Segmentation과 RCNN 모델을 통한 종이 시험지 자동 채점 프로그램 | Tensorflow Object Detection API | Ch0. 계획
2021CapstoneDesign

위 사진은 시리즈 배경 등록을 위한 사진입니다.
시작하며
배경
현재 저는 중학생 과외를 진행하고 있으며, 교육과 시험에 관심이 자연스럽게 많아지며 교육분야에서 부족한 부분이 무엇인지 생각해보았습니다. 온라인 교육을 통해 모바일로 문제를 묻고 답하는 플랫폼이 있는가 하면, 태블릿 pc 등을 통해 문제를 풀고 쉽게 채점하도록 하는 공부 어플들이 매우 많이 있었습니다.
여기서 저는 너무 온라인을 통한 교육만을 추구하고 있는 것은 아닌지, 아직까지는 종이 시험지를 통해 시험을 치고 문제를 푸는 개인과 학원과 같은 단체가 대부분일 것이란 것을 짚고 넘어가야한다고 생각했습니다. 그러나 현재 온라인을 통한 교육이 매우 편리하고 점점 더 많아지는 추세라는 것은 부정할 수 없기 때문에, 종이 시험지를 통한 교육방식에서 어떤 것이 추가가 되면 더 편리해질지를 생각해보았습니다.
주제
종이시험지를 직접 손으로 매기지 않고 한번에 인식하여 어떤 답을 선택했는지를 알려주는 프로그램을 만든다면, 기기를 통해 문제를 풀지 않아도 자동으로 채점해줄 수 있게 됩니다. 그래서 저는 이번 캡스톤 디자인 수업을 통해 종이 시험지 자동 채점 프로그램을 만들기로 했습니다.
Flow
- 다 푼 종이 시험지 찍어 프로그램에 입력합니다.
- 각 문제에 대해 사용자가 몇번을 선택했는지 출력합니다.
- 정답과 맞는지 확인합니다.
데이터 정의 및 준비
데이터 수집
풀려 있는 시험지 데이터가 필요합니다. 사용자는 자신이 푼 시험지를 직접 찍어 업로드 하므로, 학습데이터는 다양한 밝기과 각도, 노이즈가 설정되어 있어야 합니다.
