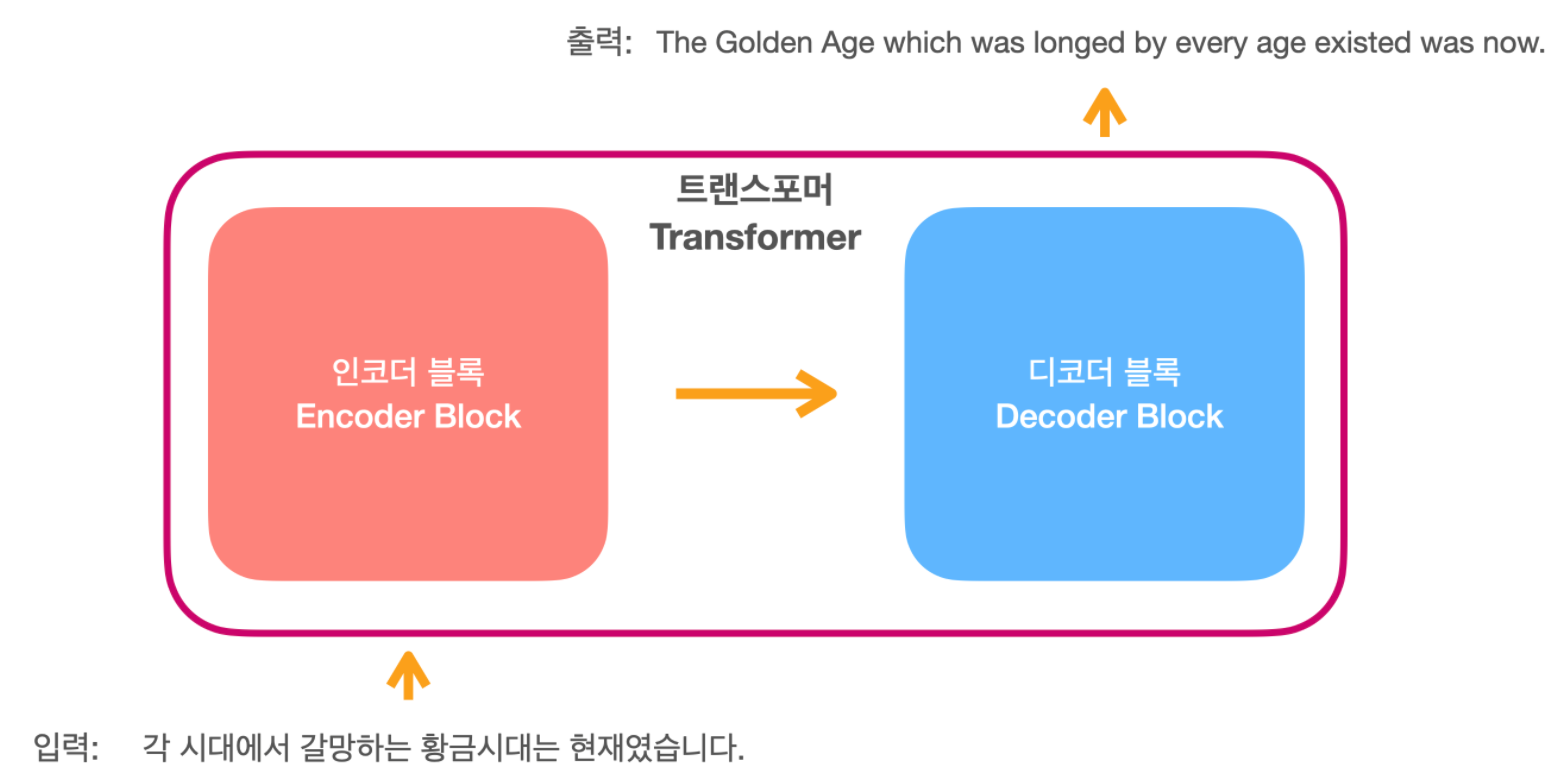
Model
아래의 트랜스포머 모델의 구조에 따라 작성하고 읽기 쉽게 작성하고자 하였습니다
![]()
모델의 폴더 구조는 아래와 같으며, model 아래에 transformer 모델에 대한 코드를 담고 있습니다.