데이터 늘리기
수집하게 될 데이터는 pdf 파일로, 밝기나 각도의 영향을 받지 않은 매우 깨끗한 시험지 데이터 입니다. 따라서 data augmentation 을 통해 각도와 밝기를 조절하고, 노이즈 필터를 통해 학습데이터를 증강합니다.
데이터 정의(분류단계) / 라벨링
새롭게 정의한 주제이기 때문에 분석 목표에 맞게 직접 라벨링해야합니다. CVAT 와 Labelme 툴을 사용할 예정입니다.
분류 1단계
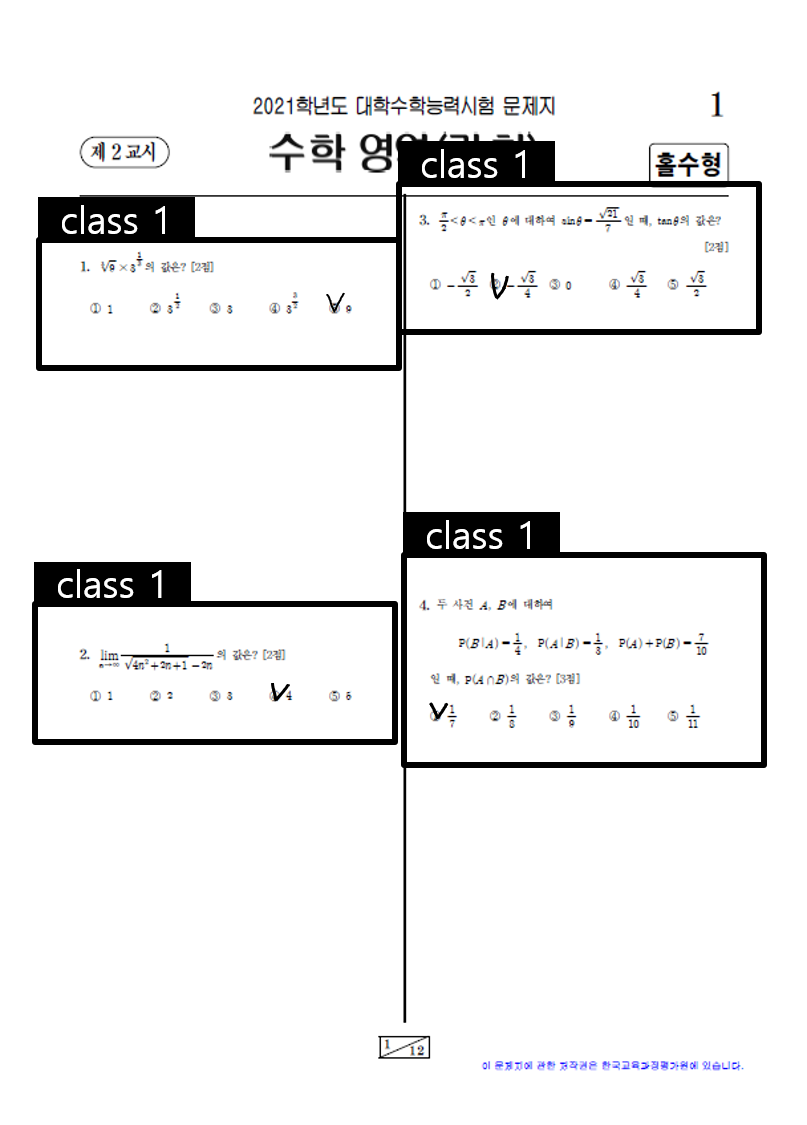
문제 분류 : 이미지 데이터 속 문제가 어떤 위치에 있는지 네모 박스로 라벨링 합니다.
분류 2단계
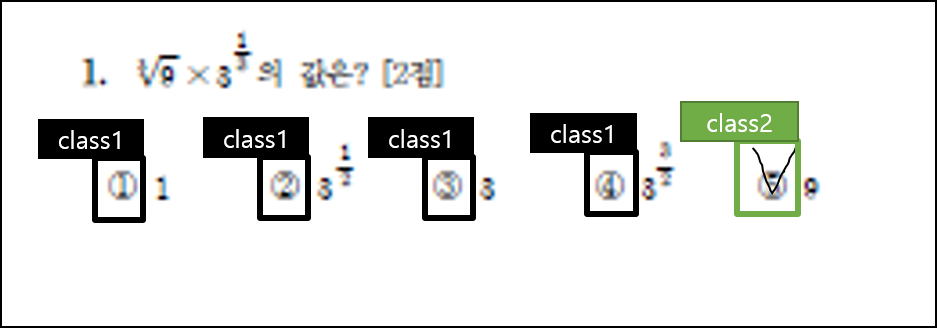
항목 분류 : 선택되지 않은 답과 선택한 답 두개의 클래스로 항목을 라벨링합니다.
모델 학습 과정
문제 분류하기
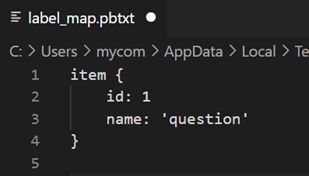
앞서 라벨링 했던 이미지를 TFRecord 파일로 저장합니다. 이는 Tensorflow를 통한 모델 학습을 위한 시간 절감과 효율성을 위한 것입니다. 또한 라벨을 정의하기 위해 pbtxt 파일로 Labelmap을 함께 저장해둡니다.
이 두개의 파일을 통해 Tensorflow Object Detection API를 통해 미리 학습된 모델을 사용하여 학습합니다. 자세한 내용은 추후에 실제로 구현하게 될 때 작성하겠습니다.
항목 분류하기
선택하지 않은 항목과 선택한 항목을 분류하는 과정입니다. 이것 또한 앞서 라벨링 된 이미지를 TFRecord와 pbtxt로 저장하여 라벨링 범위와 클래스를 정의합니다.