model
ㄴ transformer.py ﹒﹒﹒ 트랜스포머 모델
ㄴ util.py ﹒﹒﹒ 모델에 사용되는 유틸
ㄴ visualization.py ﹒﹒﹒ 모델의 각 부분 시각화
train_translation.py﹒﹒﹒ 한국어-영어 번역 학습
run_translation.py ﹒﹒﹒ 한국어-영어 번역 테스트셀프어텐션, Self-Attention
class SelfAttention(nn.Module):
def __init__(self):
super(SelfAttention,self).__init__()
self.matmul = torch.matmul
self.softmax = torch.softmax
def forward(self,query, key, value, mask=None):
key_transpose = torch.transpose(key,-2,-1) # (bath, head_num, d_k, token_)
matmul_result = self.matmul(query,key_transpose) # MatMul(Q,K)
d_k = key.size()[-1]
attention_score = matmul_result/math.sqrt(d_k) # Scale
if mask is not None:
attention_score = attention_score.masked_fill(mask == 0, -1e20)
softmax_attention_score = self.softmax(attention_score,dim=-1) # 어텐션 값
result = self.matmul(softmax_attention_score,value)
return result, softmax_attention_score멀티헤드 어텐션, Multi Head Attention
class MultiHeadAttention(nn.Module):
def __init__(self, head_num =8 , d_model = 512,dropout = 0.1):
super(MultiHeadAttention,self).__init__()
# print(d_model % head_num)
# assert d_model % head_num != 0 # d_model % head_num == 0 이 아닌경우 에러메세지 발생
self.head_num = head_num
self.d_model = d_model
self.d_k = self.d_v = d_model // head_num
self.w_q = nn.Linear(d_model,d_model)
self.w_k = nn.Linear(d_model,d_model)
self.w_v = nn.Linear(d_model,d_model)
self.w_o = nn.Linear(d_model,d_model)
self.self_attention = SelfAttention()
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask = None):
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
batche_num = query.size(0)
query = self.w_q(query).view(batche_num, -1, self.head_num, self.d_k).transpose(1, 2)
key = self.w_k(key).view(batche_num, -1, self.head_num, self.d_k).transpose(1, 2)
value = self.w_v(value).view(batche_num, -1, self.head_num, self.d_k).transpose(1, 2)
attention_result, attention_score = self.self_attention(query, key, value, mask)
attention_result = attention_result.transpose(1,2).contiguous().view(batche_num, -1, self.head_num * self.d_k)
return self.w_o(attention_result)인코더, Encoder
class Encoder(nn.Module):
def __init__(self, d_model, head_num, dropout):
super(Encoder,self).__init__()
self.multi_head_attention = MultiHeadAttention(d_model= d_model, head_num= head_num)
self.residual_1 = ResidualConnection(d_model,dropout=dropout)
self.feed_forward = FeedForward(d_model)
self.residual_2 = ResidualConnection(d_model,dropout=dropout)
def forward(self, input, mask):
x = self.residual_1(input, lambda x: self.multi_head_attention(x, x, x, mask))
x = self.residual_2(x, lambda x: self.feed_forward(x))
return x디코더, Decoder
class Decoder(nn.Module):
def __init__(self, d_model,head_num, dropout):
super(Decoder,self).__init__()
self.masked_multi_head_attention = MultiHeadAttention(d_model= d_model, head_num= head_num)
self.residual_1 = ResidualConnection(d_model,dropout=dropout)
self.encoder_decoder_attention = MultiHeadAttention(d_model= d_model, head_num= head_num)
self.residual_2 = ResidualConnection(d_model,dropout=dropout)
self.feed_forward= FeedForward(d_model)
self.residual_3 = ResidualConnection(d_model,dropout=dropout)
def forward(self, target, encoder_output, target_mask, encoder_mask):
# target, x, target_mask, input_mask
x = self.residual_1(target, lambda x: self.masked_multi_head_attention(x, x, x, target_mask))
x = self.residual_2(x, lambda x: self.encoder_decoder_attention(x, encoder_output, encoder_output, encoder_mask))
x = self.residual_3(x, self.feed_forward)
return x포지셔널 인코딩, Positional Encoding
class Embeddings(nn.Module):
def __init__(self, vocab_num, d_model):
super(Embeddings,self).__init__()
self.emb = nn.Embedding(vocab_num,d_model)
self.d_model = d_model
def forward(self, x):
return self.emb(x) * math.sqrt(self.d_model)
class PositionalEncoding(nn.Module):
def __init__(self, max_seq_len, d_model,dropout=0.1):
super(PositionalEncoding,self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_seq_len, d_model)
position = torch.arange(0,max_seq_len).unsqueeze(1)
base = torch.ones(d_model//2).fill_(10000)
pow_term = torch.arange(0, d_model, 2) / torch.tensor(d_model,dtype=torch.float32)
div_term = torch.pow(base,pow_term)
pe[:, 0::2] = torch.sin(position / div_term)
pe[:, 1::2] = torch.cos(position / div_term)