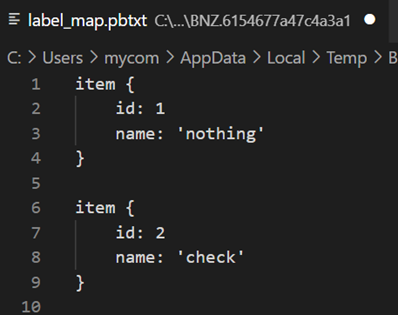
이때는 두개의 클래스로 학습이 진행되며 문제 분류하기 단계에서와 동일하게 Tensorflow Object Detection API에서 제공되는 미리 학습된 모델을 사용할 계획입니다.
모델 평가 과정
학습과정에서의 두단계에서 각각 다른 모델을 사용하고 fit하게 되므로 따로 모델을 평가하게 됩니다. detection 된 상자 안이 얼마나 실제 범위와 겹쳐졌는지, 그 정도를 파악하여 정확도를 확인합니다. 그 정도를 퍼센트(%)로 나타내고 임계값에 따라 TP, FN, FP를 확인하게 됩니다. 그것을 통해 Precision 과 Recall 를 사용해 정확도를 파악할 예정입니다.
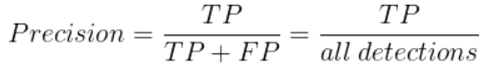
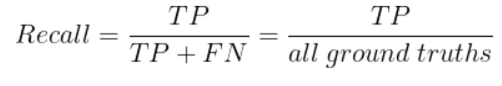
예를 들어, 학습과정에서의 두번째 단계였던 항목을 분류하는 단계에서는, 모델이 얼마나 선택한 답을 많이 골라냈는 지 보다, 선택한 답이라고 한 것 중 실제로 선택한 답인 것이 더 중요하기 때문에 Recall를 사용한다거나 하는 방식입니다.
모델 예측 과정
먼저 사용자가 채점할 시험지를 촬영해 입력합니다.

그다음, 더 높은 정확도로 문제를 검출하기 위해 배경과 분리하는 작업을 거칩니다. 이 단계에서 segmentation을 사용할 예정이며, 앞에서 사용했던 네모 범위 detection과 달리 물체의 윤곽선을 따라 검출하므로 배경을 좀 더 세밀하게 crop하기에 용이합니다.
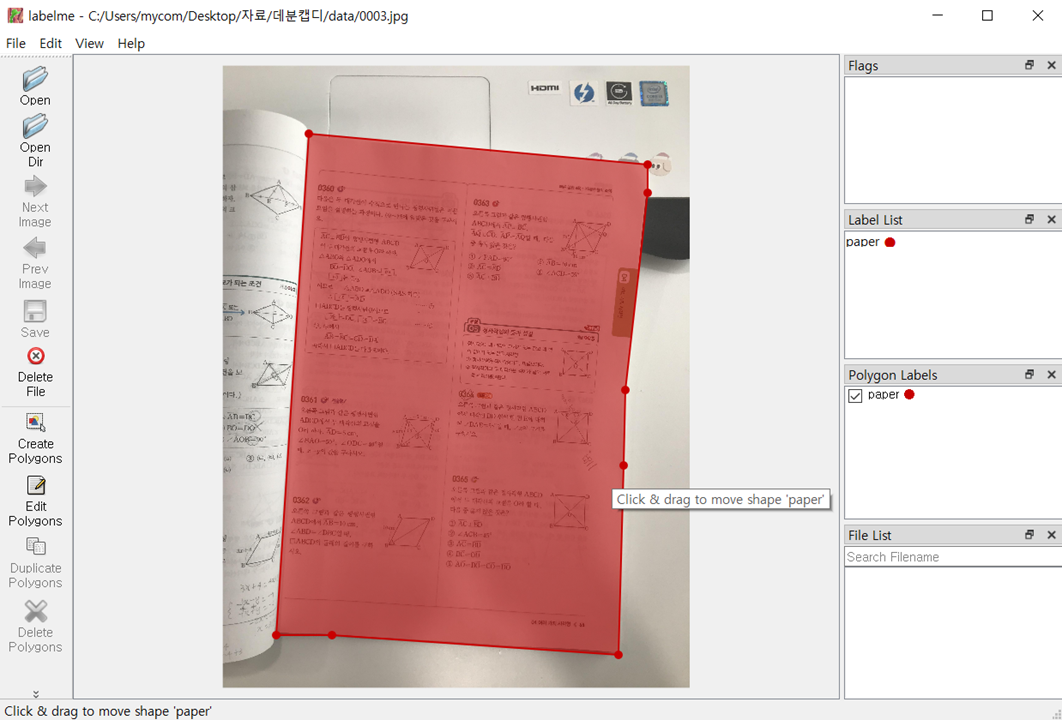
bounding box가 아닌, 문제지 상황과 크기에 맞춰 다각형으로 라벨링 하게 되며, 이것을 Pytorch 에서 제공하는 Detectron2를 통해 학습하게 됩니다. 이때 사용할 모델은 Mask R-CNN 이며 이를 통해 마스크 이미지를 얻어 이미지를 잘라내게 됩니다. 자세한 내용은 실제 구현 단계에서 작성하겠습니다.

배경을 잘라낸 후 앞에서 학습된 문제 분류 모델을 통해 예측을 진행합니다.
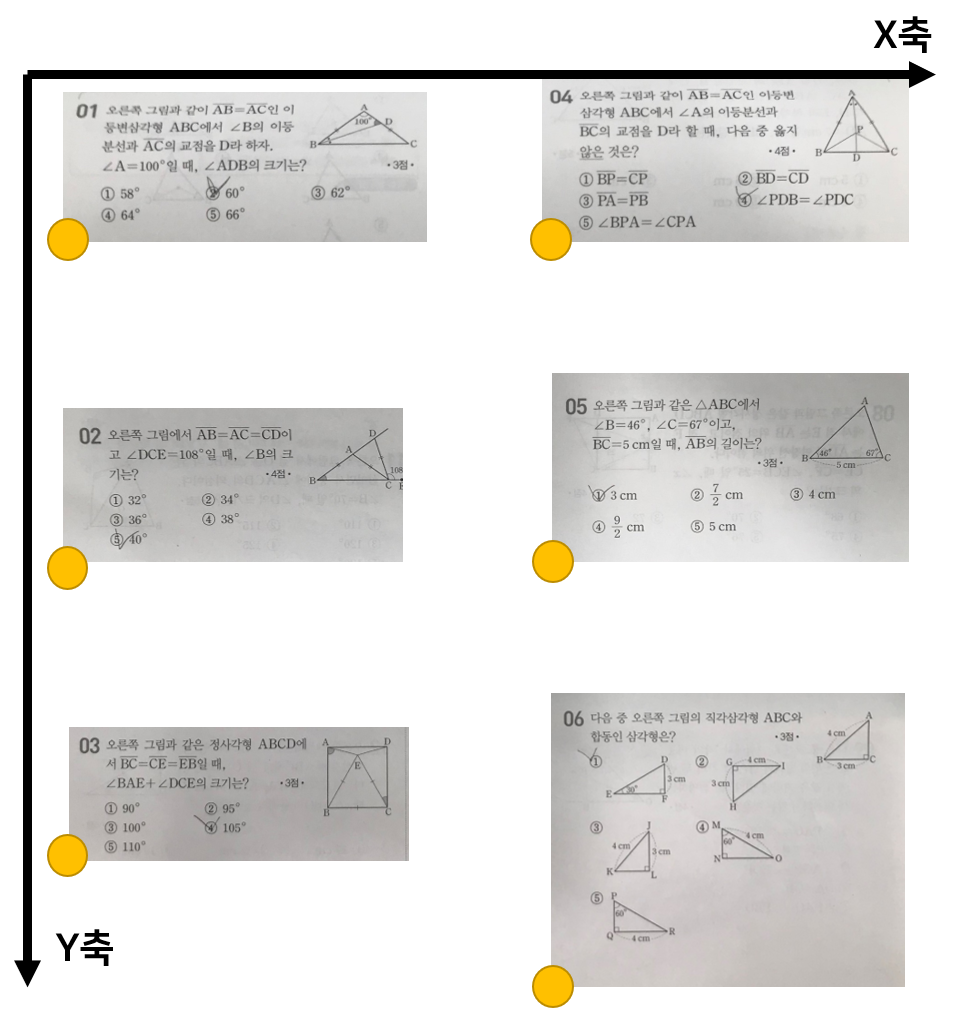
감지된 문제를 자르게 되고, 문제들에 대한 번호를 매기기 위해 좌표로 순서를 파악하게 됩니다. 이 프로그램에서 대상으로 하는 것은 시험지 이므로 두단락, 세로로 구성되어 있음을 고려하여 파악합니다.