pe = pe.unsqueeze(0)
# pe를 학습되지 않는 변수로 등록
self.register_buffer('positional_encoding', pe)
def forward(self, x):
x = x + Variable(self.positional_encoding[:, :x.size(1)], requires_grad=False)
return self.dropout(x)Transformer
class Transformer(nn.Module):
def __init__(self,vocab_num, d_model, max_seq_len, head_num, dropout, N):
super(Transformer,self).__init__()
self.embedding = Embeddings(vocab_num, d_model)
self.positional_encoding = PositionalEncoding(max_seq_len,d_model)
self.encoders = clones(Encoder(d_model=d_model, head_num=head_num, dropout=dropout), N)
self.decoders = clones(Decoder(d_model=d_model, head_num=head_num, dropout=dropout), N)
self.generator = Generator(d_model, vocab_num)
def forward(self, input, target, input_mask, target_mask, labels=None):
x = self.positional_encoding(self.embedding(input))
for encoder in self.encoders:
x = encoder(x, input_mask)
target = self.positional_encoding(self.embedding(target))
for decoder in self.decoders:
# target, encoder_output, target_mask, encoder_mask)
target = decoder(target, x, target_mask, input_mask)
lm_logits = self.generator(target)
loss = None
if labels is not None:
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss(ignore_index=0)
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
return lm_logits, loss
def encode(self,input, input_mask):
x = self.positional_encoding(self.embedding(input))
for encoder in self.encoders:
x = encoder(x, input_mask)
return x
def decode(self, encode_output, encoder_mask, target, target_mask):
target = self.positional_encoding(self.embedding(target))
for decoder in self.decoders:
#target, encoder_output, target_mask, encoder_mask
target = decoder(target, encode_output, target_mask, encoder_mask)
lm_logits = self.generator(target)
return lm_logitsKo-En Translation
AI Hub에 있는 한국어-영어 번역 데이터를 활용해 트랜스포머르 이용한 번역 태스크 학습
Data
① AI Hub 한국어-영어 번역 샘플 데이터.
: 샘플 데이터의 경우 회원 가입 및 로그인 할 필요 없음.
② AI Hub 한국어-영어 번역 데이터 - 구어체
다운로드 후 구어체 데이터데 대하여 학습.
csv형태의 학습 데이터
당신한테는 언제가 좋은가요?,When would be a good day for you?
당신한테서 답장이 오면 난 하루가 행복해요.,I feel happy all day long if I get your reply.
당신회사는 공장과 직접 일을 하나요?,Does your company work with the factory directly?Train Setting
# Model setting
model_name = 'transformer-translation-spoken'
vocab_num = 22000
max_length = 64
d_model = 512
head_num = 8
dropout = 0.1
N = 6
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
# Hyperparameter
epochs = 50
batch_size = 8
learning_rate = 0.8Training
train_translation.py를 사용해 한국어-영어 기계번역에 대해 학습할 수 있습니다. Colab 환경이 학습이 끊기게 되므로, 연장해서 학습할 수 있도록 torch.seed를 고정해 학습할 수 있도록합니다.
- 학습환경: Colab Pro 20시간
python3 train_translation.pytrain_translation.py
TranslationTrainer class에서 train 부분입니다
def train(self, epochs, train_dataset, eval_dataset, optimizer, scheduler):
self.model.train()
total_loss = 0.
global_steps = 0
start_time = time.time()
losses = {}
best_val_loss = float("inf")
best_model = None
start_epoch = 0
start_step = 0
train_dataset_length = len(train_dataset)
self.model.to(self.device)
if os.path.isfile(f'{self.checkpoint_path}/{self.model_name}.pth'):
checkpoint = torch.load(f'{self.checkpoint_path}/{self.model_name}.pth', map_location=self.device)
start_epoch = checkpoint['epoch']
losses = checkpoint['losses']
global_steps = checkpoint['train_step']
start_step = global_steps if start_epoch == 0 else (global_steps % train_dataset_length) + 1
self.model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
for epoch in range(start_epoch, epochs):
epoch_start_time = time.time()
pb = tqdm(enumerate(train_dataset),
desc=f'Epoch-{epoch} Iterator',
total=train_dataset_length,
bar_format='{l_bar}{bar:10}{r_bar}'
)
pb.update(start_step)
for i,data in pb:
if i < start_step:
continue
"""
doc={
"input":input, # input
"input_mask": (input != pad_token_idx).unsqueeze(-2), # input_mask
"target": target, # target,
"target_mask": self.make_std_mask(target, pad_token_idx), # target_mask
"token_num": (target[...,1:] != pad_token_idx).data.sum() # token_num
}
"""
input = data['input'].to(self.device)
target = data['target'].to(self.device)
input_mask = data['input_mask'].to(self.device)
target_mask = data['target_mask'].to(self.device)
optimizer.zero_grad()