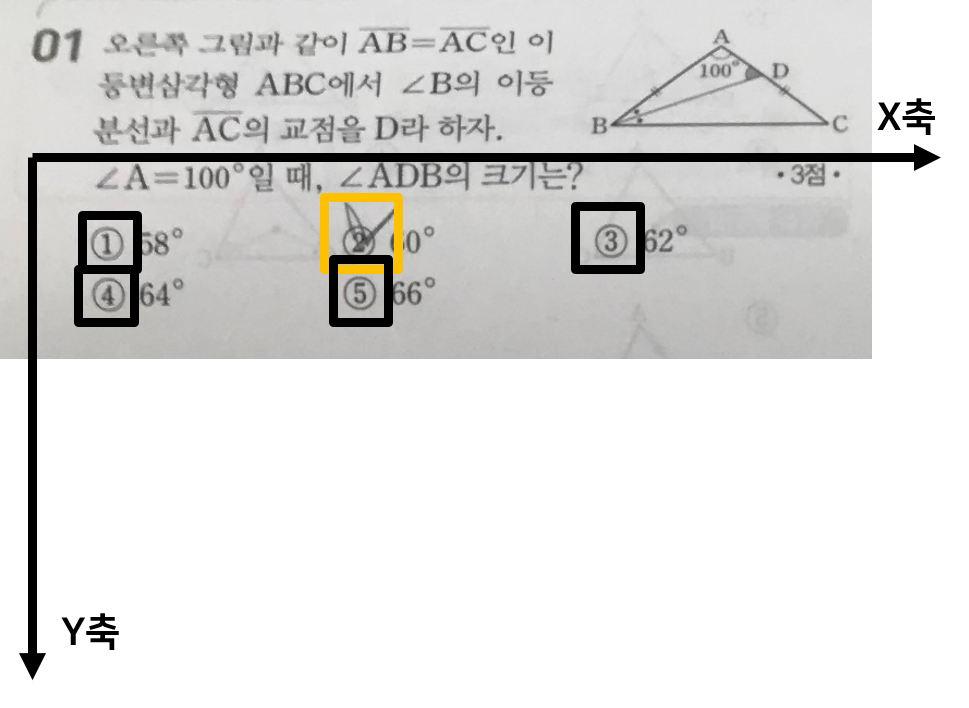
자른 문제들을 각각 확인하며 항목 분류 모델을 통해 예측하게 되고, 위 그림과 같이 선택한 답과 선택하지 않은 답 두가지로 각 항목을 분류하게 됩니다. 이 것 또한 좌표를 통한 위치를 파악하여 각 box가 몇번 항목을 의미하는 지를 파악합니다.
그러나 이때는, 문제와 다르게 총 네가지 패턴을 가지게 됩니다. 첫째로, 항목이 가로로 쭉 나열된 경우와, 두번째로, 세로로 쭉 나열된 경우, 세번째로 두줄로 항목들이 나열된 경우, 마지막으로 세줄로 항목들이 나열된 경우입니다. 이 네가지 패턴 중 어떤 것에 해당하는 지를 이 단계에서 파악해야 하며 그것을 파악하는 알고리즘을 제대로 개발하는 것이 이번 프로젝트의 완성도를 높이기 위한 핵심이라 생각합니다.


마지막으로 각 문제 별로 어떤 답을 선택했는지 출력을 하게 되고 프로그램을 종료됩니다.
마치며
처음으로 해야할 과제는 데이터를 수집하는 것이며, 앞으로의 수행 과정을 블로그에 업로드 하며 정리해나갈 예정입니다.