generator_logit, loss = self.model.forward(input, target, input_mask, target_mask, labels=target)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
losses[global_steps] = loss.item()
total_loss += loss.item()
log_interval = 1
save_interval = 500
global_steps += 1
if i % log_interval == 0 and i > 0:
cur_loss = total_loss / log_interval
elapsed = time.time() - start_time
# print('| epoch {:3d} | {:5d}/{:5d} batches | '
# 'lr {:02.2f} | ms/batch {:5.2f} | '
# 'loss {:5.2f} | ppl {:8.2f}'.format(
# epoch, i, len(train_dataset), scheduler.get_lr()[0],
# elapsed * 1000 / log_interval,
# cur_loss, math.exp(cur_loss)))
pb.set_postfix_str('| epoch {:3d} | {:5d}/{:5d} batches | '
'lr {:02.2f} | ms/batch {:5.2f} | '
'loss {:5.2f} | ppl {:8.2f}'.format(
epoch, i, len(train_dataset), scheduler.get_lr()[0],
elapsed * 1000 / log_interval,
cur_loss, math.exp(cur_loss)))
total_loss = 0
start_time = time.time()
# self.save(epoch, self.model, optimizer, losses, global_steps)
if i % save_interval == 0:
self.save(epoch, self.model, optimizer, losses, global_steps)
val_loss = self.evaluate(eval_dataset)
self.model.train()
print('-' * 89)
print('| end of epoch {:3d} | time: {:5.2f}s | valid loss {:5.2f} | '
'valid ppl {:8.2f}'.format(epoch, (time.time() - epoch_start_time),
val_loss, math.exp(val_loss)))
print('-' * 89)
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model = model
start_step = 0
scheduler.step()Train Result
- Epoch: 50
-----------------------------------------------------------------------------------------
| end of epoch 0 | time: 2005.31s | valid loss 4.95 | valid ppl 141.70
-----------------------------------------------------------------------------------------
| end of epoch 1 | time: 2149.59s | valid loss 4.62 | valid ppl 101.26
-----------------------------------------------------------------------------------------
| end of epoch 2 | time: 2058.49s | valid loss 4.39 | valid ppl 80.86
-----------------------------------------------------------------------------------------
| end of epoch 3 | time: 1966.75s | valid loss 4.25 | valid ppl 70.38
-----------------------------------------------------------------------------------------
...중략...
| end of epoch 47 | time: 1973.69s | valid loss 2.79 | valid ppl 16.26
-----------------------------------------------------------------------------------------
| end of epoch 48 | time: 2076.40s | valid loss 2.77 | valid ppl 16.00
-----------------------------------------------------------------------------------------
| end of epoch 49 | time: 2080.24s | valid loss 2.79 | valid ppl 16.26
-----------------------------------------------------------------------------------------Ko-En Translation Result
- 번역의 성능은 예상보다 뛰어나지는 않았습니다.
- 학습데이터를 10000개, 220000개 정도로 나누어 학습했을때, 학습데이터가 많은 경우 수렴을 더 잘하는것을 볼수 있었습니다.
- 더 많은 데이터 및 언어모델로 추가 학습해본다면 성능 개선이 가능한 부분입니다.
ko: 나는 먹고 자기만 했어요. en: I just had a lot of things.
------------------------------------------------------
ko: 나는 먹기 위해 운동했어요. en: I exercised to eat.
------------------------------------------------------
ko: 나는 먹을 음식을 좀 샀습니다. en: I bought some food.
------------------------------------------------------
ko: 나는 아침으로 매일 토스트를 만들어 먹어. en: I eat breakfast every morning.
------------------------------------------------------
ko: 당신이 노래부르는 영상을 보고싶어요 en: I singing videos and watched the song.
------------------------------------------------------
ko: 대단히 미안하지만 오늘 회의가 있어서 수업에 늦을것 같아요. en: I'm sorry but I am sorry but I am sorry but I am sorry.
------------------------------------------------------
ko: 당신이 준 장미는 향기로워요. en: I'm very happy to see you.
------------------------------------------------------
ko: 당신이 제일 많이 생각하는 게 무엇인가요? en: What is the most important thing you think?
------------------------------------------------------
ko: 가정집을 개조한 분위기 좋은 레스토랑이 있습니다. en: There is a good restaurant to be a good restaurant.
------------------------------------------------------
ko: 가난뱅이인 제가 당신을 어떻게 사랑할 수 있습니까? en: How can I love you and love you?마무리
위와 같이 트랜스포머를 직접 작성해보고 기계번역 태스크에 대해 학습해보면서 트랜스포머 모델에 대해 보다 깊게 이해할 수 있었습니다. 추후에는 트랜스포머를 개선한 모델들에 대해 직접 작성해보고, 기존에 트랜스포머가 가지고 있던 단점들을 개선해보도록 하겠습니다.
추후 개선사항으로는 BLEU 스코어를 통한 기계번역의 평가 부분 개선이 있겠습니다.

안녕하세요, 사용하신 파이썬 버전과 코랩에서 모델 실행시 자세한 코드 알 수 있을까요?